📝 Paper Summary
Benchmark datasets
Agentic AI
Tool-use evaluation
ToolQA is a benchmark designed to evaluate Large Language Models' ability to answer questions using external tools by ensuring reference data has minimal overlap with pre-training corpora.
Core Problem
Existing tool-use evaluations often fail to distinguish whether LLMs are truly using tools or simply recalling memorized facts from pre-training data.
Why it matters:
- Evaluations biased by data contamination cannot accurately reflect a model's true reasoning and tool-use competency
- LLMs suffer from hallucination and weak numerical reasoning when relying solely on internal weights
- Distinguishing between memorization and actual problem-solving is critical for developing reliable agents
Concrete Example:
If an LLM is asked about flight data, it might answer correctly using memorized historical schedules rather than querying a flight database tool. ToolQA prevents this by using recent or synthetic data (e.g., specific flight status on '01/09/22') that the model could not have memorized.
Key Novelty
ToolQA Benchmark Construction
- Curates 8 reference corpora (text, tables, graphs) specifically selected to have minimal overlap with LLM pre-training data (e.g., recent logs, synthetic personal agendas)
- Defines 13 specialized tools (SQL interpreter, graph loader, math calculator) required to extract answers from these corpora
- Uses a template-based 'Human-Guided Question Generation' process where humans validate templates and algorithms instantiate them with specific values to ensure tool necessity
Architecture
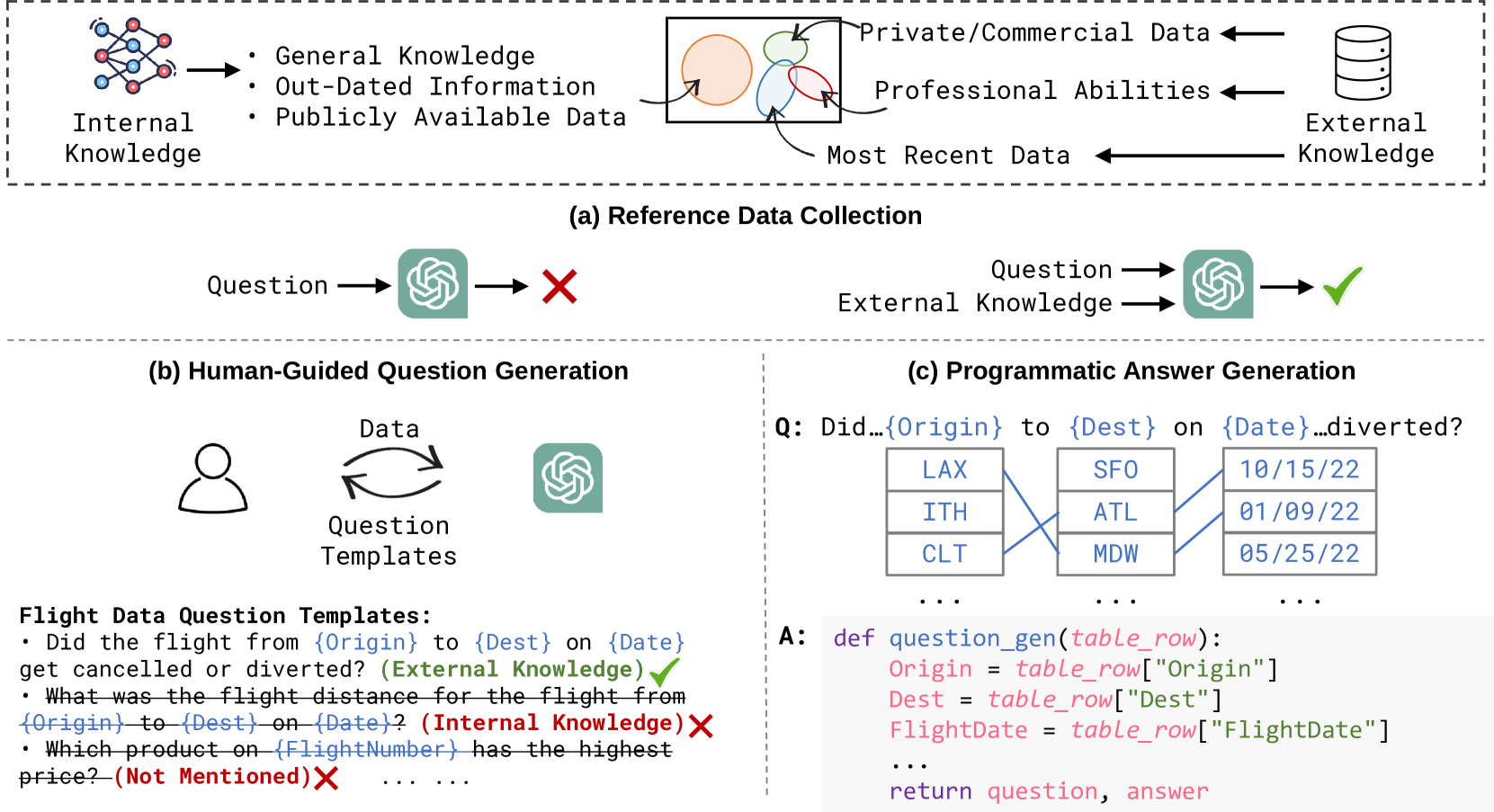
The three-phase dataset curation process for ToolQA.
Evaluation Highlights
- Standard ChatGPT and Chain-of-Thought (CoT) fail almost completely (<5% success) because they cannot access the external knowledge required
- Tool-augmented ReAct outperforms baselines significantly on easy questions (43.15%) but struggles on hard questions (8.2%)
- Hard questions involving complex reasoning and tool composition remain a major challenge for current state-of-the-art tool-use methods
Breakthrough Assessment
8/10
Addresses the critical issue of data contamination in tool-use evaluation. The rigorous construction process ensures models must use tools, providing a more faithful measure of agentic capability.