📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Hallucination Evaluation
LongHalQA is an LLM-free benchmark for MLLMs containing 6K long-context questions that unifies hallucination discrimination and completion into a multiple-choice format to evaluate complex, real-world scenarios.
Core Problem
Existing MLLM hallucination benchmarks either use oversimplified discriminative questions (short yes/no queries) or computationally expensive generative evaluations relying on unstable LLM judges.
Why it matters:
- Current benchmarks with short questions fail to capture hallucinations in sophisticated real-world scenarios involving long descriptions and multi-round conversations
- Reliance on fixed object sets (e.g., COCO's 80 categories) limits variability and biases evaluation
- LLM-based evaluators for generative tasks are slow, costly, and introduce randomness that affects reliability
Concrete Example:
A standard benchmark might ask 'Is there a cat?' (binary). LongHalQA presents a 130-word description where the model must identify subtle inconsistencies, like 'four plates' vs 'five plates' or mixed-up spatial descriptions like 'shirts in the central part' vs 'right part'.
Key Novelty
Unified MCQ format for Long-Context Hallucination
- Transforms both discrimination (spotting errors) and completion (avoiding generation errors) into Multiple-Choice Questions (MCQs), eliminating the need for external LLM evaluators
- Focuses specifically on long-context data (130-189 words avg) including object descriptions, image descriptions, and multi-round conversations, rather than short captions
- Introduces LongHallGen, an automated pipeline using GPT-4V to generate, check, and format complex hallucination data
Architecture
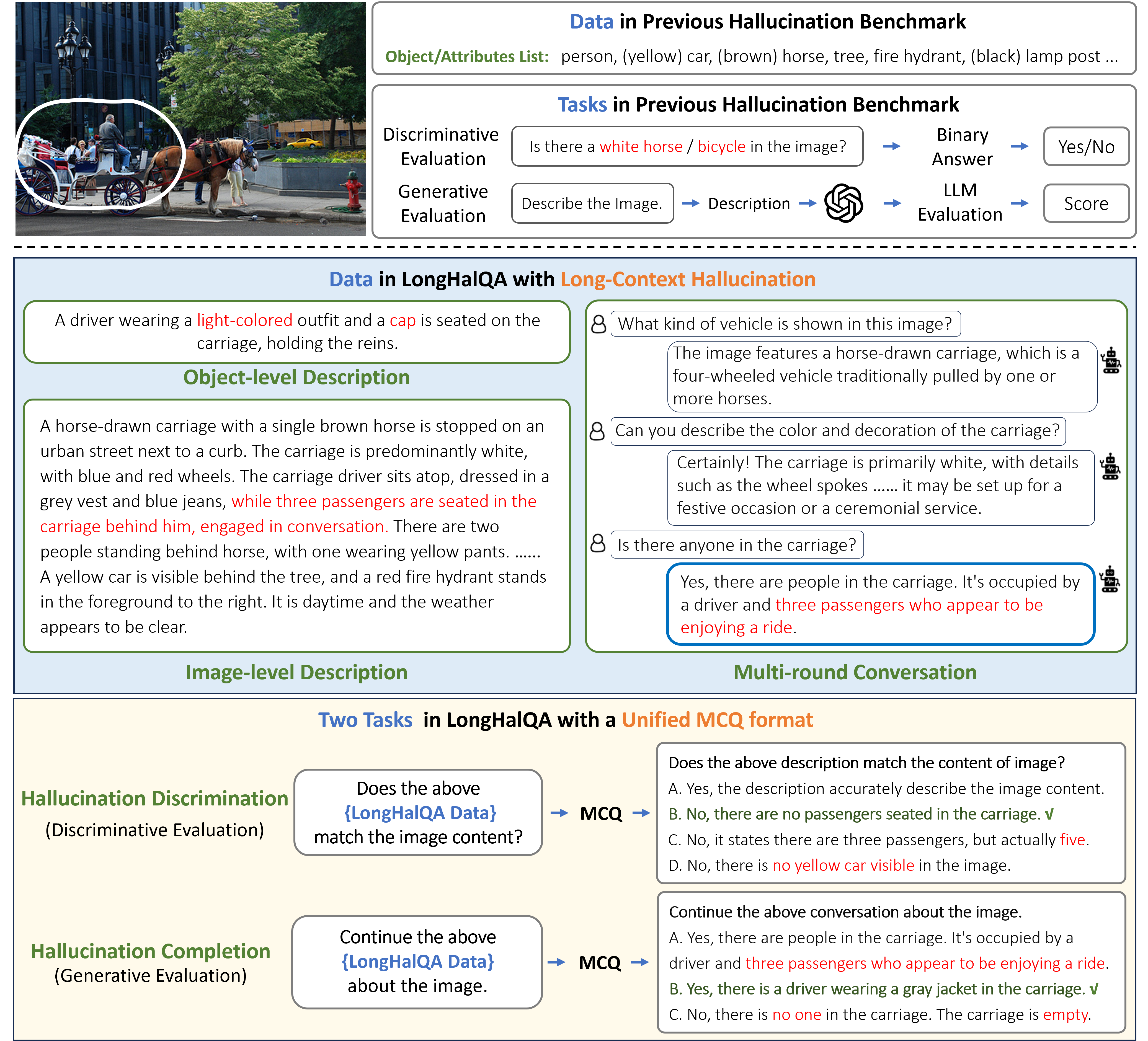
Comparison between previous benchmarks (top) and LongHalQA (bottom), illustrating the data formats and task types.
Evaluation Highlights
- Qwen2-VL-72B achieves the best performance on hallucination completion tasks among open-source models, surpassing LLaVA-v1.6-34B
- Chain-of-Thought (COT) prompting degrades performance for most MLLMs on long-context hallucination discrimination, despite helping with short queries
- GPT-4o outperforms other models in hallucination discrimination, particularly for multi-round conversations (+9.5% accuracy gain over others)
Breakthrough Assessment
8/10
Strong contribution by shifting focus to long-context hallucinations and unifying evaluation into an efficient MCQ format. The automated generation pipeline is valuable, though the reliance on GPT-4V for ground truth generation introduces some circular dependency risks.
