📝 Paper Summary
LLMs for Tabular Data
Tree-based Models
Neuro-symbolic Learning
DeLTa enhances decision tree ensembles by using an LLM to synthesize a refined logical rule from tree paths, which then guides a gradient-based error correction module to calibrate predictions.
Core Problem
Existing LLM-for-tabular methods rely on serializing data into text, which often fails for anonymized features, risks privacy exposure, and struggles with numerical values.
Why it matters:
- Many real-world datasets (e.g., finance) use anonymized headers, breaking methods that rely on semantic column names
- Directly feeding row data to LLMs exposes sensitive information in privacy-critical fields like healthcare
- Fine-tuning LLMs on tabular data is computationally expensive and often limited to few-shot scenarios due to context length constraints
Concrete Example:
A financial dataset might have column 'V1' instead of 'Income'. A serialization method like TabLLM producing 'The V1 is 5000' fails because the LLM lacks semantic context for 'V1', whereas a decision tree rule 'V1 > 3000' captures the structural logic directly.
Key Novelty
Decision Tree Enhancer with LLM-derived Rule (DeLTa)
- Instead of feeding data samples to the LLM, DeLTa feeds *decision tree rules* (logic) to the LLM.
- The LLM acts as a meta-reasoner to summarize diverse, potentially conflicting rules from a Random Forest into a single, higher-quality refined rule.
- This refined rule partitions the data into leaf nodes where a lightweight 'Gradient Net' learns to predict error correction vectors, calibrating the original ensemble's output.
Architecture
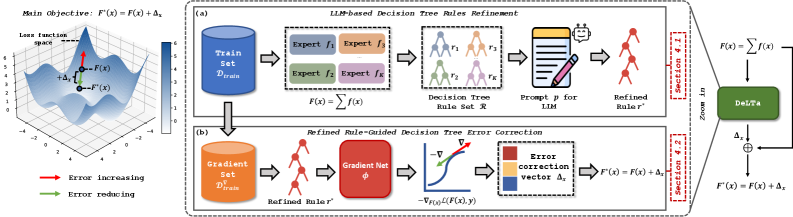
The overall framework of DeLTa.
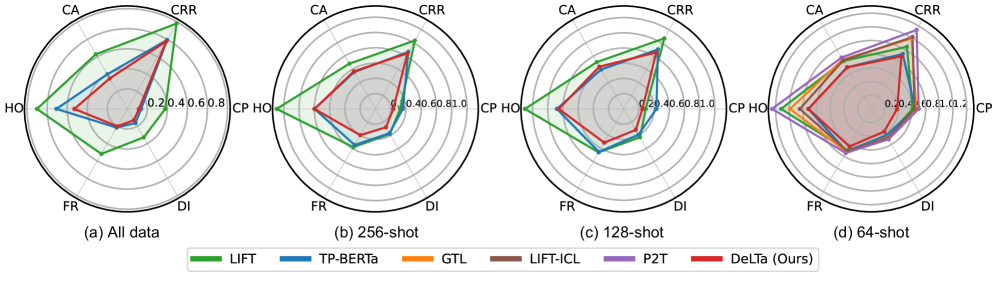
Evaluation Highlights
- Achieves state-of-the-art performance on 22 diverse tabular benchmarks compared to both traditional tree methods (XGBoost, CatBoost) and deep learning methods (FT-Transformer).
- Demonstrates lower intra-node sample distance (better grouping) using LLM-refined rules compared to original decision tree rules.
- Effective in full-data learning settings without requiring any LLM fine-tuning, unlike prior LLM-tabular works restricted to few-shot or classification-only tasks.
Breakthrough Assessment
8/10
Novel approach that sidesteps the serialization bottleneck by operating on logic (rules) rather than raw data. Solves key privacy and scalability issues in LLM-tabular integration.