📝 Paper Summary
Human-AI Collaboration
Sequential Decision Making
Decision Support Systems
This system improves human sequential decision-making by using an AI to restrict available actions to a high-quality subset, optimizing the subset size via a bandit algorithm to balance human and AI agency.
Core Problem
In sequential tasks, humans struggle to know when to cede agency to an AI predictor or exercise their own judgment, often leading to suboptimal reliance on decision support systems.
Why it matters:
- Conventional decision support requires human experts to incorrectly estimate their own uncertainty versus the AI's uncertainty to achieve complementarity.
- Full automation (AI-only) fails to leverage salient, hard-to-quantify information that human experts possess (e.g., qualitative observations in healthcare or disaster response).
- Existing advice-based systems (recommenders) allow humans to ignore advice completely, failing to prevent obvious errors.
Concrete Example:
In a wildfire mitigation game, a human player might choose a burning tile that looks dangerous but is actually low-priority. A standard AI might just recommend one tile, which the human might reject. This system forces the human to pick from the top-3 AI-ranked tiles, preventing a bad choice while allowing the human to use intuition to pick the best among the good options.
Key Novelty
Adaptive Action Sets via Lipschitz Bandits
- Instead of recommending a single action, the system provides an 'action set' (a subset of allowed actions) derived from an AI agent's rankings.
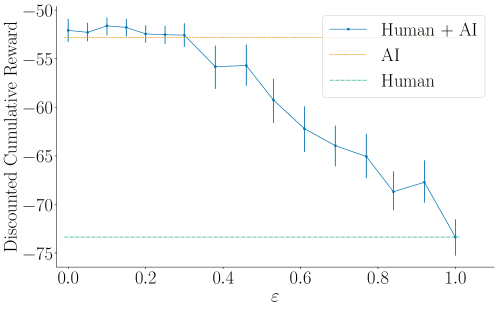
- The size of this set is controlled by a continuous parameter epsilon, which smoothly adjusts the level of human agency (epsilon=0 is AI-only, epsilon=1 is full human control).
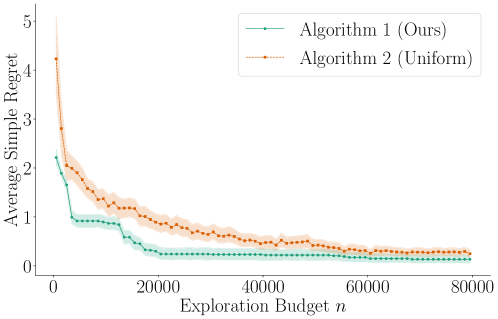
- Uses a novel bandit algorithm that leverages the smoothness (Lipschitz continuity) of the reward function to efficiently find the optimal epsilon during interaction.
Architecture
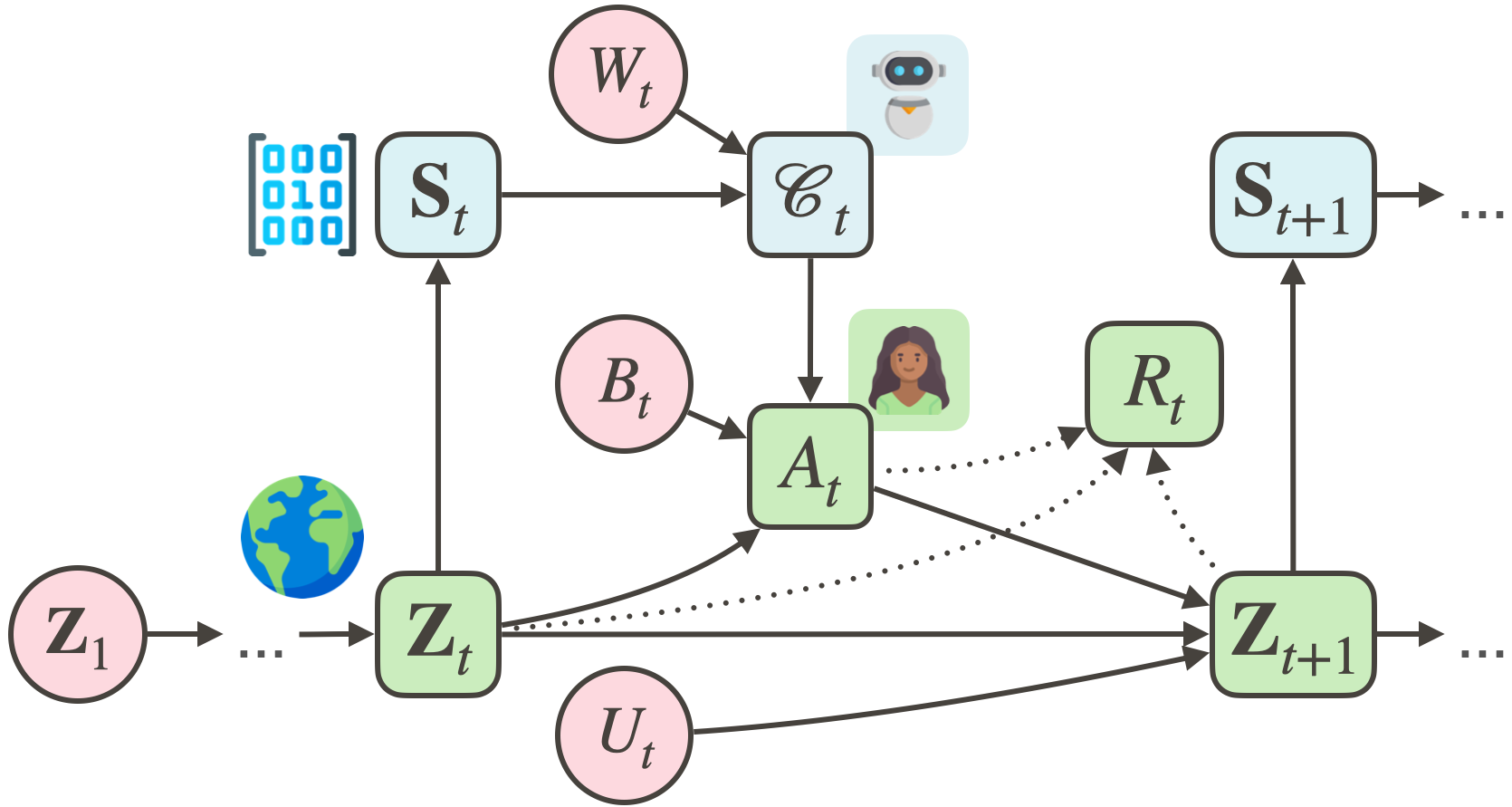
A Structural Causal Model (SCM) visualization of the decision-making process.
Evaluation Highlights
- Humans supported by the system (at optimal agency level) outperform humans playing alone by 29.65% in a wildfire mitigation game.
- The supported humans outperform the standalone AI agent (Deep Q-Network) by 2.31%, demonstrating true human-AI complementarity.
- The proposed Lipschitz bandit algorithm achieves lower simple regret than a uniform discretization baseline given the same exploration budget.
Breakthrough Assessment
8/10
Offers a theoretically grounded and empirically validated method for sequential human-AI complementarity, achieving gains over both human-only and AI-only baselines in a large-scale study.