📝 Paper Summary
Constrained Generation
Structured Output Generation
ITERGEN is a grammar-guided framework that enables LLMs to navigate generation both forward and backward using grammar symbols, allowing for iterative correction of semantic errors.
Core Problem
Current grammar-guided LLM generation tools rely on left-to-right decoding without systematic support for backtracking, making it difficult to correct semantic violations mid-generation.
Why it matters:
- Users must restart generation from scratch when outputs are semantically incorrect (e.g., using undefined variables or leaking private info)
- Token-level abstractions in current libraries are not tied to the syntax of the underlying generation, making navigation difficult
- Existing constrained decoding ensures syntactic correctness but fails to enforce semantic properties that extend beyond syntax
Concrete Example:
In SQL generation, an LLM might generate a query using a column name that doesn't exist in the schema. Current tools can enforce SQL syntax but can't backtrack to regenerate just the column name once the semantic error is detected; they require restarting the whole query.
Key Novelty
Bidirectional Grammar-Symbol Navigation
- Introduces 'forward' and 'backward' functions that operate on high-level grammar symbols (e.g., 'statement', 'expression') rather than raw tokens
- Maintains a dynamic symbol-to-position mapping to handle misalignment between LLM vocabulary tokens and grammar lexical tokens
- Uses a decoding trace tree to manage generation history, allowing precise backtracking and selective resampling of invalid fragments
Architecture
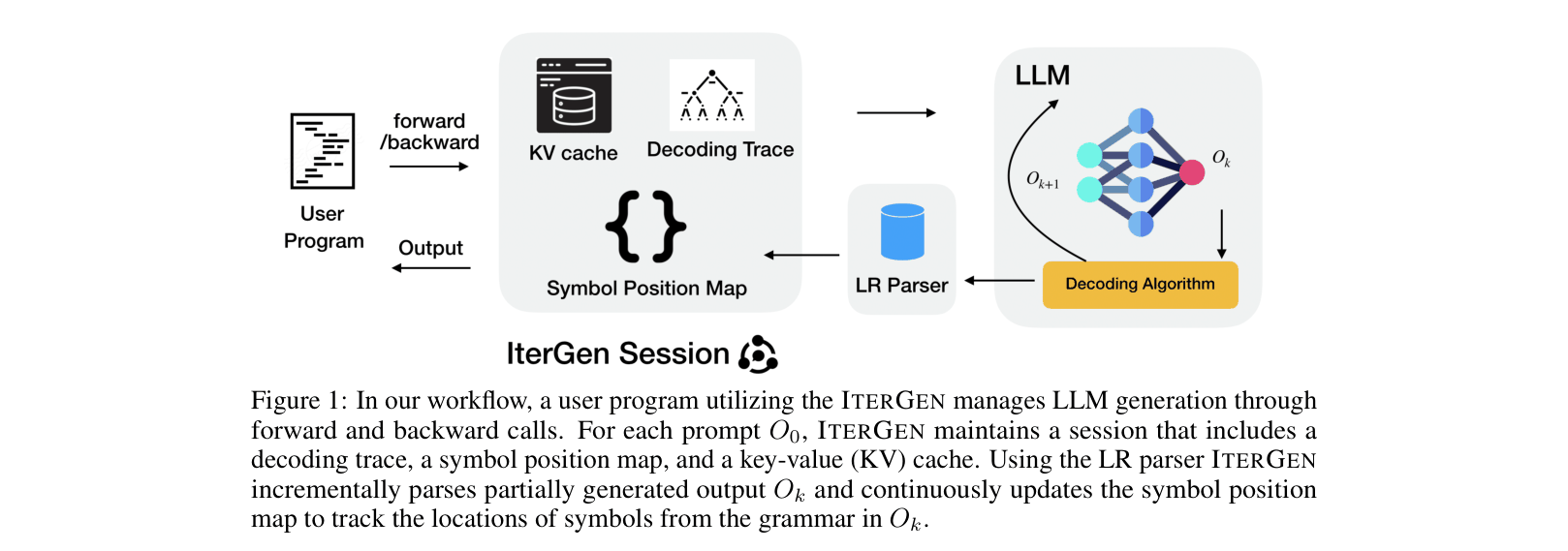
The workflow of ITERGEN, showing the interaction between the user program, the ITERGEN session state (trace, map, KV cache), and the LR parser.
Evaluation Highlights
- Reduces privacy leaks in LLM-generated text from 51.4% to 0% on the DecodingTrust Enron email task
- Improves SQL generation accuracy by 18.5% over state-of-the-art grammar-guided generation (SYNCODE) on the Spider dataset
- Increases Vega-Lite specification accuracy by 17.8% compared to SYNCODE on the NLV Corpus
Breakthrough Assessment
8/10
Significantly advances constrained generation by adding semantic-aware backtracking. The ability to completely eliminate privacy leaks and substantially improve code generation accuracy demonstrates high practical utility.

