📝 Paper Summary
Modularized RAG pipeline
InfoGain-RAG introduces a metric called Document Information Gain (DIG) to quantify how much a retrieved document increases an LLM's confidence in the correct answer, training a reranker to filter and sort documents accordingly.
Core Problem
Current RAG frameworks struggle to identify whether retrieved documents actually contribute to correct answer generation, often retrieving irrelevant or misleading content based solely on semantic similarity.
Why it matters:
- Semantic similarity does not equate to utility; high similarity documents can still be unhelpful or distracting for the generation task
- Existing rerankers (like BGE) focus on fine-grained semantic matching rather than the downstream impact on generation quality
- Self-reflection methods that do assess utility require multiple expensive LLM calls, making them computationally impractical for real-time applications
Concrete Example:
A document might be semantically similar to a query about a movie plot but contain outdated or slightly incorrect details. A standard reranker prioritizes it due to keyword overlap, confusing the generator. InfoGain-RAG would score it negatively if it lowers the model's confidence in the true answer compared to using no document.
Key Novelty
Document Information Gain (DIG) Metric & Multi-Task Reranker
- Defines a metric (DIG) that calculates the difference in an LLM's confidence for the ground-truth answer when a specific document is present versus absent
- Trains a lightweight reranker using a multi-task objective: classifying whether a document provides positive/negative gain and ranking documents by their gain magnitude
Architecture
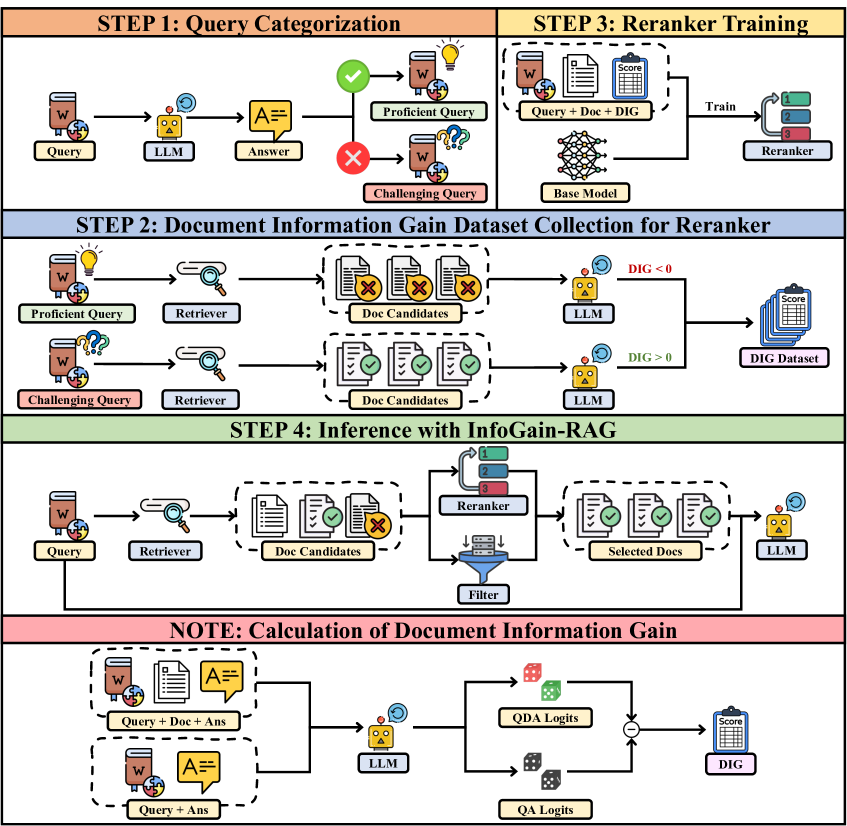
The complete pipeline of InfoGain-RAG, including the data collection process (calculating DIG) and the inference phase with the trained reranker.
Evaluation Highlights
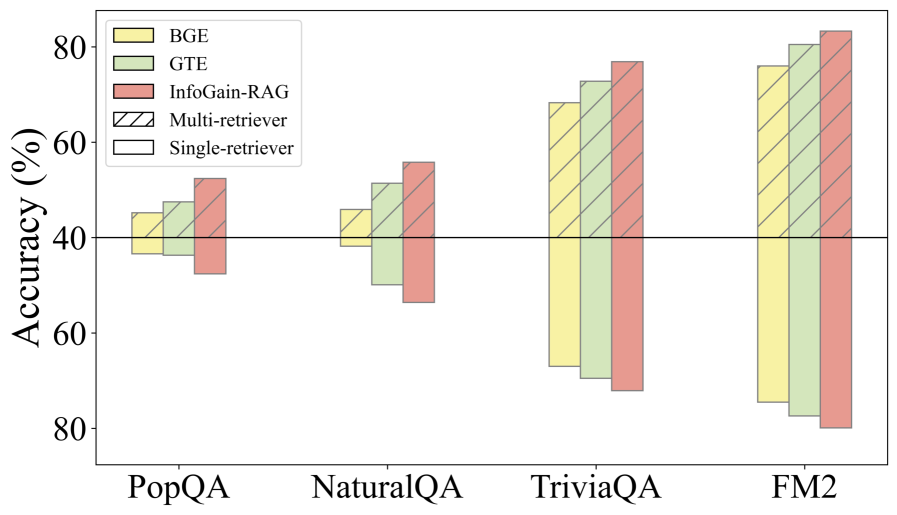
- +17.9% Exact Match improvement on NaturalQA using LLaMA-3.1-405B compared to naive RAG
- Outperforms the state-of-the-art proprietary reranker GTE-7B by 3.4% on NaturalQA despite being 20x smaller (335M parameters)
- Achieves 83.4% accuracy on Fact Verification (FM2) with Qwen2.5-72B, compared to 73.6% for naive RAG
Breakthrough Assessment
8/10
Significant performance jumps over both naive RAG and massive state-of-the-art rerankers (GTE-7B) using a much smaller, efficiently trained model. The metric directly aligns retrieval with generation success.