📝 Paper Summary
Agentic system evaluation
Code generation agents
Automated AI development
Agent-as-a-Judge uses agentic systems to evaluate other agents by analyzing full intermediate trajectories, providing richer feedback than final-outcome metrics or static LLM judges.
Core Problem
Current evaluations for agentic systems rely on final outcomes (ignoring step-by-step logic) or expensive human labor, failing to provide the intermediate feedback necessary for self-improvement.
Why it matters:
- Benchmarks like SWE-Bench rely on final resolve rates, missing internal process failures that affect performance
- Human evaluation provides rich feedback but is prohibitively expensive and unscalable for rapid agent iteration
- Standard LLM-as-a-Judge approaches lack the tooling (file reading, code execution) to verify complex, multi-step agent trajectories
Concrete Example:
In a coding task, a developer agent might fail because of a small dependency error mid-process. A standard 'pass/fail' metric only reports failure at the end, while Agent-as-a-Judge can identify the specific file and step where the dependency was missed.
Key Novelty
Agent-as-a-Judge Framework & DevAI Benchmark
- Extends LLM-as-a-Judge by equipping the evaluator with agentic tools (graph construction, file execution, locating code) to verify intermediate steps, not just final text
- Introduces DevAI, a benchmark of 55 realistic AI development tasks with 365 hierarchical requirements, designed to test full development cycles rather than isolated snippets
Architecture
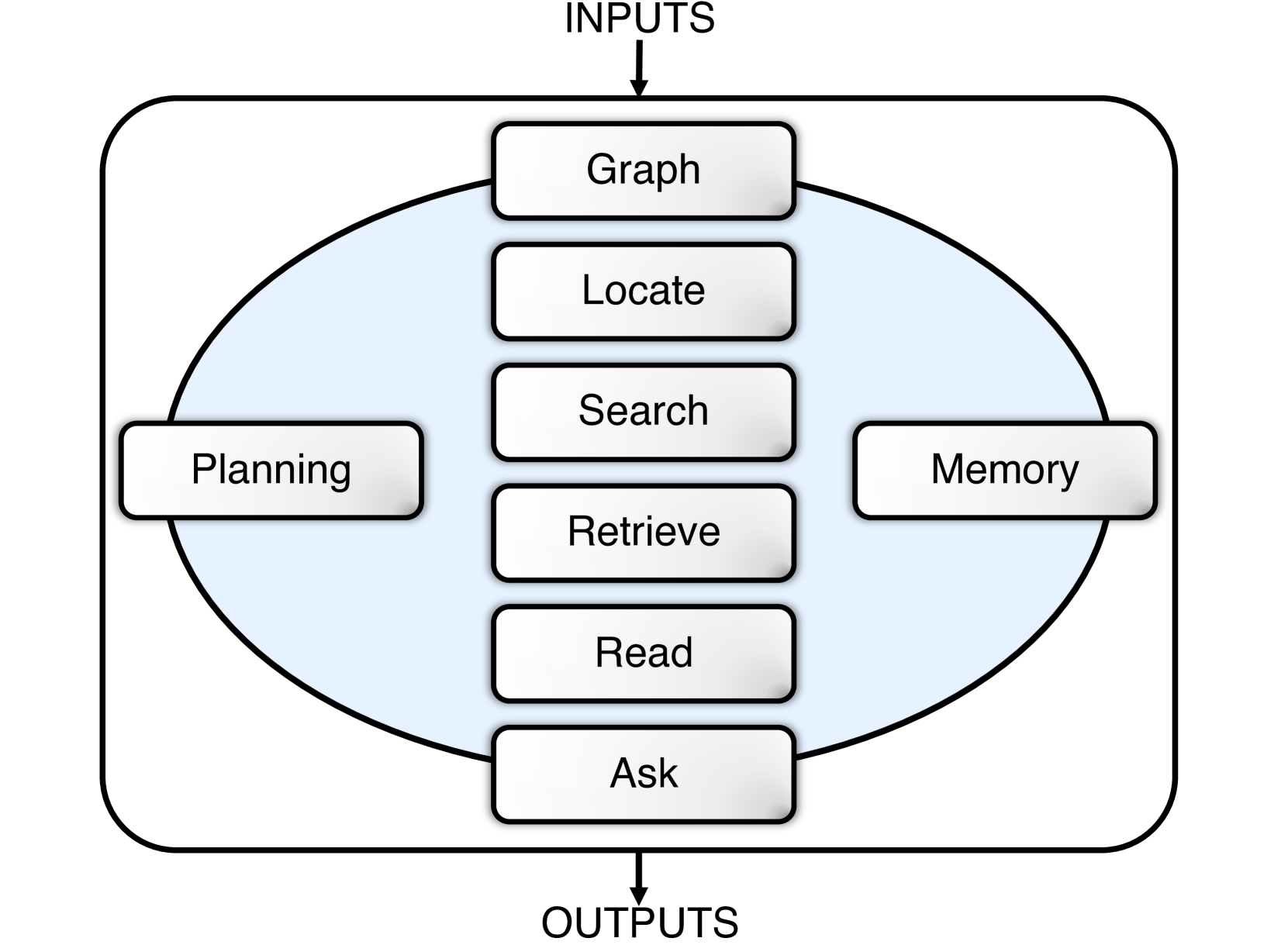
The modular architecture of the Agent-as-a-Judge system.
Evaluation Highlights
- Agent-as-a-Judge aligns with human consensus 90% of the time, significantly outperforming LLM-as-a-Judge (70%) on the DevAI benchmark
- Reduces evaluation time by 97.72% and cost by 97.64% compared to a panel of three human experts
- Leading agents (GPT-Pilot, OpenHands) only satisfy ~29% of requirements in DevAI, indicating the benchmark provides a significant challenge
Breakthrough Assessment
8/10
Strong proof-of-concept for scalable, high-quality agent evaluation. The release of DevAI and the cost/performance analysis against human judges make it a valuable contribution to the agentic workflow ecosystem.
