📝 Paper Summary
Knowledge Internalization vs. External Retrieval
Theoretical capacity of LLMs
The number of facts an LLM can memorize is fundamentally limited by parameter count, whereas tool-augmented models can achieve unbounded factual recall by learning simple query-generation circuits.
Core Problem
Relying on in-weight learning (memorization) for factual knowledge creates a structural bottleneck where the number of learnable facts is strictly bounded by model capacity.
Why it matters:
- Monolithic models cannot scale indefinitely to encompass all world knowledge without becoming prohibitively large
- Fine-tuning models to memorize new facts is inefficient compared to teaching them generalizable rules for information retrieval
- Current approaches often conflate acquiring new facts (which requires capacity) with learning new behaviors (which requires rule induction)
Concrete Example:
In a synthetic biography task, an in-weight model fails to recall attributes (e.g., birthplaces) once the dataset size exceeds its parameter capacity, whereas an in-tool model simply learns to format a lookup query (e.g., 'SELECT birthplace FROM people WHERE name=X') and scales indefinitely.
Key Novelty
Formal separation of In-Weight vs. In-Tool Learnability
- Proves a theoretical lower bound: the number of facts a model can store in weights scales linearly with parameter count (P ≥ #Facts * constant)
- Proves an existence upper bound: a Transformer with constant parameters (O(|A|²)) can recall unbounded facts by learning a circuit to query external tools
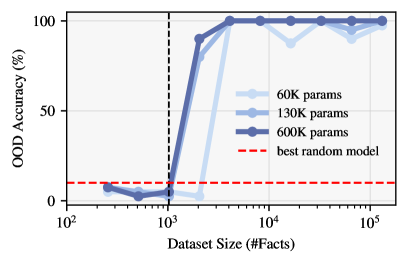
- Identifies a 'grokking'-like phase transition where models switch from memorizing tool outputs to learning the generalizable logic of query construction
Architecture
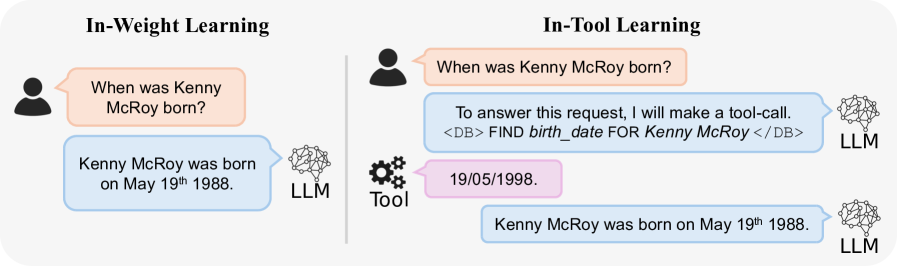
Comparison of the two learning paradigms: In-Weight vs. In-Tool
Evaluation Highlights
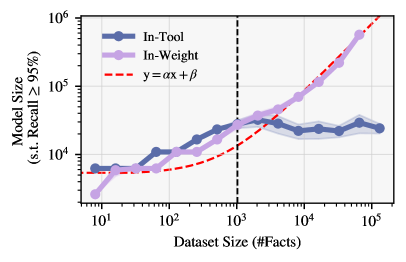
- In-weight models require parameters to scale linearly with the number of facts, eventually failing when facts > capacity
- In-tool models saturate parameter requirements at ~1,000 facts, maintaining perfect recall for arbitrarily larger datasets without adding parameters
- Introducing correlations between facts (α > 0) reduces parameter requirements for in-weight models, confirming that structure aids memorization
Breakthrough Assessment
8/10
Provides a rigorous theoretical foundation for the intuition that RAG/tool-use is superior to memorization. The formal proofs on parameter bounds are a significant contribution to the theory of LLM scaling.