📝 Paper Summary
Video Understanding
Multimodal Information Extraction
Agentic AI
RAVEN is a model-agnostic agent that dynamically generates domain-specific schemas from video collections to guide vision-language models in extracting structured, multimodal entities.
Core Problem
Current multimodal models typically process videos in isolation, lacking collection-wide understanding and domain-specific structure needed for large-scale retrieval.
Why it matters:
- Video collections in education or entertainment require consistent structured metadata (entities, attributes) which isolated processing fails to provide
- Existing methods lack mechanisms to dynamically define what entities matter for a specific domain (e.g., 'Ingredients' in cooking vs. 'Dates' in history)
- Unimodal baselines (OCR, Speech-to-Text) miss context that requires synthesizing visual, audio, and textual cues
Concrete Example:
In a historical documentary, a standard object detector might label a person as 'Person', while RAVEN, utilizing a history-specific schema, extracts 'Person: Napoleon', 'Role: Emperor', and 'Event: Battle of Waterloo' by synthesizing speech and visual context.
Key Novelty
Two-stage Agentic Schema Generation & Extraction
- First, an agent scans the collection to discover categories and generates a 'schema' (a template of expected entities and attributes) using an LLM
- Second, this dynamic schema is used to prompt a Vision-Language Model (VLM) for the actual extraction, ensuring the model looks for domain-relevant details rather than generic labels
Architecture
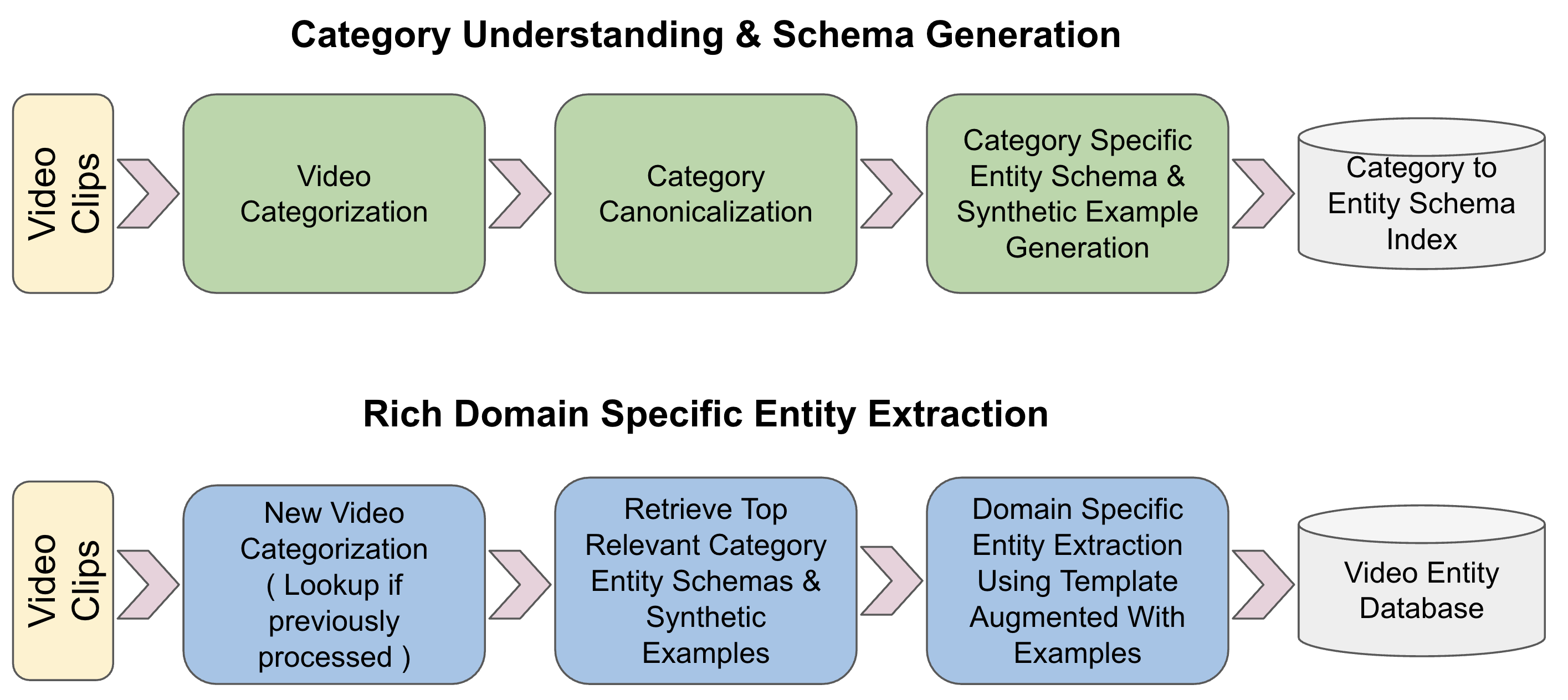
The RAVEN inference pipeline showing the two-stage process: Category Understanding and Rich Entity Extraction
Evaluation Highlights
- Scaled successfully to 1.5 million video clips (>5000 hours) from the Aligned Video Captions dataset for category and schema discovery
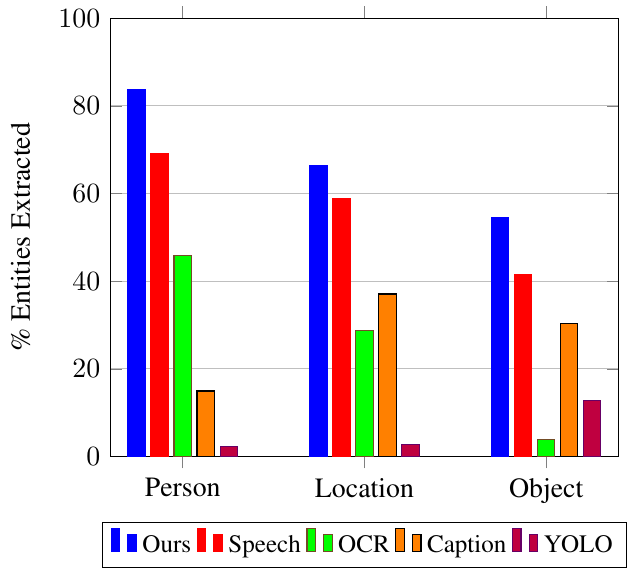
- Qualitatively outperformed unimodal baselines (OCR, Speech NER, YOLO) in extracting rich attributes and relationships (e.g., Person → Role) in a 300-clip benchmark
- Demonstrated ability to dynamically generate distinct schemas for diverse domains like 'How-To' (Ingredients, Tools) vs. 'History' (Figures, Dates) without manual rules
Breakthrough Assessment
7/10
Proposed a practical, scalable agentic workflow for structuring massive video datasets. While it relies on off-the-shelf models, the dynamic schema generation approach effectively bridges generalist VLMs and domain-specific retrieval needs.