📝 Paper Summary
Agentic tool use
Dynamic tool selection
AutoTool enables agents to select tools from dynamic, large-scale libraries by mapping tool selection to a continuous embedding space and optimizing choices via Plackett-Luce ranking.
Core Problem
Existing agents rely on fixed, predefined tool inventories, causing them to overfit to specific domains and fail when facing new or evolving toolsets at inference time.
Why it matters:
- Real-world environments have dynamic tool libraries where new APIs are constantly added, breaking agents trained on static sets
- Current methods treat tool selection as classification over a closed set, preventing generalization to unseen tools
- Without dynamic selection, agents cannot scale to complex, domain-diverse environments requiring thousands of potential tools
Concrete Example:
An agent trained only on a basic calculator tool fails when asked a question requiring a newly added 'WolframAlpha' tool at inference time because the new tool was not in its fixed classification output space during training.
Key Novelty
Embedding-Anchored Tool Selection with Plackett-Luce Optimization
- Replaces static classification with 'embedding-anchored' selection: the agent generates an anchor token, and the system retrieves the tool whose embedding is closest to this anchor in a shared latent space.
- Models the selection process using Plackett-Luce (PL) ranking, effectively training the agent to rank useful tools higher based on trajectory rewards rather than just memorizing tool IDs.
Architecture
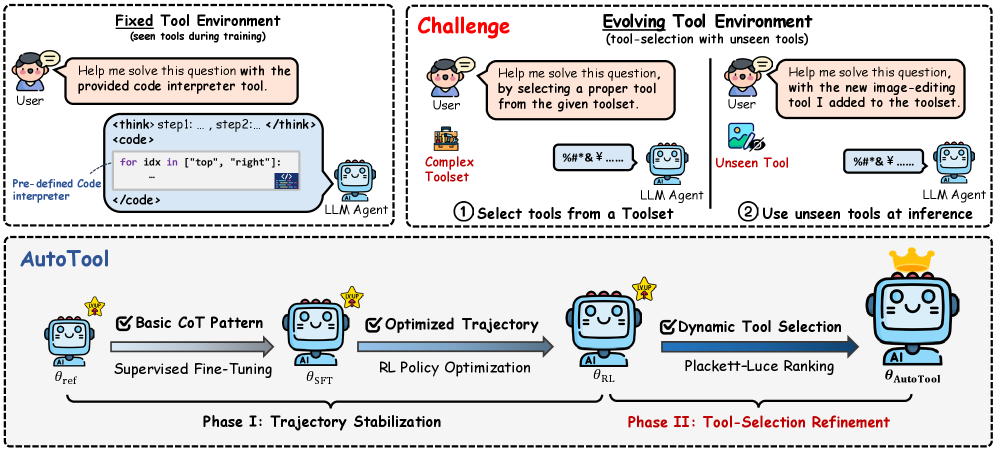
Overview of the AutoTool framework, illustrating the interaction between the LLM agent and the evolving toolset.
Evaluation Highlights
- Average performance gain of 6.4% in math & science reasoning tasks compared to baselines (SFT/GRPO) using Qwen3-8B and Qwen2.5-VL-7B backbones
- Achieves 7.7% average improvement in code generation tasks by dynamically selecting appropriate coding tools
- Demonstrates 6.9% average gain in multimodal understanding tasks, effectively leveraging visual tools like OCR and GroundingDINO
Breakthrough Assessment
8/10
Addresses a critical bottleneck in agentic AI (fixed vs. open toolsets) with a theoretically grounded ranking approach (Plackett-Luce) and demonstrates significant gains across diverse domains.