📝 Paper Summary
Hallucination detection in RAG
Automated evaluation of faithfulness
FaithJudge improves automated hallucination detection in RAG by prompting an LLM judge with a pool of human-annotated peer responses to the same source text.
Core Problem
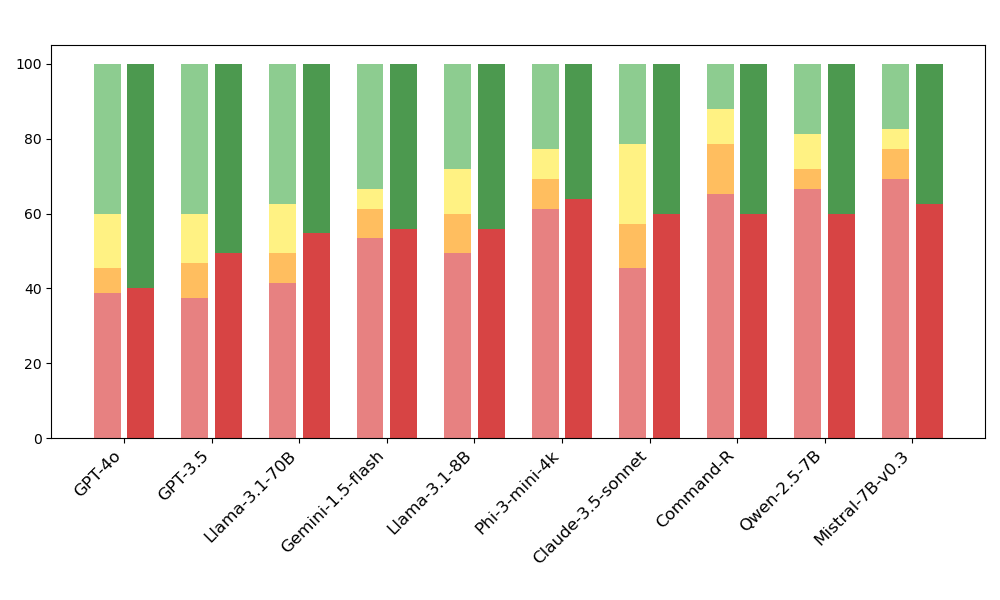
Existing automated hallucination detection methods, including fine-tuned models and zero-shot LLM judges, struggle to accurately identify unfaithful RAG responses, often achieving near-random accuracy on challenging datasets.
Why it matters:
- LLMs frequently generate false or misleading information even when provided with trusted contexts (RAG), undermining user trust
- Human annotation is accurate but expensive and unscalable, while current automated metrics have low agreement with human judgments
- Benchmarks like FaithBench show current methods achieve near 50% accuracy, suggesting negligible ability to reliably identify hallucinations
Concrete Example:
When summarising an article, an LLM might introduce details unsupported by the retrieved context. Current detectors like GPT-4o (zero-shot) or AlignScore often fail to flag this, whereas FaithJudge uses other annotated summaries of the same article to correctly identify the error.
Key Novelty
Context-Aware Peer-Review Judge (FaithJudge)
- Recasts evaluation by providing the judge LLM with several *other* human-annotated responses to the *same* source text/query as few-shot examples
- Leverages the diversity of hallucinations found in peer responses (from different models) to teach the judge specific pitfalls for that specific context without model training
Architecture
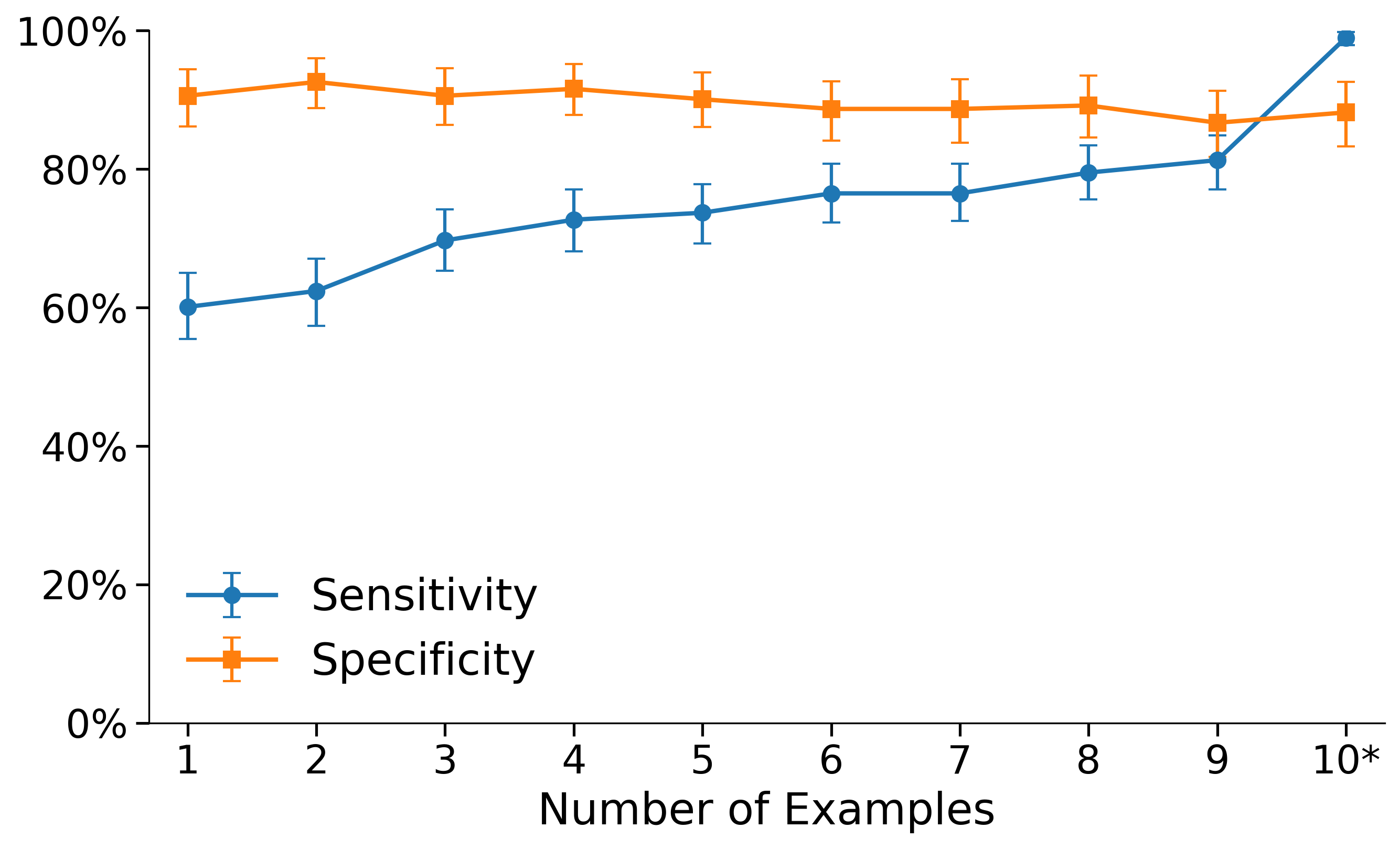
Impact of the number of annotated examples on FaithJudge's performance (Sensitivity vs Specificity).
Evaluation Highlights
- FaithJudge (using o3-mini-high) achieves 84.0% balanced accuracy on FaithBench, significantly outperforming GPT-4o (zero-shot) at 77.1%
- Achieves 82.1% F1-macro on FaithBench, surpassing the best fine-tuned detector (MiniCheck-7B at 61.2%) and best zero-shot judge (GPT-4o at 71.3%)
- Demonstrates strong generalization across RAG tasks: 87.5% balanced accuracy on RAGTruth QA compared to 76.9% for the FACTS Grounding baseline
Breakthrough Assessment
7/10
Significant improvement in automated evaluation accuracy by changing the prompting paradigm (peer-review context). Heavy reliance on having existing annotations for the same source limits immediate zero-shot applicability on unseen data.