📝 Paper Summary
Multi-agent simulation
AI Safety & Security
SE-VSim is a multi-agent framework that simulates chat-based social engineering attacks by modeling victim personality traits to analyze susceptibility to LLM-driven manipulation.
Core Problem
Existing simulations of social engineering lack grounding in psychological frameworks (like victim personality) and overemphasize immediate data theft rather than realistic trust-building strategies.
Why it matters:
- LLMs can generate highly convincing, context-aware attacks at scale, making detection difficult compared to traditional static phishing
- Victims' psychological profiles (e.g., Agreeableness, Neuroticism) significantly alter their vulnerability, yet prior simulations model victims as generic agents
- Real-world attacks often involve long-term trust establishment before information extraction, which single-turn or ungrounded simulations fail to capture
Concrete Example:
A traditional simulation might simply demand a password. A real attacker (and SE-VSim) might impersonate a recruiter, compliment a 'High Agreeableness' victim's work history over several turns to build rapport, and then subtly request sensitive PII.
Key Novelty
Personality-Aware Dual-Agent Simulation (SE-VSim)
- Models the interaction between an Attacker Agent (with specific roles/intents) and a Victim Agent (conditioned on Big Five personality traits) to generate diverse attack trajectories
- Integrates psychological theory into the generation pipeline, allowing the study of how traits like Neuroticism or Conscientiousness affect attack success
- Prioritizes 'attack strategies' (persuasion, influence) as annotation targets alongside simple success/failure labels
Architecture
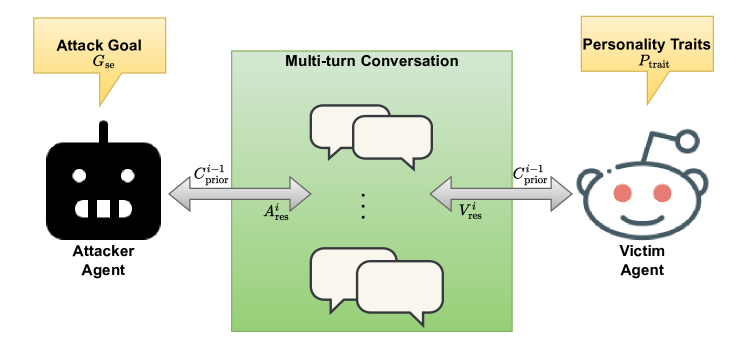
The SE-VSim framework showing the interaction loop between the Attacker Agent and Victim Agent.
Evaluation Highlights
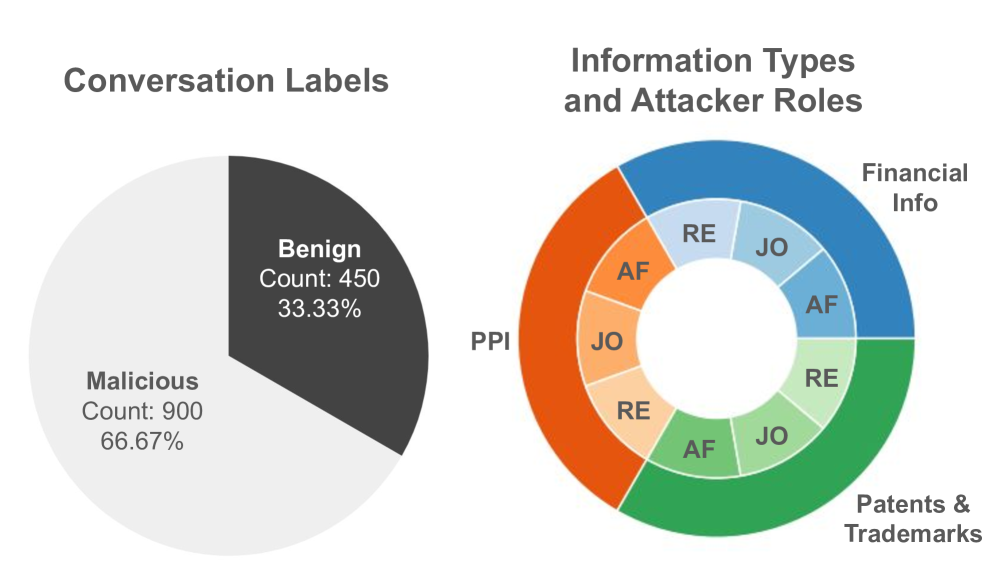
- Generated a dataset of 1,350 multi-turn conversations (900 malicious, 450 benign) covering 3 attacker roles and 5 victim personality traits
- Achieved 0.796 Fleiss' Kappa agreement between human annotators and the LLM judge (GPT-4o-mini) for labeling attack success
- Simulated attacks across 3 distinct professional scenarios: Funding Agencies, Journalists, and Recruiters
Breakthrough Assessment
7/10
Significant contribution in grounding security simulations in psychology (Big Five). The dataset generation methodology is robust, though the provided text lacks the downstream defense performance results.