📝 Paper Summary
Memory internalization
Knowledge distillation
On-policy learning
On-Policy Context Distillation (OPCD) enables language models to internalize context by training on their own generated trajectories while minimizing reverse KL divergence against a context-conditioned teacher.
Core Problem
Existing context distillation methods rely on off-policy training with forward KL divergence, which causes exposure bias (mismatch between teacher-forced training and student generation) and mode-covering behavior (hallucinations).
Why it matters:
- In-context knowledge is transient and lost when the context resets, requiring costly re-processing of prompts or retrieved documents
- Standard off-policy distillation suffers from exposure bias, where students fail to correct their own errors during inference
- Forward KL minimization forces students to cover the teacher's entire distribution, leading to broad, disjointed outputs when the student lacks the teacher's capacity
Concrete Example:
When distilling a math solution trace into a student, standard methods force the student to mimic the exact teacher tokens. If the student deviates slightly, it doesn't learn how to recover. OPCD lets the student generate its own solution attempts and corrects them based on the teacher's feedback.
Key Novelty
On-Policy Context Distillation (OPCD)
- Trains the student model on its own generated trajectories (on-policy) rather than fixed teacher data, ensuring it learns to recover from its own states
- Uses reverse KL divergence to encourage mode-seeking behavior, making the student focus on the teacher's high-likelihood regions rather than trying to cover the entire complex distribution
- Applies this to 'Experiential Knowledge Distillation', where models solve problems, extract lessons, and then internalize those lessons permanently
Architecture
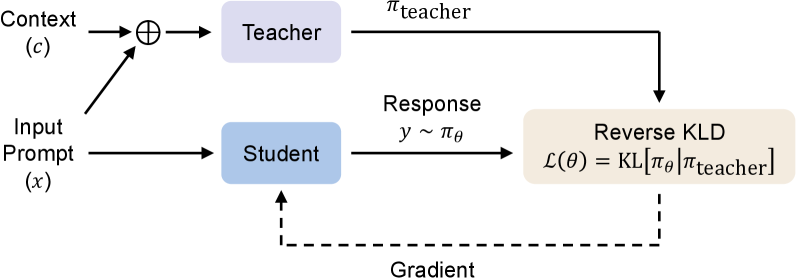
The training loop where the student generates a trajectory y from x, and the teacher evaluates [c; x; y] to provide supervision via reverse KL.
Evaluation Highlights
- +10-15% accuracy gains on DAPO-Math-17K compared to standard context distillation baselines
- Achieves ~2% higher accuracy on out-of-distribution benchmarks (IF-Eval) compared to off-policy baselines, indicating reduced catastrophic forgetting
- Enables effective cross-size distillation where a 1.7B student successfully internalizes knowledge from an 8B teacher, whereas direct context injection fails
Breakthrough Assessment
8/10
Significantly improves upon standard context distillation by addressing fundamental optimization issues (exposure bias, mode-averaging). The application to 'experiential knowledge'—learning from self-generated traces—is a compelling path for self-improving LLMs.