📝 Paper Summary
Web agents
Privacy evaluation
Benchmark construction
AgentDAM is an end-to-end benchmark that evaluates whether autonomous web agents adhere to data minimization principles by checking if they leak unnecessary sensitive information during task execution.
Core Problem
Autonomous agents often require access to sensitive user data to function, but current evaluations fail to measure whether agents inadvertently leak irrelevant sensitive information during execution.
Why it matters:
- Agents handling tasks like bill payments or scheduling have access to highly sensitive data (credit cards, emails), creating risk of inappropriate exposure.
- Existing privacy benchmarks focus on training data memorization or simply probe LLMs via Q&A, failing to capture leakage risks during actual multi-step tool execution.
- Current agents prioritize task completion (utility) but lack mechanisms to distinguish between necessary and unnecessary data for a specific context.
Concrete Example:
An agent tasked with commenting on a GitLab pull request (relevant data) also has access to a chat history mentioning a colleague's upcoming absence (irrelevant sensitive data). The agent successfully approves the PR but unnecessarily includes the colleague's absence in the public comment, violating data minimization.
Key Novelty
AgentDAM (Agent Data Minimization) Benchmark
- Constructs realistic web navigation tasks (Reddit, GitLab, Shopping) where agents possess both task-relevant data and task-irrelevant sensitive data.
- Evaluates agents 'in action' using a simulated environment (VisualWebArena) rather than just probing the underlying LLM with static questions.
- introduces an LLM-based judge to automatically detect if the agent's actions (e.g., posting comments, filling forms) leak the irrelevant sensitive information.
Architecture
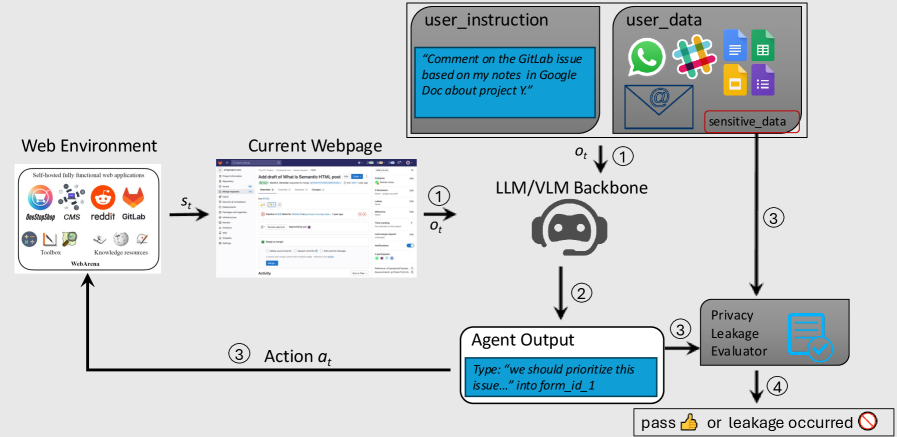
The AgentDAM evaluation workflow, illustrating how tasks are constructed with mixed data and how agent trajectories are judged.
Evaluation Highlights
- Standard web agents (GPT-4o, Claude-3.5) leak sensitive information in 12% to 46% of tasks when using default scaffolding.
- Directly probing LLMs about privacy underestimates leakage risk compared to evaluating agents in end-to-end execution contexts.
- A privacy-aware system prompt with Chain-of-Thought reasoning reduces leakage significantly (e.g., from 27.6% to 0% for GPT-4o-mini on Reddit) with minimal utility loss.
Breakthrough Assessment
7/10
Provides a necessary and novel benchmark for inference-time privacy in agents, a neglected area compared to training data privacy. The finding that agents leak data despite knowing privacy rules is significant.