📝 Paper Summary
Web Agents
Model-Based Reinforcement Learning (MBRL)
World Models
DynaWeb trains web agents by replacing risky live internet interactions with a learned simulator that generates imagined browsing sessions, enabling efficient offline reinforcement learning.
Core Problem
Training web agents via online reinforcement learning is inefficient, expensive, and risky because it requires interacting with the live internet, where mistakes (e.g., unintended purchases) are irreversible.
Why it matters:
- Real-world web interaction is slow and unstable due to network latency and transient failures
- Safety risks like deleting accounts or submitting data make large-scale exploration dangerous
- Existing methods either use world models only for planning (inference-time) or merely for generating static offline data, missing the benefits of active policy optimization
Concrete Example:
An agent learning to buy a product might accidentally complete a purchase during training. In DynaWeb, the agent practices on a simulated 'dream' version of the site where clicking 'buy' only updates the simulated state without charging a credit card.
Key Novelty
Imagination-driven On-Policy RL with Expert Interleaving
- Trains a 'Web World Model' that acts as a simulator: it takes a current web page and an action, then predicts the next page state (accessibility tree) and reasoning trace
- Replaces live web interaction with 'imagined rollouts' generated by this model, allowing the agent to learn from trial-and-error in a safe, synthetic environment
- Interleaves these imagined trajectories with real expert demonstrations during training to stabilize learning and prevent the agent from exploiting model inaccuracies
Architecture
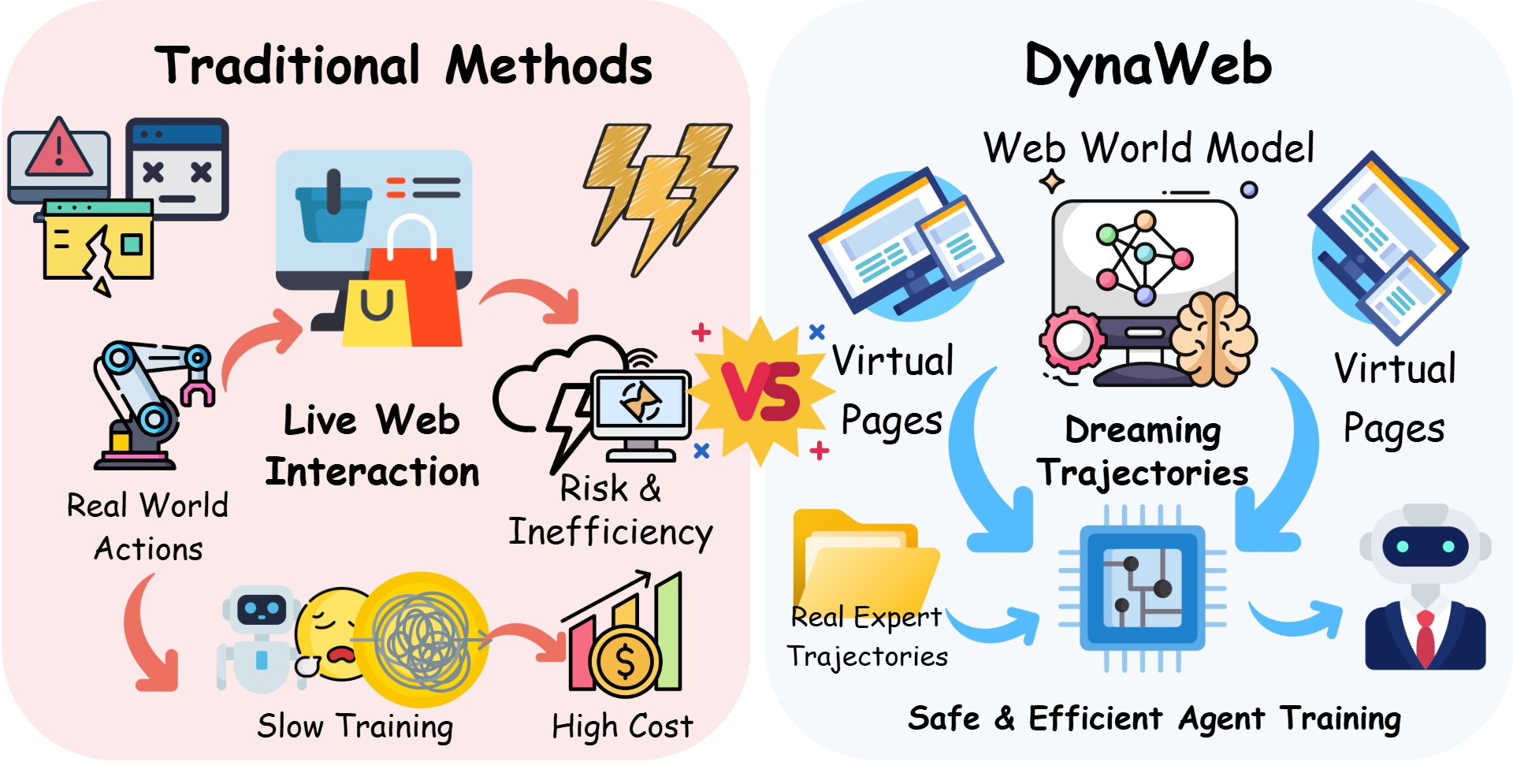
The DynaWeb framework showing the interaction between the Agent Policy and the Web World Model during training.
Evaluation Highlights
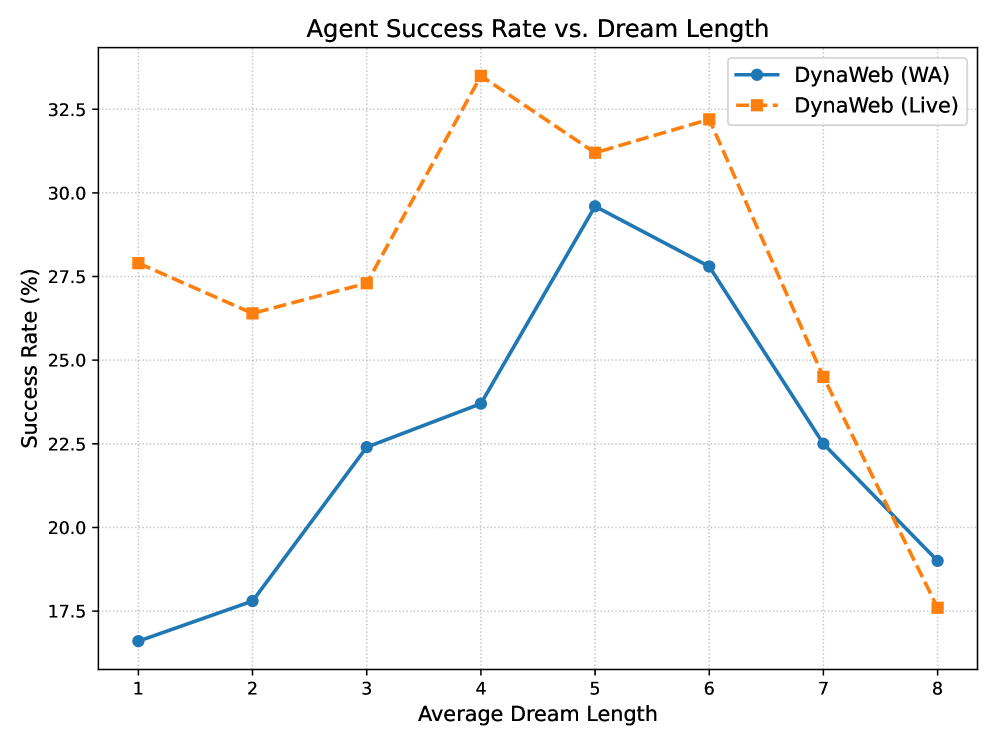
- +17.7% success rate improvement on WebArena using Llama-3-8B-Instruct compared to the base SFT (Supervised Fine-Tuning) model
- +4.3% success rate on WebVoyager compared to stronger baselines like WebAgent-R1, despite using significantly less real-world interaction
- Demonstrates that a 7B parameter world model can sufficiently simulate web dynamics to improve agent policies without live web access
Breakthrough Assessment
8/10
Significant step in making web agent training scalable and safe. Successfully demonstrates that 'dreaming' (MBRL) works for complex web tasks, reducing the dependency on the live internet.