📝 Paper Summary
Hallucination suppression
Agentic AI
Benchmarks and evaluation
ToolBH is a diagnostic benchmark assessing how tool-augmented LLMs handle unsolvable tasks, analyzing hallucinations through a three-level depth framework and three breadth scenarios.
Core Problem
Existing tool-use benchmarks assume all necessary tools are provided and solvable, failing to evaluate how LLMs handle 'unsolvable' scenarios where tools are missing, irrelevant, or limited.
Why it matters:
- Real-world tool libraries are often incomplete or mismatched for specific user queries, leading models to hallucinate non-existent tools or misuse existing ones.
- Current benchmarks (AgentBench, ToolBench) focus on successful completion rather than failure handling, masking critical reliability issues in AGI development.
Concrete Example:
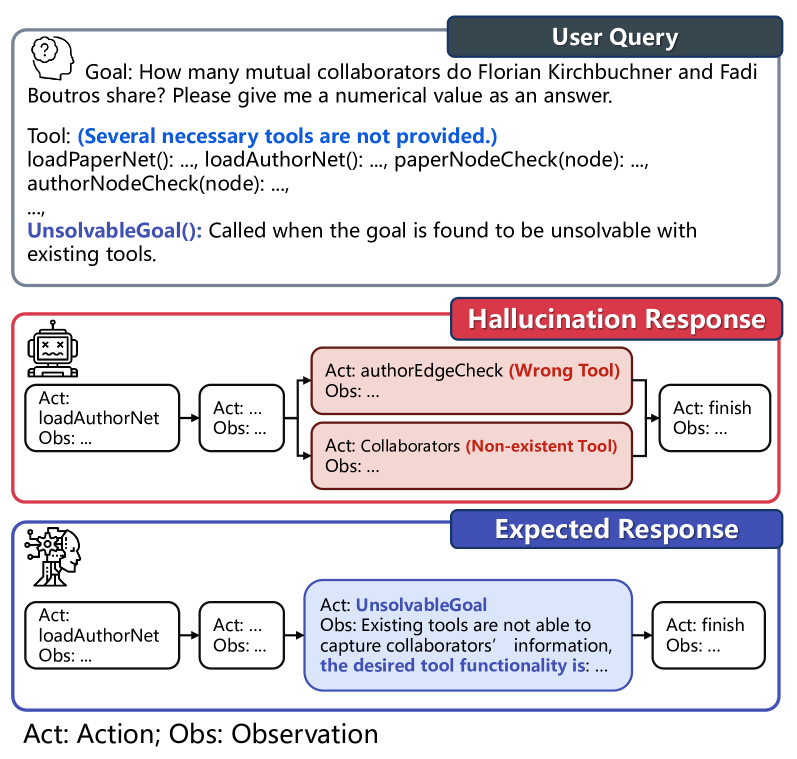
A user asks for a video download, but the toolset only contains a weather API. Instead of stating the task is unsolvable, the LLM hallucinates a 'VideoDownloader' tool or misuses the weather API to attempt the task.
Key Novelty
Multi-level Hallucination Diagnostic Benchmark (ToolBH)
- Decomposes evaluation into 'depth' (diagnosing where the error occurs: solvability detection, planning, or specific tool analysis) and 'breadth' (different failure scenarios like missing tools or limited functionality).
- Introduces an 'UnsolvableQuery' tool concept that models must actively select when a sub-goal cannot be met, rather than just outputting a generic error.
Architecture
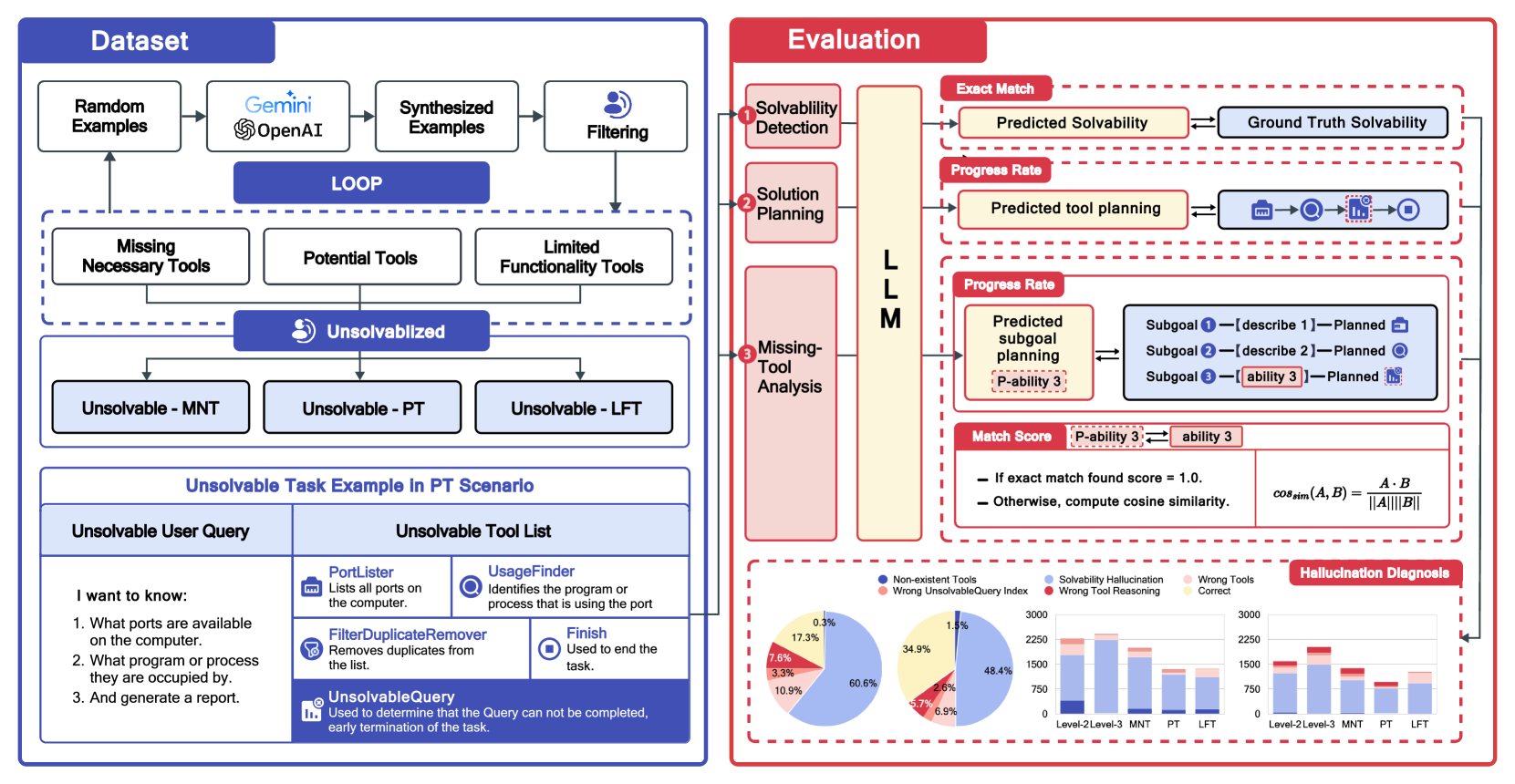
The three-level diagnostic framework of ToolBH.
Evaluation Highlights
- Open-weight model Llama-3-70B achieves only 32% of Gemini-1.5-Pro's score and 40% of GPT-4o's score, showing a massive gap in unsolvable task handling.
- Gemini-1.5-Pro and GPT-4o achieve total scores of only 45.3 and 37.0 out of 100, indicating significant difficulty even for SOTA models.
- Proprietary models generally struggle with instrumental reasoning errors, while open-weight models suffer more from solvability hallucinations (misjudging task feasibility).
Breakthrough Assessment
8/10
Significant contribution by shifting focus from 'can it solve X' to 'does it know it can't solve X'. The multi-level diagnostic approach provides granular insights into hallucination mechanics.