📝 Paper Summary
Biomedical LLM Training
Synthetic Data Generation
m-KAILIN is a multi-agent framework that autonomously distills high-quality biomedical QA pairs from scientific literature by using MeSH-guided evaluation to train agents without human annotation.
Core Problem
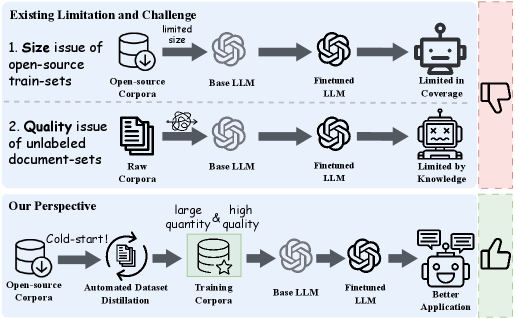
Biomedical LLM training is bottlenecked by the scarcity of high-quality, annotated QA corpora, as raw scientific literature is unstructured and complex.
Why it matters:
- General-purpose LLMs struggle with specialized biomedical tasks without domain-specific fine-tuning.
- Existing rule-based or knowledge-graph methods are resource-intensive and hard to scale.
- Prior synthetic data methods lack interdisciplinary collaboration and mechanisms to ensure alignment with biomedical ontologies.
Concrete Example:
A standard LLM might generate a generic question from a paper that misses critical medical nuances. Without m-KAILIN's MeSH-guided evaluation, the model cannot distinguish between a medically precise context and a tangentially related one, leading to hallucinations or irrelevant training data.
Key Novelty
Multi-agent enhanced Knowledge hierarchy guided biomedical dataset distillation (m-KAILIN)
- Uses a collaborative multi-agent architecture where distinct agents handle question generation, context retrieval, and answer generation.
- Introduces a 'cold-start' evaluation agent guided by the Medical Subject Headings (MeSH) hierarchy to automatically label preference data without human input.
- Employs Direct Preference Optimization (DPO) to refine the question generator using the automatically generated preference data.
Architecture
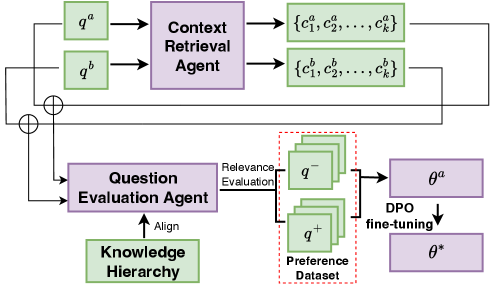
The m-KAILIN framework workflow, illustrating the interaction between Question Generation Agents, Context Retrieval, and the Evaluation Agent.
Evaluation Highlights
- Llama3-70B trained on m-KAILIN data outperforms GPT-4 with MedPrompt on biomedical QA tasks.
- Generated dataset enables models to surpass Google's Med-PaLM-2 despite smaller model scales.
- The framework distills data from over 23 million biomedical research articles.
Breakthrough Assessment
8/10
Significant for enabling smaller open models (Llama3) to beat proprietary giants (GPT-4, Med-PaLM-2) in a specialized domain via automated data distillation, reducing reliance on expensive human annotation.