📝 Paper Summary
Agent Evolution
Memory Organization
Memento enables LLM agents to continuously adapt and improve on deep research tasks via a growing episodic memory and a learned case-retrieval policy, eliminating the need for expensive parameter fine-tuning.
Core Problem
Current LLM agents either rely on rigid, static workflows that cannot adapt, or require computationally expensive fine-tuning (SFT/RL) to update model parameters, which is inefficient for open-ended continuous learning.
Why it matters:
- Continuous adaptation is essential for generalist agents in changing environments, but frequent retraining is cost-prohibitive
- Static prompting strategies fail to incorporate online feedback from successes and failures
- Existing memory systems often suffer from retrieval swamping without selective curation mechanisms
Concrete Example:
In a deep research scenario, an agent might fail a complex web-search task. A standard agent repeats the mistake or requires a full model update to learn. Memento stores the failure trace in memory; when a similar task appears, it retrieves the failure case to guide the planner away from the previous error.
Key Novelty
Memory-augmented MDP with Neural Case-Selection Policy
- Formalizes agent planning as a Memory-augmented MDP where the state includes both the environment status and a retrieval-based case bank
- Optimizes a 'case retrieval policy' using online reinforcement learning (Soft Q-Learning) to select the most useful past experiences (successes or failures) for the current context
- Updates the retrieval mechanism (Q-function) rather than the LLM parameters, allowing the agent to 'learn on the fly' by curating its episodic memory
Architecture
The dual-stage architecture of Memento, alternating between Case-Based Planning and Tool-Based Execution.
Evaluation Highlights
- Attains top-1 on GAIA validation with 87.88% Pass@3 and 79.40% on the private test leaderboard
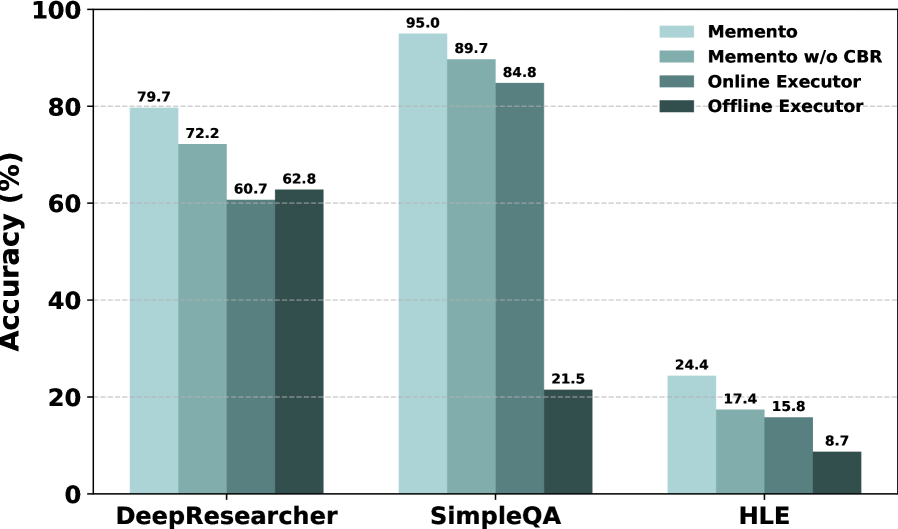
- Outperforms state-of-the-art training-based methods on DeepResearcher dataset, achieving 66.6% F1 and 80.4% PM
- Case-based memory adds 4.7 to 9.6 absolute percentage points on out-of-distribution tasks compared to baselines
Breakthrough Assessment
9/10
Achieves SOTA on the challenging GAIA benchmark without fine-tuning, offering a scalable, non-parametric alternative to costly agent training. The formalization of retrieval as an RL policy over memory is a significant methodological advance.