📝 Paper Summary
Hallucination detection
Model testing/evaluation
Fact-conflicting hallucination (FCH)
Drowzee automatically generates diverse test cases by mutating factual knowledge using logic programming rules and detects hallucinations by verifying the logical consistency of LLM reasoning against ground truth.
Core Problem
Detecting Fact-Conflicting Hallucination (FCH) is difficult because manually maintaining up-to-date benchmarks is labor-intensive, and validating the reasoning behind LLM answers (not just the final output) is inherently complex.
Why it matters:
- Static manual benchmarks rapidly become obsolete as knowledge evolves, limiting detection adaptability and scalability
- LLMs may produce correct final answers via faulty reasoning (false understanding), masking underlying hallucination tendencies that pose security risks
- Existing naive detection methods (like string matching) struggle to verify complex logical relations in generated text
Concrete Example:
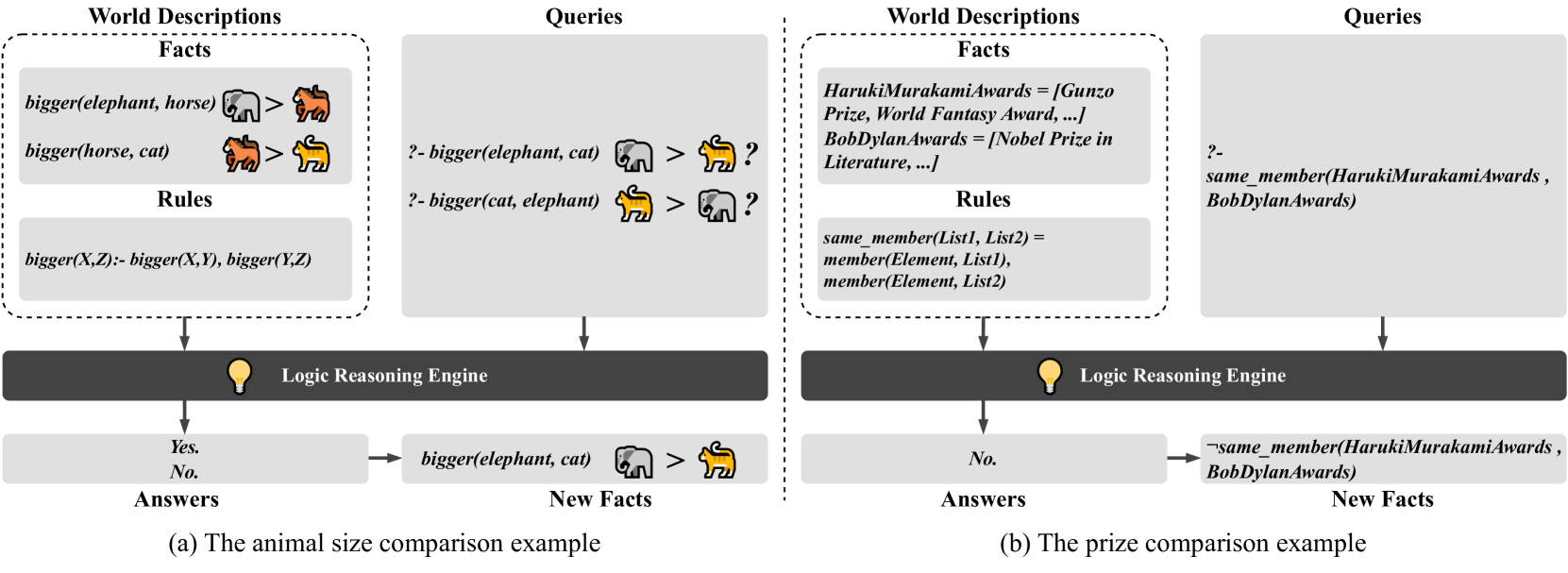
If a user asks about Haruki Murakami winning a Nobel Prize, a model might correctly say 'No' but justify it with a hallucinated reason (e.g., 'He won in 2016'), which simple answer-matching would miss. Drowzee's logic-based approach detects this inconsistency.
Key Novelty
Logic-Programming-Aided Metamorphic Testing for FCH
- Uses logic programming (Prolog-style rules) to transform seed facts (e.g., 'A is bigger than B') into new, complex test cases (e.g., 'Is B smaller than A?') with automatically derived ground truth.
- Validates LLM outputs not by exact string matching, but by extracting semantic structures and comparing their logical relationships to the ground truth using specialized 'oracles'.
- Automates the entire pipeline from knowledge crawling to test case generation and result verification, removing the need for human annotation.
Architecture

Conceptual workflow of Drowzee compared to manual benchmarking. Shows the transformation of seed facts into complex questions via logic programming.
Evaluation Highlights
- Detected hallucination rates ranging from 24.7% to 59.8% across six major LLMs (including GPT-4 and Llama-2)
- Identified that lack of logical reasoning capability is the primary contributor to Fact-Conflicting Hallucination (FCH) issues in LLMs
- Demonstrated that model editing on identified hallucinations (fewer than 1000 edits) effectively mitigates specific FCH instances on a small scale
Breakthrough Assessment
8/10
Significant methodology for automating hallucination benchmarks. By moving from static Q&A to logic-based dynamic generation, it solves the stale-benchmark problem, though reliance on external knowledge bases (Wikipedia) remains a dependency.