📝 Paper Summary
Self-correction in LLMs
Multi-step reasoning
Confidence estimation
LeCo improves complex reasoning by identifying high-confidence steps using internal probability statistics and iteratively appending these correct steps to the input to guide subsequent generation.
Core Problem
LLMs often hallucinate or fail in multi-step reasoning, and existing self-correction methods rely heavily on expensive human feedback, external tools, or labor-intensive prompt engineering.
Why it matters:
- Reliance on external tools limits model autonomy and increases cost/latency.
- Prompt-based self-correction often fails because models struggle to find their own errors just by being asked.
- Crafting effective correction prompts turns researchers into 'prompt engineers' with inconsistent results across tasks.
Concrete Example:
In a math problem requiring multiple steps, a standard LLM might make an error in step 3 but continue reasoning. Existing methods ask 'Find the error', which the model often fails to do. LeCo instead identifies that steps 1-2 have high confidence, appends them to the prompt as ground truth, and asks the model to continue from there, bypassing the error.
Key Novelty
Learning from Correctness (LeCo)
- Inverts the standard 'debug the error' paradigm: instead of asking the model to fix mistakes, it identifies reliable steps and forces the model to build upon them.
- Uses a prompt-free, logit-based metric to calculate confidence for each reasoning step, combining token probabilities, distribution divergence, and transition probabilities.
Architecture
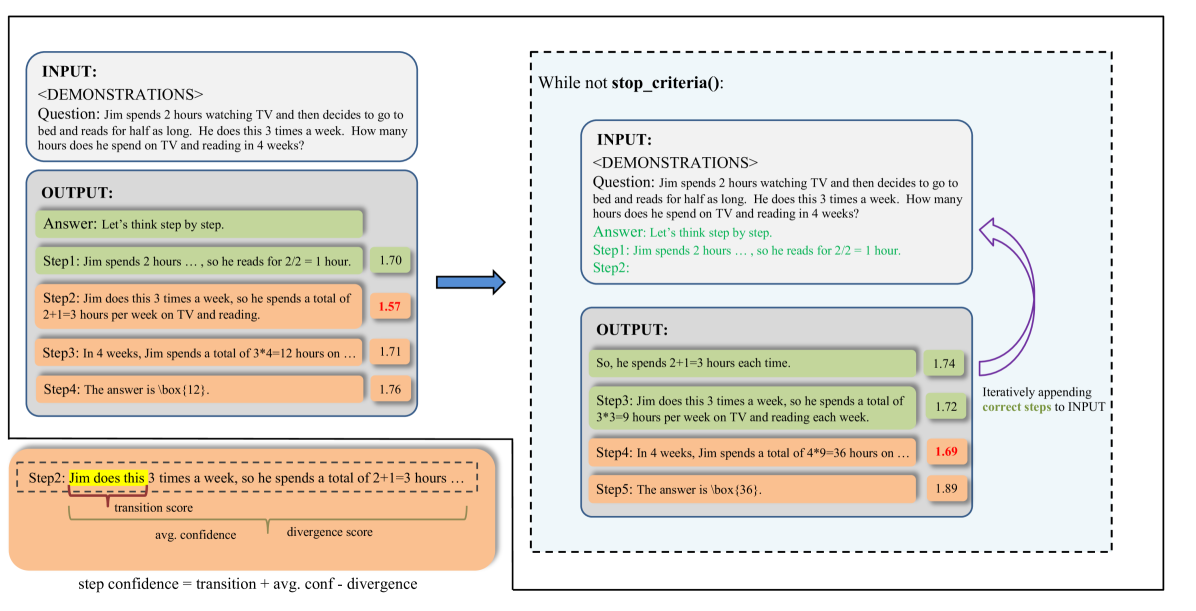
The workflow of the LeCo framework compared to standard prompting.
Evaluation Highlights
- LeCo identifies approximately 65% of incorrect steps using its intrinsic confidence metric without external tools.
- Improves reasoning performance on benchmarks (arithmetic, commonsense, logical) while reducing token consumption compared to standard self-correction methods.
- Effective across both closed-source (GPT-3.5/4) and open-source (DeepSeek) models without needing model fine-tuning.
Breakthrough Assessment
7/10
Offers a clever, efficient alternative to prompt-engineering-heavy self-correction. The metric design is intuitive and the 'progressive' approach aligns well with how humans solve problems, though reliance on logits limits applicability to some API-restricted models.