📝 Paper Summary
Modularized RAG pipeline
Clinical data standardization
CDE-Mapper standardizes complex clinical data by decomposing composite elements into simpler queries, retrieving concepts from controlled vocabularies using ensemble retrieval, and validating results with human experts.
Core Problem
Existing methods struggle to standardize composite Clinical Data Elements (CDEs) that contain interdependent attributes (e.g., biomarkers measured over time) or inconsistent representations across healthcare systems.
Why it matters:
- Inconsistent concept linking impedes data integration and interoperability across diverse healthcare systems, blocking large-scale clinical research.
- Composite CDEs (capturing multiple attributes) are often ignored or poorly handled by existing atomic-focused methods, leading to loss of crucial clinical context.
- Scalability is limited in current deep learning methods when dealing with massive, evolving controlled vocabularies like SNOMED or LOINC.
Concrete Example:
A variable 'heart attack - main cause of hospitalization, measured at baseline' is a composite CDE. Standard methods might link only 'heart attack' but miss the 'hospitalization reason' or 'baseline' timing, losing critical context. CDE-Mapper decomposes this into separate queries for condition, reason, and timing.
Key Novelty
Modular RAG with Query Decomposition and Human-Validated Reservoir
- Decomposes complex clinical variables (composite CDEs) into atomic sub-queries (label, unit, timing) using LLM-based in-context learning before retrieval.
- Employs a 'Knowledge Reservoir' that stores expert-validated mappings, allowing the system to bypass expensive retrieval for previously seen or frequent concepts.
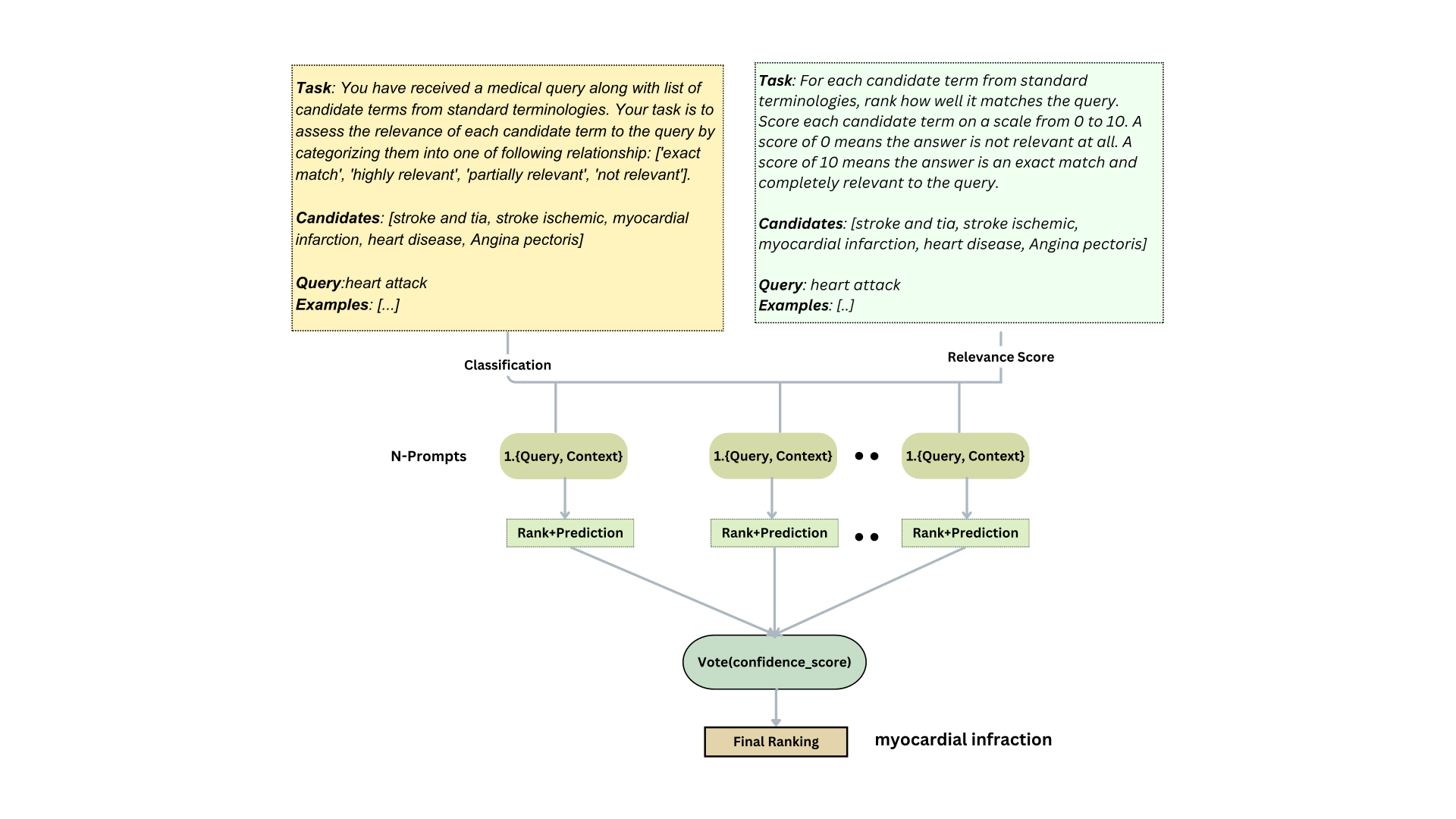
- Uses an ensemble retrieval strategy combining sparse (keyword) and dense (semantic) embeddings to handle both exact terminology matches and ambiguous descriptions.
Architecture
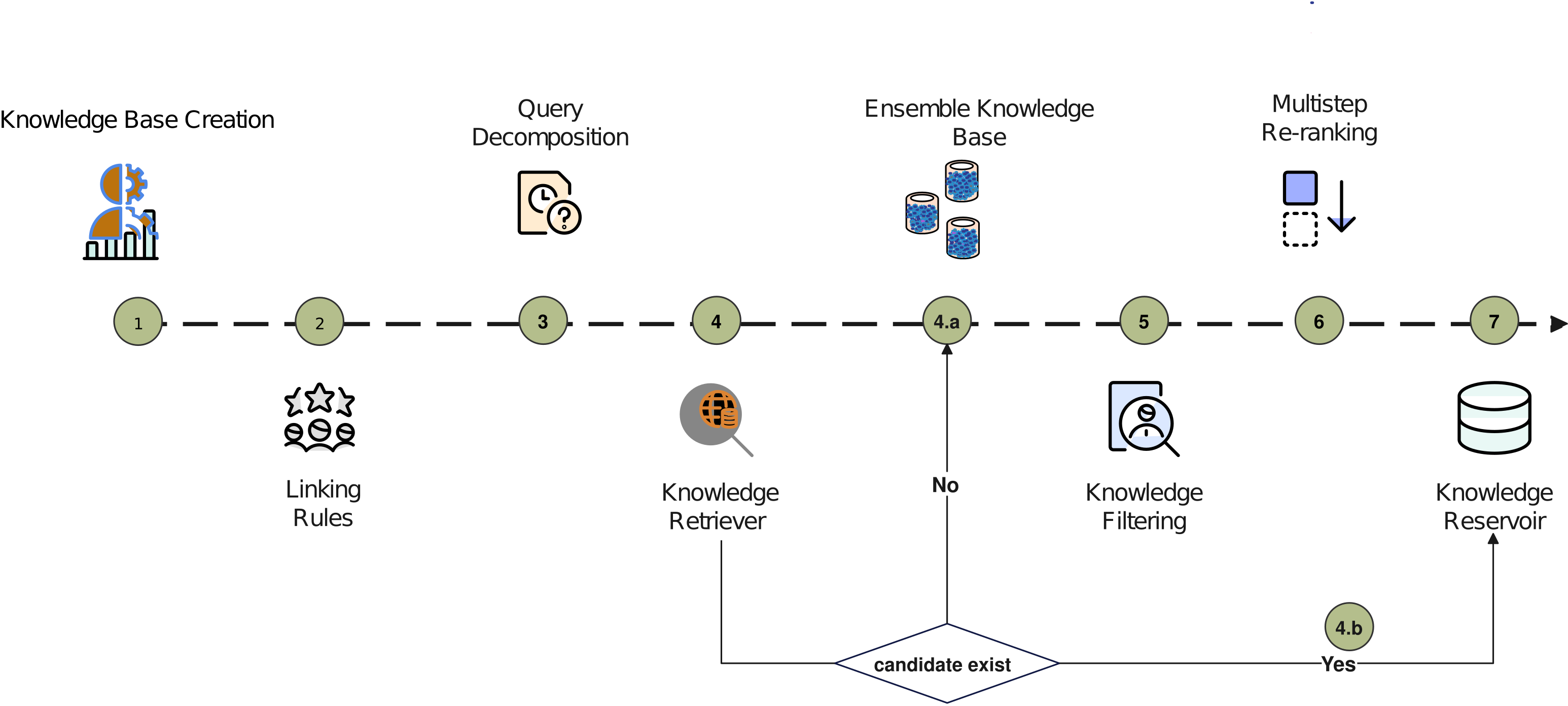
The overall CDE-Mapper framework illustrating the pipeline from data dictionary input to standardized output.
Evaluation Highlights
- Achieved 7.2% average accuracy improvement compared to baseline methods across four diverse datasets (BC5CDR, NCBI-DC, MIID, and Heart Failure data).
- Successfully standardized composite CDEs in Heart Failure datasets, a capability lacking in baselines like BioSyn and KRISSBERT which focus on atomic entities.
Breakthrough Assessment
7/10
Strong practical application of RAG to a specific, high-value clinical problem (composite CDEs). The architecture is sound, though the core innovation relies on assembling existing techniques (decomposition, ensemble retrieval) rather than novel fundamental algorithms.