📝 Paper Summary
LLM-based Multi-Agent Systems
Automated Software Engineering
MetaGPT integrates human Standard Operating Procedures (SOPs) into LLM-based multi-agent systems, using structured outputs and executable feedback to reduce hallucinations and improve complex software generation.
Core Problem
Existing multi-agent systems suffer from cascading hallucinations and incoherent collaboration when solving complex tasks, often devolving into unproductive chatter.
Why it matters:
- Naive chaining of LLMs lacks the rigorous process control needed for complex engineering tasks.
- Unstructured natural language communication between agents (like the 'telephone game') leads to information distortion.
- Current frameworks struggle with meaningful collaborative interaction and maintaining consistency in long-term goals.
Concrete Example:
In chat-based role-playing frameworks, agents might waste context on social pleasantries ("Have you had lunch?") or pass ambiguous requirements, causing the final code to deviate from the original user intent.
Key Novelty
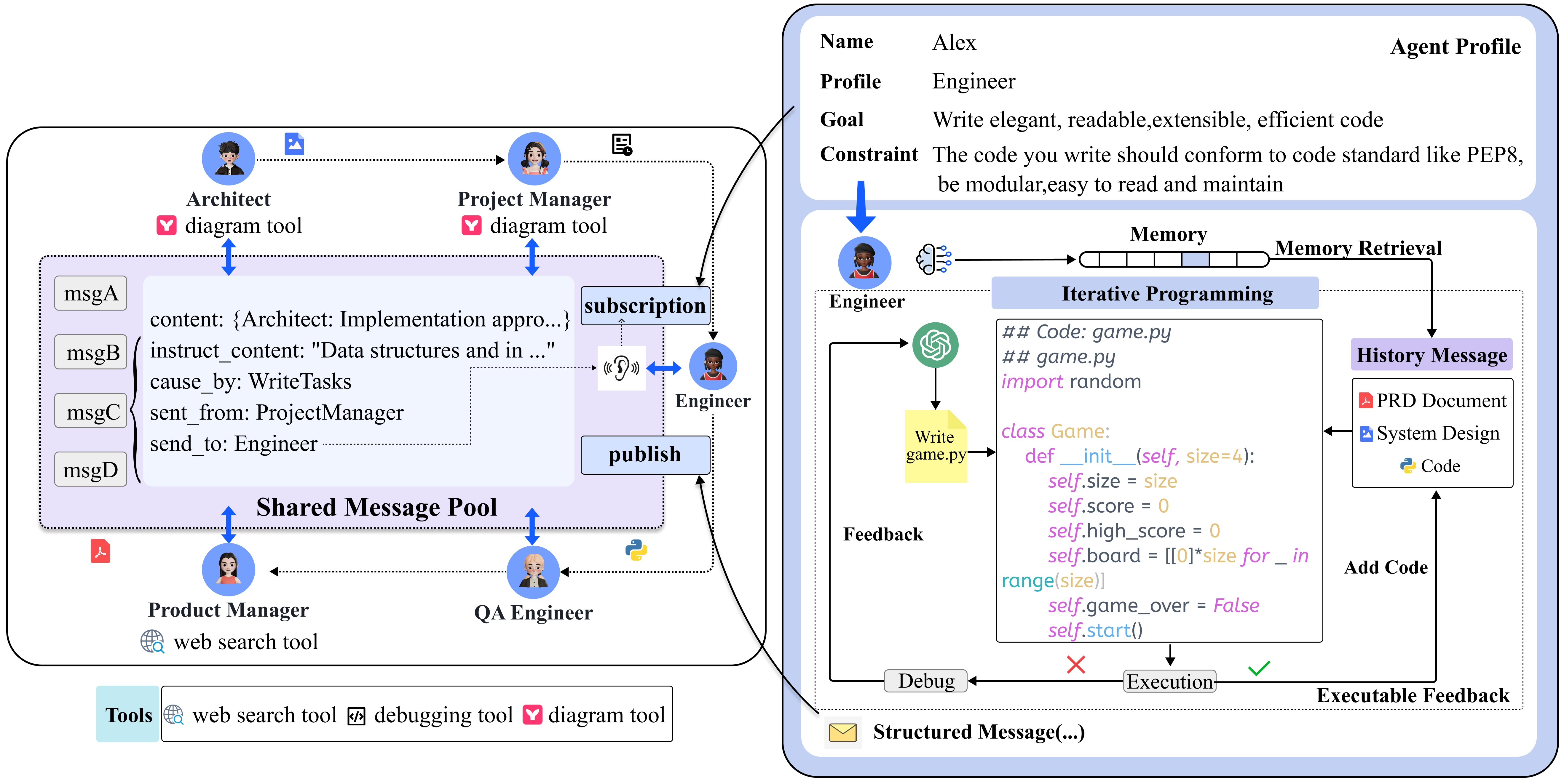
SOP-driven Meta-Programming Framework
- Encodes Standardized Operating Procedures (SOPs) into prompt sequences, forcing agents to generate structured outputs (documents, diagrams) rather than just dialogue.
- Implements a 'software company' metaphor with specialized roles (Product Manager, Architect, Engineer) that share information via a subscription-based message pool.
- Introduces a self-correction mechanism where engineers execute code and use runtime feedback/errors to iteratively debug and refine the solution.
Architecture
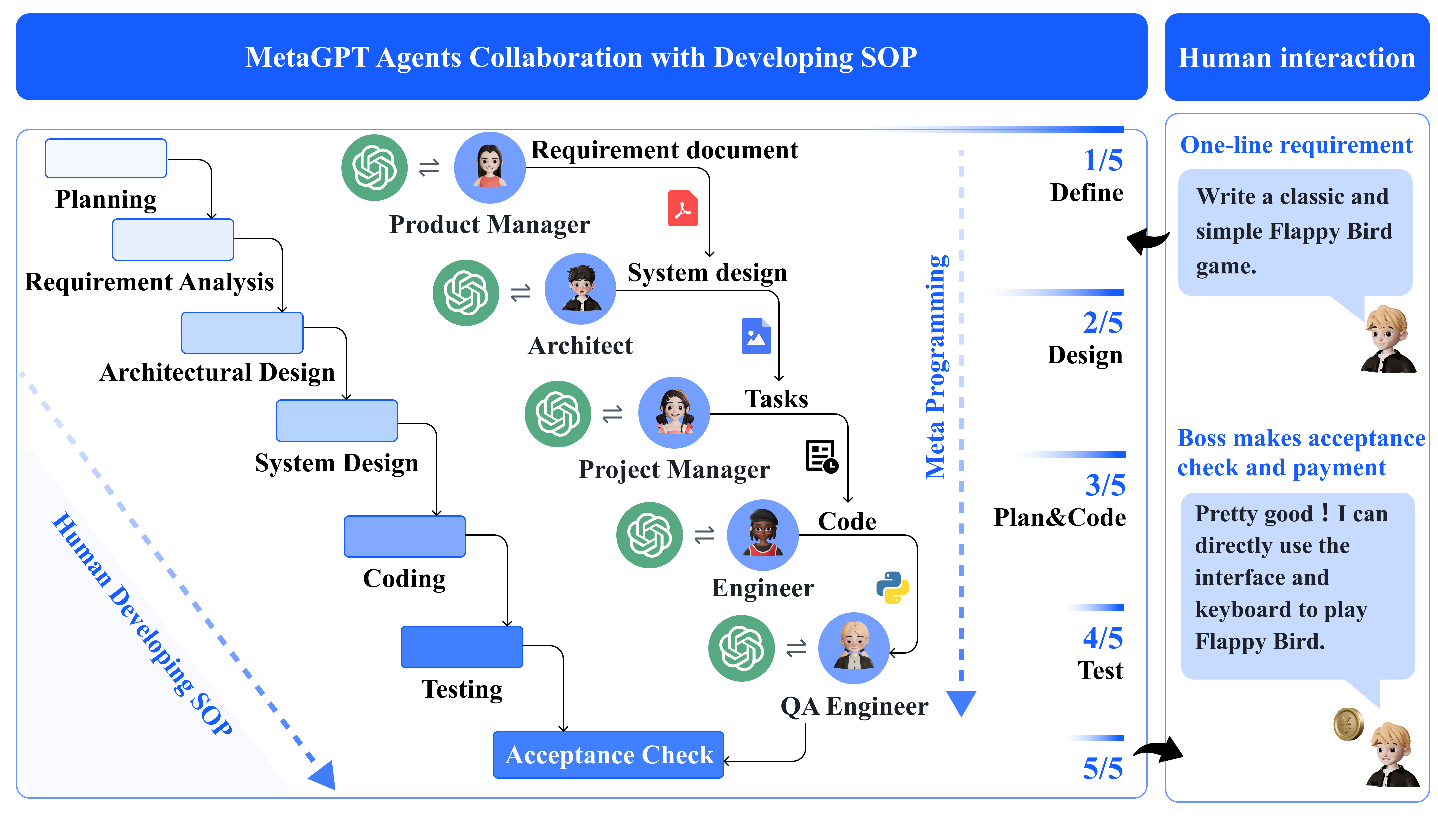
The software development SOP mapped to MetaGPT agents.
Evaluation Highlights
- Achieves 85.9% Pass@1 on the HumanEval benchmark, a new state-of-the-art for code generation.
- Achieves 87.7% Pass@1 on the MBPP benchmark.
- Attains a 100% task completion rate in experimental evaluations, demonstrating robustness compared to systems that often enter infinite loops.
Breakthrough Assessment
9/10
Significantly outperforms existing frameworks (AutoGPT, ChatDev) on coding benchmarks by imposing structure on agent interactions. The integration of SOPs and executable feedback effectively tackles the hallucination problem in multi-agent workflows.