📝 Paper Summary
Language Model Memorization
Diffusion Language Models (DLMs)
Privacy and Copyright
The paper formulates a generalized probabilistic extraction framework for Diffusion Language Models, proving that increasing sampling resolution increases verbatim memorization, yet DLMs exhibit lower PII leakage than scale-matched autoregressive models.
Core Problem
Standard memorization metrics rely on prefix-based decoding suited for autoregressive models (ARMs), but Diffusion Language Models (DLMs) generate via bidirectional, non-causal denoising, making existing metrics inapplicable.
Why it matters:
- Memorization of training data leads to privacy leakage (PII) and copyright infringement risks in deployed models.
- DLMs are emerging as competitive alternatives to ARMs, but their unique generation dynamics make their privacy risks largely uncharacterized.
- Without a formal definition for DLM memorization, it is impossible to audit these models for data leakage or compare them fairly against ARMs.
Concrete Example:
In an ARM, memorization is tested by providing a prefix 'My email is...' and checking if the suffix matches training data. In a DLM, generation happens by gradually denoising a fully masked sequence or random subsets, meaning there is no fixed 'prefix' order, so the standard test fails to capture how the model exposes data.
Key Novelty
Generalized Probabilistic Extraction Framework for DLMs
- Generalizes the definition of 'discoverable extraction' to handle arbitrary masking patterns and stochastic sampling trajectories, rather than just left-to-right generation.
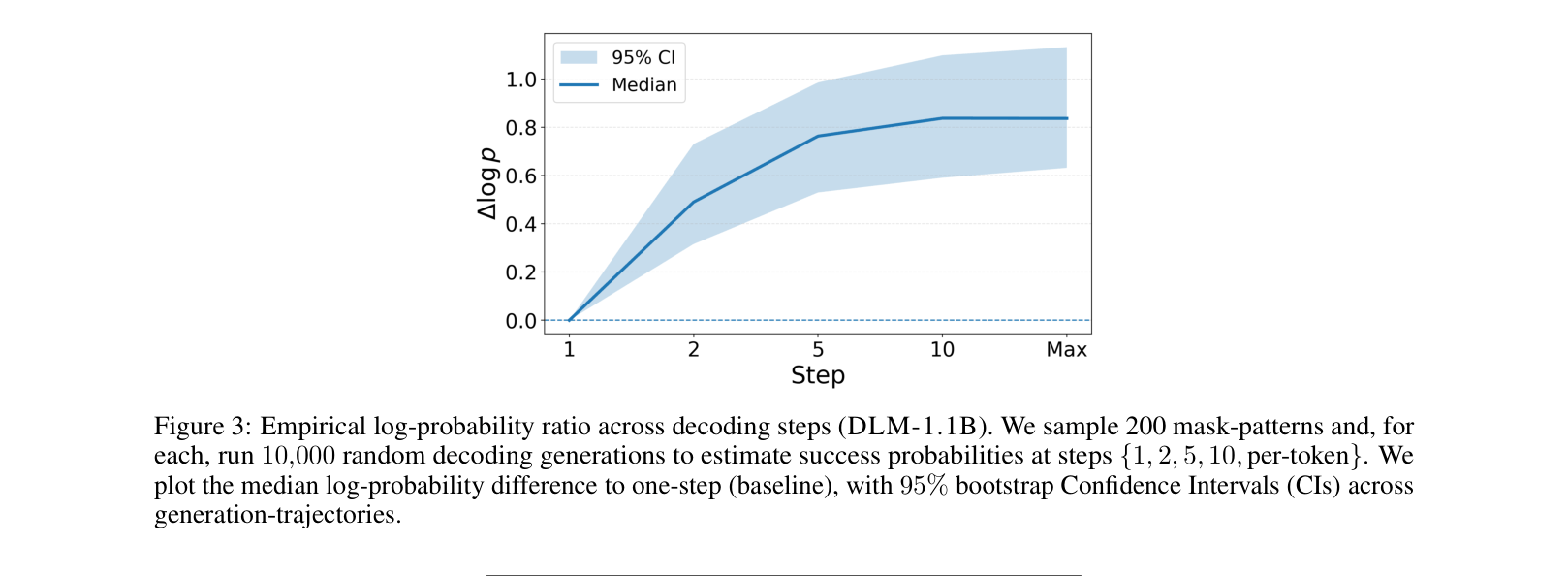
- Establishes a theoretical link between 'sampling resolution' (number of denoising steps) and memorization: recovering tokens in finer steps increases the chance of exactly reproducing training data.
- Proposes that Autoregressive decoding is mathematically a special limiting case of diffusion generation where the sampling resolution is maximal (one token per step).
Architecture

A visual example of PII (email header) memorization in a diffusion model (LLaDA-8B), contrasting masked inputs with the generated output.
Evaluation Highlights
- Diffusion models (DLMs) show substantially lower PII leakage than ARMs: 0 exact email extractions for DLM-1.1B vs 213 for ARM-1.1B under aligned settings (p=0.99).
- Increasing sampling resolution strictly increases memorization: LLaDA-8B extraction counts rose from 9 (one-step) to 179 (max-resolution) for emails (p=0.50).
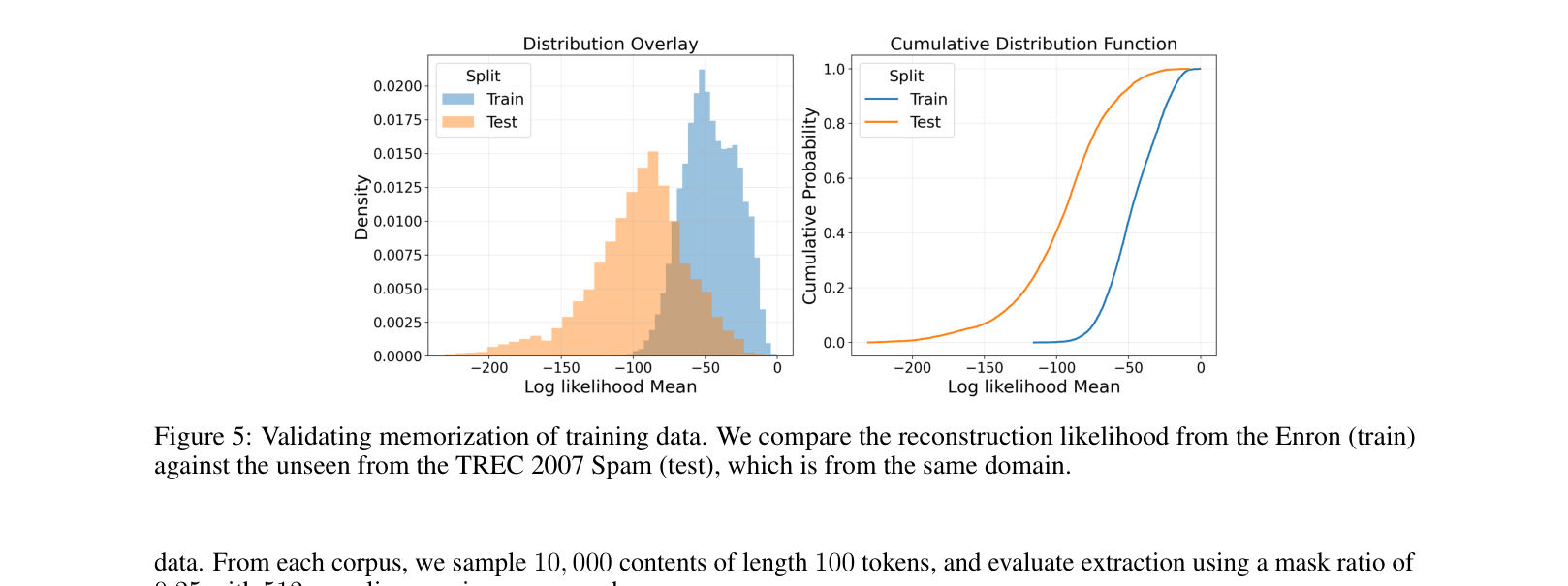
- Metric validation confirms training data (Enron) has consistently higher reconstruction likelihood than disjoint test data (TREC Spam), verifying the metric measures memorization, not just generalization.
Breakthrough Assessment
7/10
Establishes the first formal framework for measuring memorization in DLMs and provides a strong theoretical link between sampling steps and privacy risk. Empirical results are solid, though limited to smaller scales (1.1B/8B) compared to SOTA ARMs.