📝 Paper Summary
LLM Ensembling
Token-level Collaboration
Inference-time Reasoning Enhancement
DDS improves LLM reasoning by dynamically selecting next-token distributions from multiple models based on distribution distance and aligning vocabularies using Minimal Complete Semantic Units (MCSU).
Core Problem
Naive ensemble methods assume more models are better, but weak models can degrade performance, and vocabulary mismatches across different tokenizers make direct probability averaging difficult.
Why it matters:
- Simply adding more LLMs to an ensemble can hurt accuracy if the added models are incorrect or inconsistent (e.g., adding GLM to Qwen+Llama reduces accuracy)
- Vocabulary misalignment prevents direct token-level collaboration because the same word is tokenized differently across models (e.g., 'Llama' vs 'Lla'+'ma')
- Existing alignment methods (projection matrices) introduce noise and computational overhead
Concrete Example:
For a math problem where Qwen and Llama answer correctly but GLM answers incorrectly, a naive ensemble of all three yields the wrong answer. DDS filters out GLM's divergent distribution, retaining only the consistent correct distributions.
Key Novelty
Distribution Distance-based Dynamic Selection (DDS) with Minimal Complete Semantic Units (MCSU)
- Instead of averaging all models, calculate KL divergence between next-token distributions; retain only those close to each other (consensus) and discard outliers
- Define MCSU (Minimal Complete Semantic Unit) as the smallest complete semantic string (e.g., whole words) to naturally align different tokenizers without complex projection matrices
Architecture
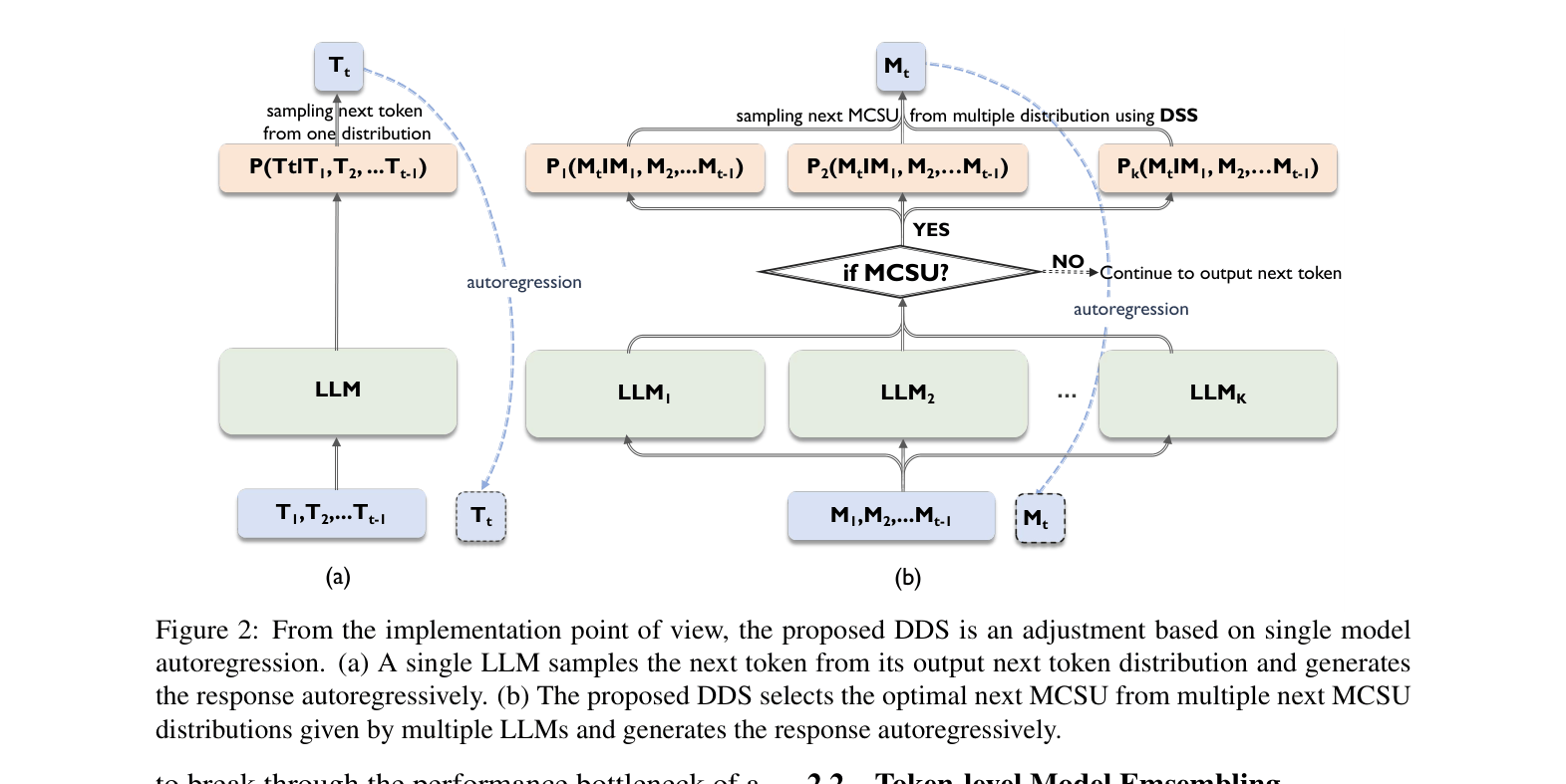
Comparison between single LLM autoregression and the proposed DDS method. It illustrates how multiple LLMs generate next-token distributions, which are then processed via MCSU check and filtered by DDS.
Evaluation Highlights
- +1.3% accuracy improvement on GSM8K using DDS with Qwen/Llama/GLM compared to the best single model (Qwen-2-7B)
- +3.1% accuracy on CommonsenseQA (CSQA) compared to the best single model (Qwen-2-7B), outperforming standard majority voting
- Achieves emergent correctness: DDS answers correctly on specific samples where all three individual component models answer incorrectly (e.g., '300 pages' vs single models' '150' or '75')
Breakthrough Assessment
7/10
Offers a training-free, logically sound solution to tokenizer misalignment and ensemble noise. While the gains are moderate (1-3%), the emergent capability to correct consensus errors is notable.
