📊 Experiments & Results
Evaluation Setup
Few-shot (4-shot) prompting on NLI datasets with controlled transformations to isolate biases
Benchmarks:
- Levy/Holt (Directional predicate entailment)
- RTE-1 (General textual entailment)
- Random Premise Task (IRandPrem) (Adversarial NLI (all labels are No-Entail)) [New]
Metrics:
- Estimated Probability of predicting Entail (conditioned on bias)
- Recall (across entity transformations)
- AUC norm (Area Under Precision-Recall Curve, normalized)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Experiment 1: Attestation Bias. Models are much more likely to incorrectly predict Entailment on random premises if the hypothesis is attested (memorized). | ||||
| Levy/Holt (Random Premise) | Ratio of False Positive Probability (Attested vs Unattested) | 1.0 | 1.9 | +0.9 |
| Levy/Holt (Random Premise) | Ratio of False Positive Probability (Attested vs Unattested) | 1.0 | 2.2 | +1.2 |
| Experiment 2: Entities as Indices. Recall drops significantly when original entities are replaced, even if type constraints preserve semantic validity. | ||||
| Levy/Holt | Recall | 92.3 | 55.3 | -37.0 |
| Levy/Holt | Recall | 76.2 | 52.4 | -23.8 |
| Impact on Performance (AUC norm). Models perform near-randomly when the attestation bias contradicts the gold label. | ||||
| Levy/Holt (Standard I) | AUC norm | 65.5 | 8.1 | -57.4 |
| Levy/Holt (Standard I) | AUC norm | 85.0 | 10.8 | -74.2 |
| Levy/Holt (Standard I) | AUC norm | 79.1 | 31.5 | -47.6 |
Experiment Figures
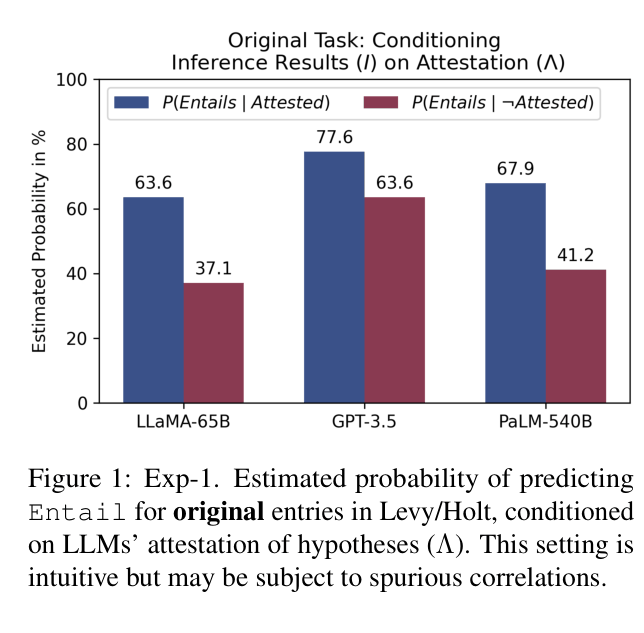
Bar chart showing the probability of predicting Entail for original Levy/Holt entries conditioned on whether the model attests (memorizes) the hypothesis
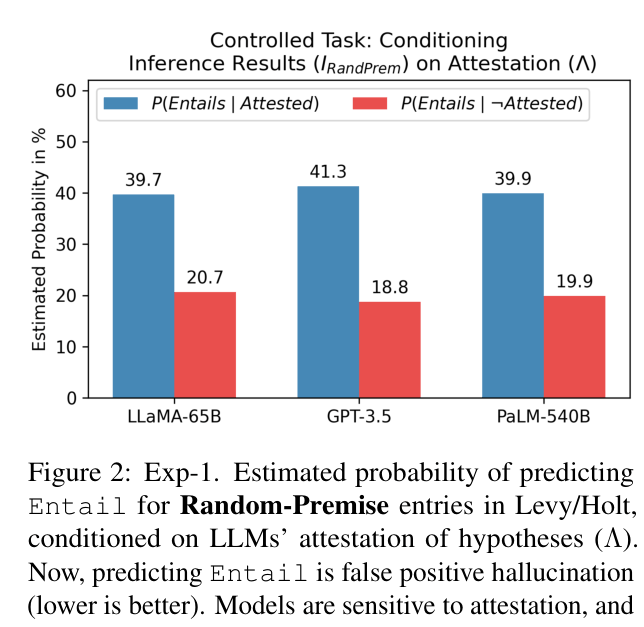
Bar chart for the 'Random Premise' task (where all correct labels are No-Entail). Shows probability of false positive Entailment conditioned on Attestation.
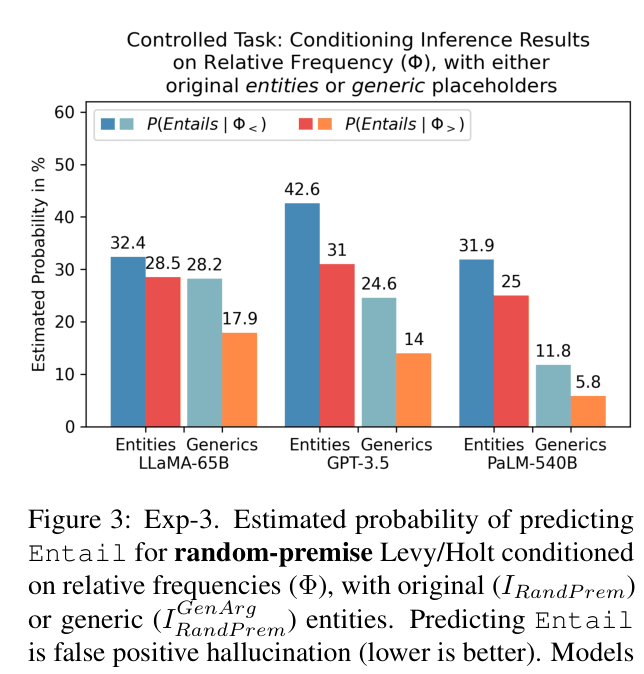
Bar chart showing the probability of false positive Entailment on random premises conditioned on Relative Frequency Bias (Φ)
Main Takeaways
- LLMs consistently use named entities as 'indices' to recall memory; performance degrades when these entities are swapped, even if the logic remains identical
- A relative frequency bias (Φ) exists where models prefer entailments where the premise is less frequent than the hypothesis (specific -> general); this bias becomes more pronounced when entity-based memory is unavailable
- High aggregate NLI scores mask severe fragility: models are excellent when biases align with labels (Consistent) but fail catastrophically when they conflict (Adversarial)
- These biases appear across LLaMA, PaLM, and GPT-3.5, indicating they stem from the pre-training objective on natural text rather than fine-tuning