📝 Paper Summary
Multi-Agent Reinforcement Learning (MARL)
Hierarchical Reinforcement Learning
Air Combat Simulation
A hierarchical multi-agent framework adapts Simple Policy Optimization (SPO) to train heterogeneous aircraft teams in realistic dogfights, using low-level maneuver policies guided by high-level tactical commanders.
Core Problem
Realistic air combat involves high-dimensional, nonlinear flight dynamics and partial observability, making it difficult for standard 'flat' RL policies to simultaneously master precise control and high-level strategy.
Why it matters:
- End-to-end RL often fails to converge in complex physics environments like JSBSim due to the difficulty of learning control and tactics simultaneously
- Existing air combat simulations often simplify physics (3-DOF) or use homogeneous agents, limiting applicability to real-world defense scenarios involving diverse aircraft types
- Standard algorithms like PPO (Proximal Policy Optimization) may be less sample-efficient or stable than newer approaches like SPO in these high-stakes control domains
Concrete Example:
In a 10-vs-10 engagement, a non-hierarchical (flat) agent attempts to map raw observations directly to throttle/stick inputs. It fails to learn effective strategies, achieving a 0% win rate, whereas the hierarchical approach decomposes the task into tactical decisions (e.g., 'Engage') and execution.
Key Novelty
Hierarchical Heterogeneous Multi-Agent RL (HHMARL) with MA-SPO
- Decomposes decision-making into two levels: High-level commanders issue discrete tactical orders (Attack, Engage, Defend), while low-level policies execute continuous flight maneuvers
- Adapts Simple Policy Optimization (SPO) to the multi-agent domain (MA-SPO) using Centralized Training and Decentralized Execution (CTDE)
- Integrates a curriculum learning pipeline with league-play to progressively train heterogeneous agents (F16 and A4 aircraft) from basic maneuvers to complex team coordination
Architecture
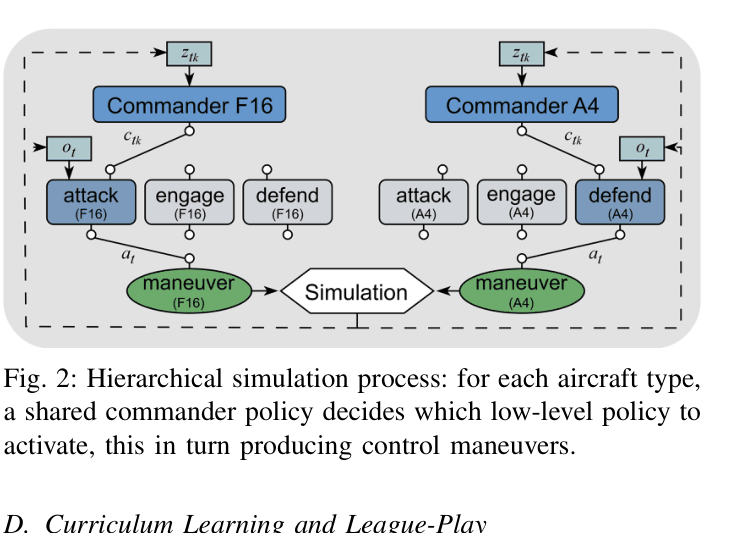
The hierarchical decision-making process for F16 and A4 agents.
Evaluation Highlights
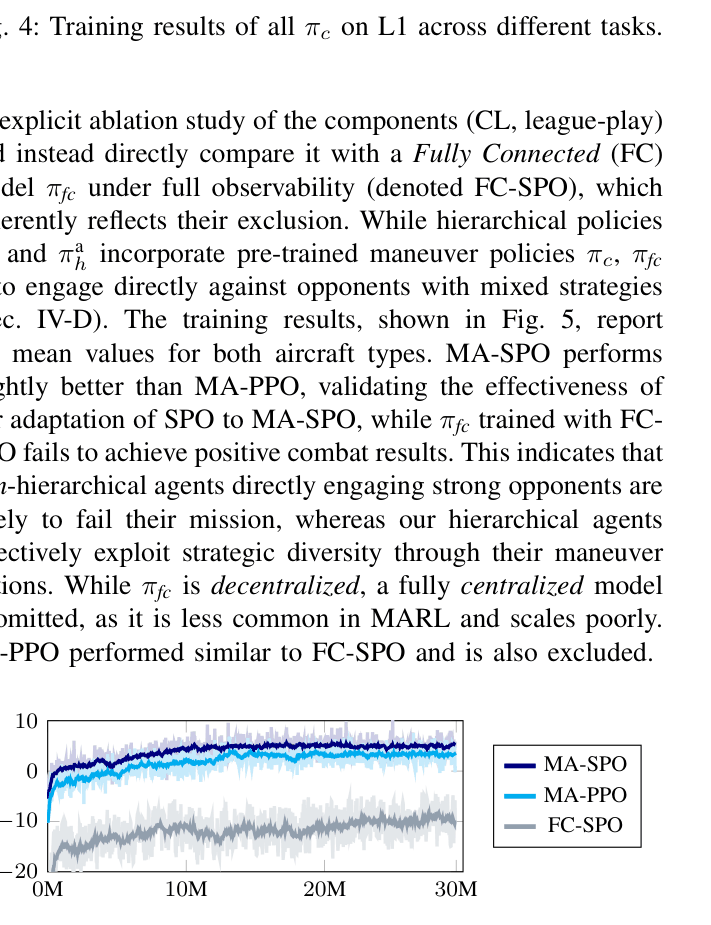
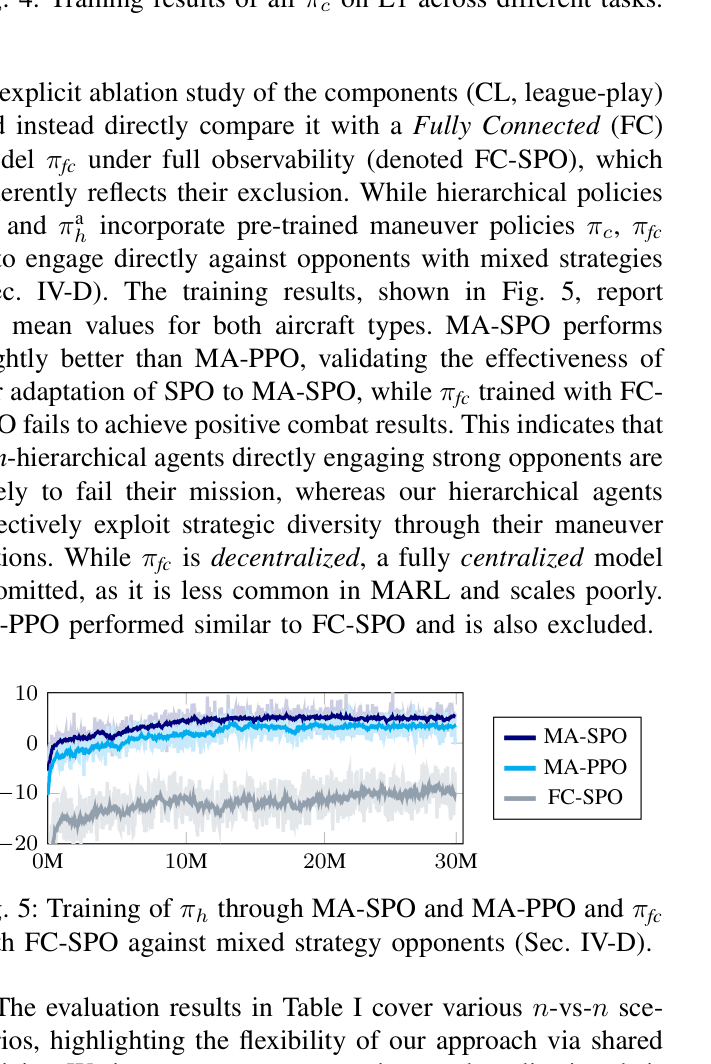
- Achieved 90% win rate in 3-vs-3 scenarios using MA-SPO, outperforming MA-PPO (88%) and completely dominating non-hierarchical baselines (0%)
- Maintained >80% win rate in large-scale 10-vs-10 battles (83% for MA-SPO), demonstrating scalability where flat policies failed entirely
- MA-SPO low-level policies achieved higher mean rewards and faster convergence than PPO and SAC (Soft Actor-Critic) in 1-vs-1 dogfight training
Breakthrough Assessment
7/10
Strong engineering application combining realistic physics (JSBSim) with a novel algorithm adaptation (MA-SPO). While the hierarchy concept is established, the successful integration with heterogeneous agents and league-play in a high-fidelity sim is significant.