📝 Paper Summary
Hallucination Evaluation
Factual Knowledge Benchmarking
ERBench leverages relational database constraints (functional dependencies and foreign keys) to automatically generate complex, multi-hop questions and verify both the correctness of LLM answers and their underlying rationales.
Core Problem
Existing hallucination benchmarks are either manual (expensive, not scalable) or based on simple knowledge graph triples (simplistic questions), failing to evaluate complex reasoning chains or verify the specific rationale behind an answer.
Why it matters:
- LLMs frequently generate correct answers for the wrong reasons (hallucinated rationales), which current benchmarks often miss
- Evaluating multi-hop reasoning usually requires expensive human annotation or results in rigid, unmodifiable datasets
- Continuous evaluation is difficult because static benchmarks become outdated as facts change, whereas databases are naturally updated
Concrete Example:
If asked 'Are Firenze and Florence the same city?', an LLM might answer 'Yes' (correct answer) but justify it by saying 'Because both are in the US' (hallucinated rationale). Standard benchmarks checking only the 'Yes' token would fail to catch this hallucination.
Key Novelty
Database-Driven Benchmark Generation
- Uses Functional Dependencies (FDs) to verify rationales: if attributes X determine Y, the LLM must mention the correct intermediate Y values in its reasoning
- Uses Foreign Key Constraints (FKCs) to construct multi-hop questions: joining tables allows generating deep questions where intermediate steps are strictly defined by the database schema
Architecture
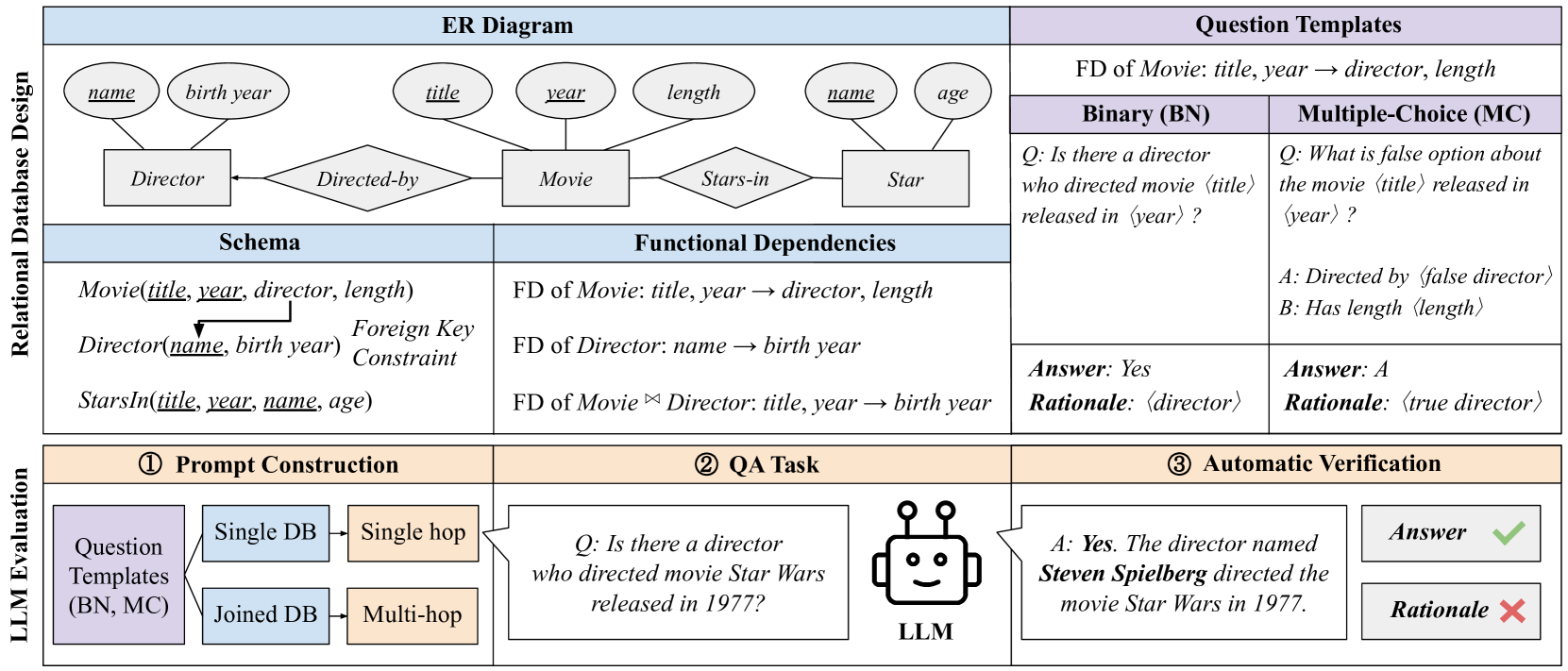
Conceptual workflow of ERBench using a Movie database example. It illustrates how an Entity-Relationship diagram translates to schema/records, then to Functional Dependencies (FDs) and Foreign Keys (FKs), which are finally used to construct verifiable questions.
Evaluation Highlights
- Benchmarked 8 major LLMs (including GPT-4, Llama2-70B, Claude-3) across 55 database domains
- GPT-4 achieves the highest Answer-Rationale Accuracy (AR) but still exhibits significant hallucination in negated questions
- ERBench's automated rationale verification matches human inspection with >95.5% accuracy, validating the FD-based approach
Breakthrough Assessment
8/10
A clever, highly scalable approach to a major bottleneck in LLM evaluation (verifying reasoning chains). By piggybacking on existing database structures, it solves the ground-truth generation problem elegantly.