📝 Paper Summary
Language Model Pretraining
Scaling Laws
Domain Adaptation
The paper proposes a scaling law to determine the optimal compute allocation between general pretraining and domain-specific specialization (split training) for multi-domain language models.
Core Problem
When training models across multiple domains, it is unclear how to optimally allocate a fixed compute budget between shared general pretraining and independent domain-specific specialization.
Why it matters:
- Standard practice often uses arbitrary ratios (e.g., 80% pretraining, 20% specialization) without theoretical justification.
- Training a single dense model on all domains is inefficient compared to specialized models for specific tasks.
- Overtraining on general data wastes compute that could yield higher performance if allocated to specialization.
Concrete Example:
In a synthetic phonebook memorization task, allocating 100% of compute to pretraining on combined data fails to memorize facts that are easily learned if the model is split early (20-40% pretraining) and specialized on subsets.
Key Novelty
Optimal Split Point Scaling Law
- Derives a functional form for loss that accounts for both pretraining tokens and specialization tokens, treating them as separate contributors to performance.
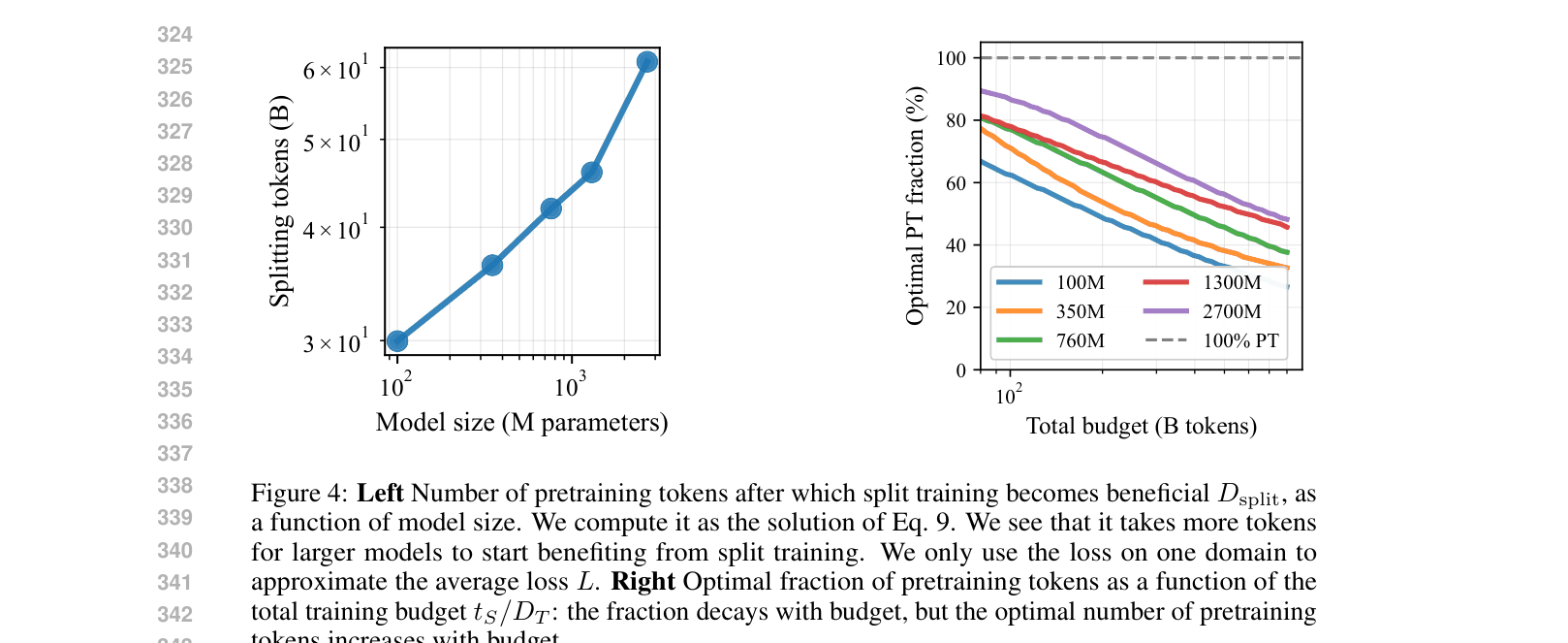
- Identifies a 'split point' where the marginal gain from general pretraining drops below the gain from specialized training.
- Demonstrates that splitting models early (e.g., <50% of total budget) often outperforms full pretraining followed by short finetuning.
Architecture
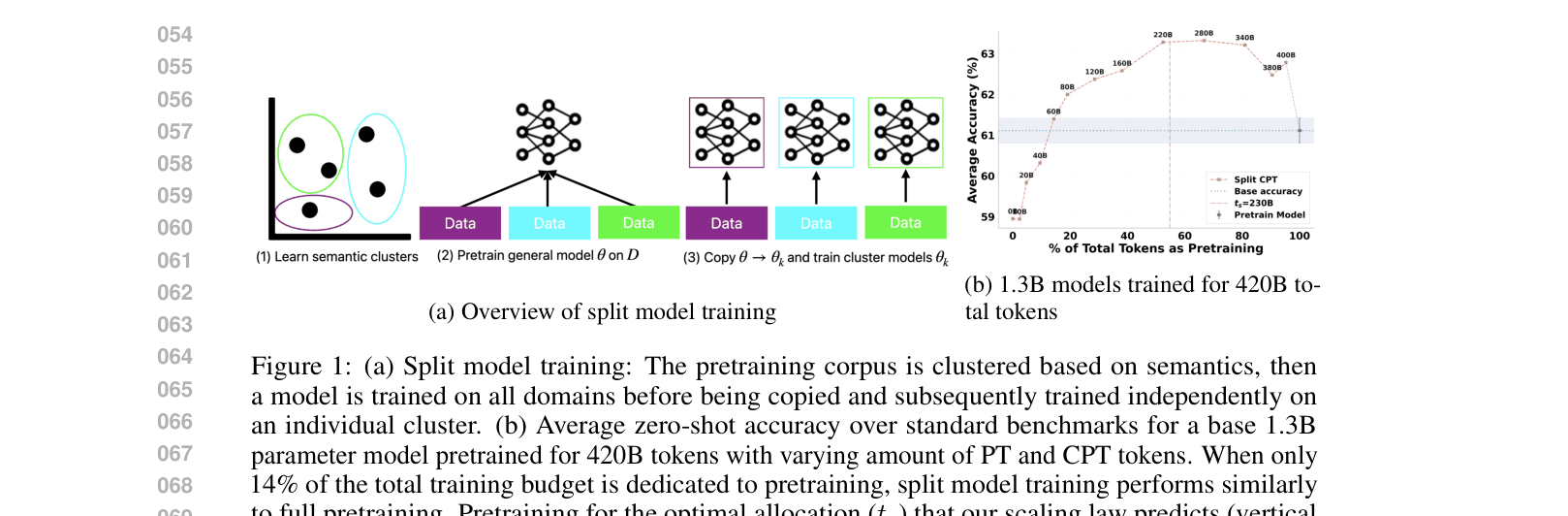
The split model training process: Clustering data, training a shared seed, copying to experts, and independent training.
Evaluation Highlights
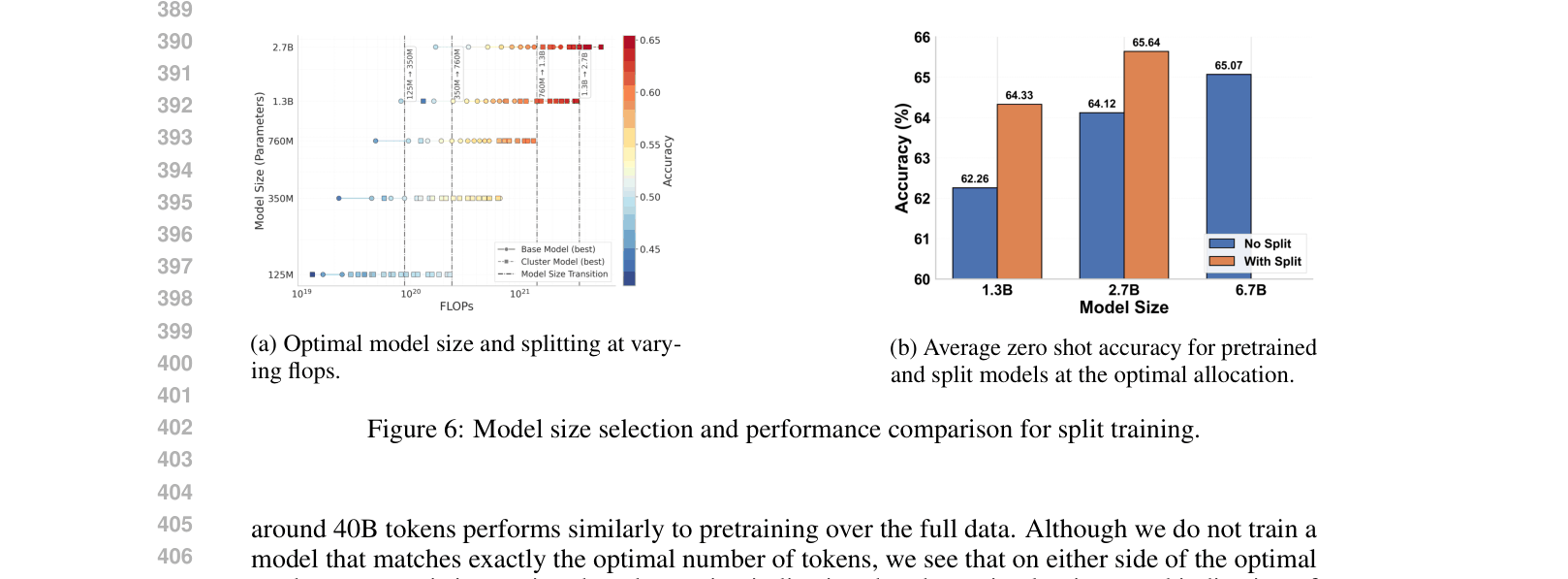
- Split models achieve 1.5% higher zero-shot accuracy on reasoning benchmarks compared to full pretraining at the same compute budget (1.3B/2.7B scale).
- A 2.7B split model outperforms a fully pretrained model of the same size by 0.6% and is competitive with larger models.
- On Pile domains, split models improve perplexity by 9.33% on average compared to a single base pretrained model.
Breakthrough Assessment
7/10
Provides a practical, theoretically grounded recipe for compute allocation in the increasingly important 'mixture of experts/domains' training paradigm. Validated on solid benchmarks, though primarily at smaller (<7B) scales.