📝 Paper Summary
Hallucination detection
Factuality evaluation
RefChecker detects hallucinations by decomposing LLM responses into knowledge triplets and verifying each against references, significantly improving detection accuracy over sentence-level methods.
Core Problem
Existing hallucination detection methods operate at coarse granularities (response or sentence level), which often miss subtle fabrications or get confused by complex sentences containing both facts and errors.
Why it matters:
- Long responses from models like Llama 2 (avg 150 tokens) contain mixed truth and falsehoods; coarse checks cause false negatives
- Sub-sentence phrase extraction is structurally ill-defined, making it hard to create high-quality few-shot demonstrations for LLM-based evaluators
- Current benchmarks lack diversity across real-world settings like zero-context generation vs. RAG (Noisy Context)
Concrete Example:
If an LLM says 'Apple released the iPhone 15 in 2021,' a sentence-level checker might label the whole sentence 'False' or 'True' ambiguously. RefChecker extracts the triplet (iPhone 15, released_in, 2021), enabling precise verification against a reference that states the correct year.
Key Novelty
Claim-Triplet Granularity for Verification
- Decomposes text into (Subject, Relation, Object) triplets rather than sentences or arbitrary phrases, providing structured units that are easier to verify
- Introduces a three-way classification (Entailment, Neutral, Contradiction) to handle unverifiable claims, rather than just binary factual/non-factual
- Formalizes three distinct evaluation settings: Zero Context (closed-book), Noisy Context (RAG), and Accurate Context (summarization/IE)
Architecture
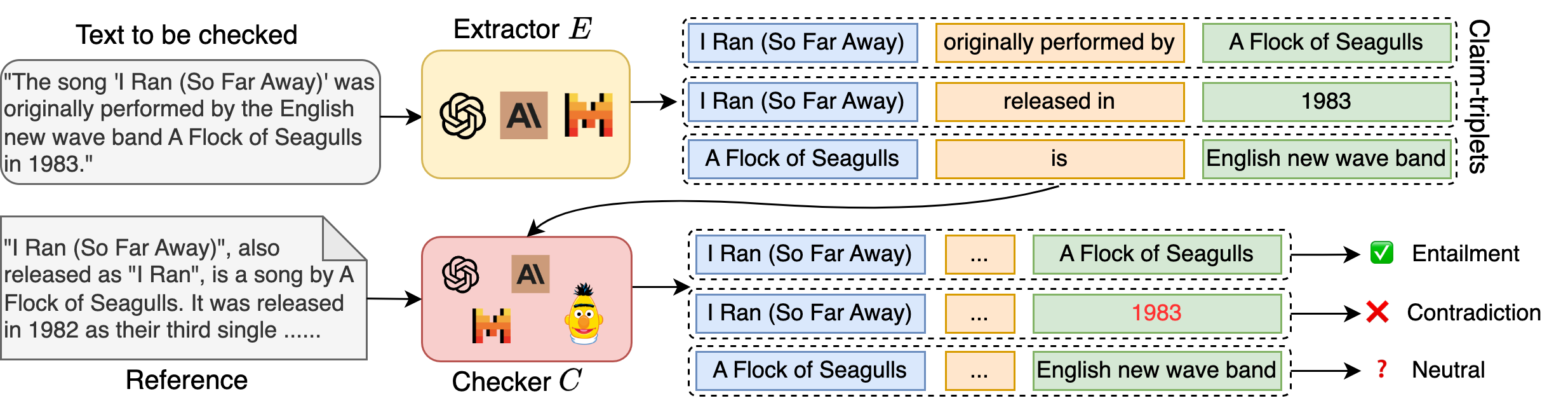
The RefChecker pipeline flow from input response to final hallucination assessment.
Evaluation Highlights
- RefChecker (Claude 2 + GPT-4) outperforms the best prior method (FacTool) by 6.8 to 26.1 points in correlation with human judgment
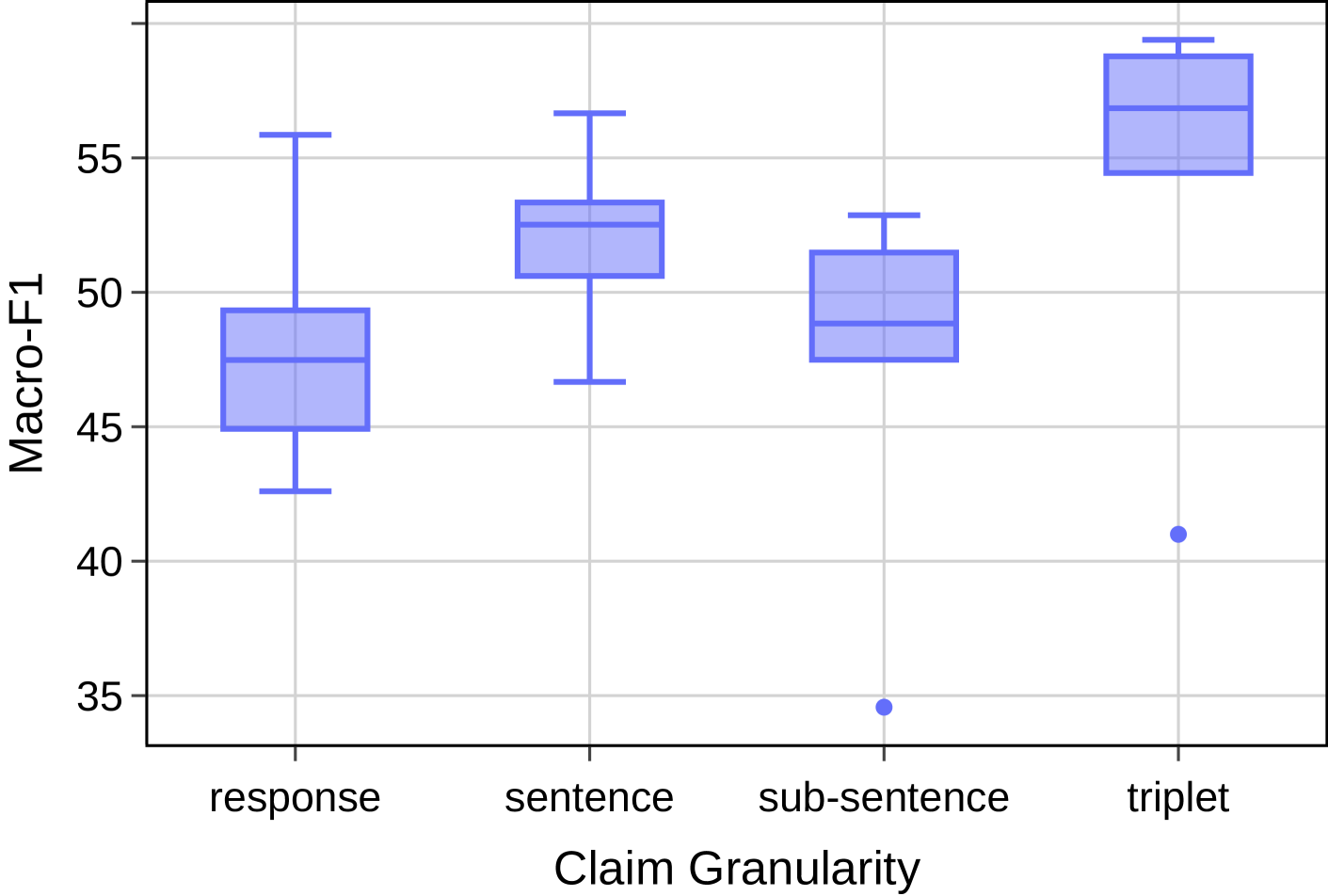
- Checking at the triplet level improves detection performance by 4 to 9 points compared to response, sentence, or sub-sentence granularities
- Using a fine-tuned open-source model (Mistral 7B) as a checker achieves strong correlation with human annotations, offering a cost-effective alternative to proprietary models
Breakthrough Assessment
8/10
Significantly refines the unit of analysis for hallucination. The shift to triplets is intuitively sound and empirically validated as superior to sentence-level checks. The release of a fine-grained benchmark with 11k annotations is a major resource contribution.