📝 Paper Summary
Data Curation
Multilingual NLP
JQL is a systematic pipeline for filtering multilingual pre-training data by distilling the quality judgments of large LLMs into lightweight, embedding-based regressors that generalize across languages.
Core Problem
High-quality multilingual data is scarce, and existing filtering methods rely on heuristics or English-centric classifiers that fail to scale or generalize to low-resource languages.
Why it matters:
- Pre-training data quality is a primary factor in LLM performance and training efficiency
- Current state-of-the-art curation strategies are often closed-source, hindering reproducibility
- Heuristic filters (like length or keyword checks) often discard high-quality content in low-resource languages or retain low-quality noise
Concrete Example:
A standard heuristic filter might reject a short but highly educational math tutorial in Basque because it fails a length threshold or lacks specific keywords, whereas JQL's embedding-based model correctly identifies its educational value by projecting it into a shared semantic space.
Key Novelty
Judging Quality across Languages (JQL)
- Distills the quality-judging capabilities of large 'teacher' LLMs (like Llama-3-70B) into lightweight 'student' regressors built on top of pre-trained multilingual text embeddings
- Uses a fixed cross-lingual embedding space (Snowflake Arctic) to enable zero-shot transfer, allowing the lightweight model to judge quality even in languages it wasn't explicitly trained on
Architecture
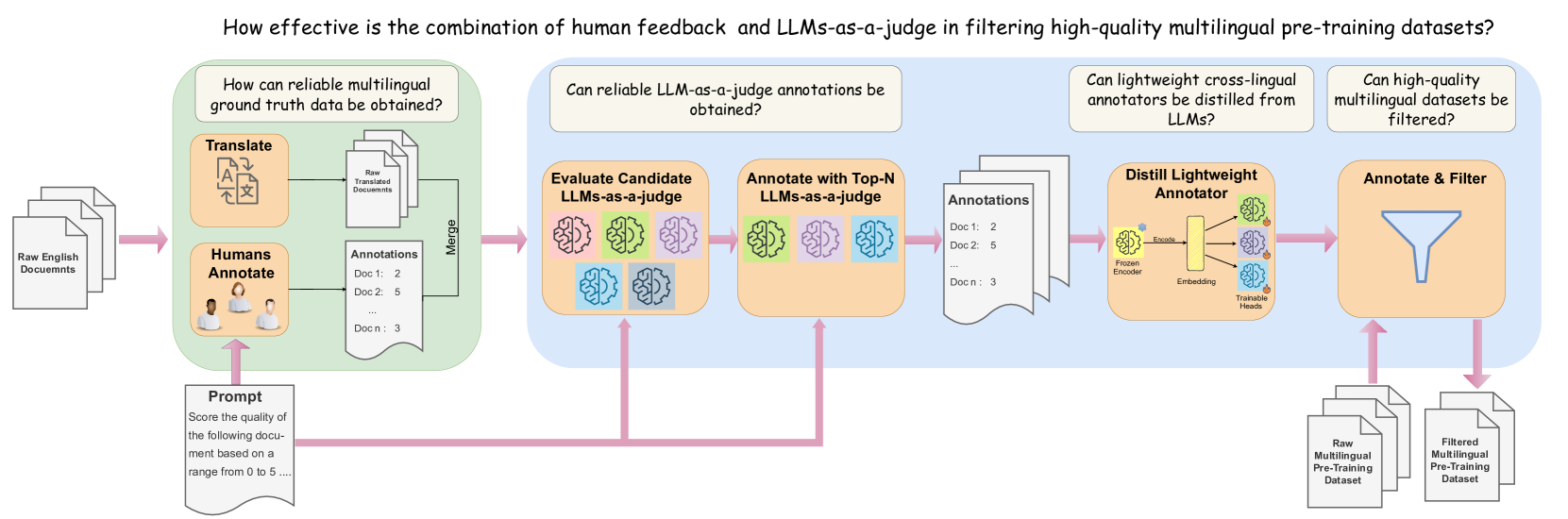
The four-stage JQL pipeline: (1) Human Annotation, (2) LLM Evaluation, (3) Distillation into Lightweight Annotators, (4) Filtering.
Evaluation Highlights
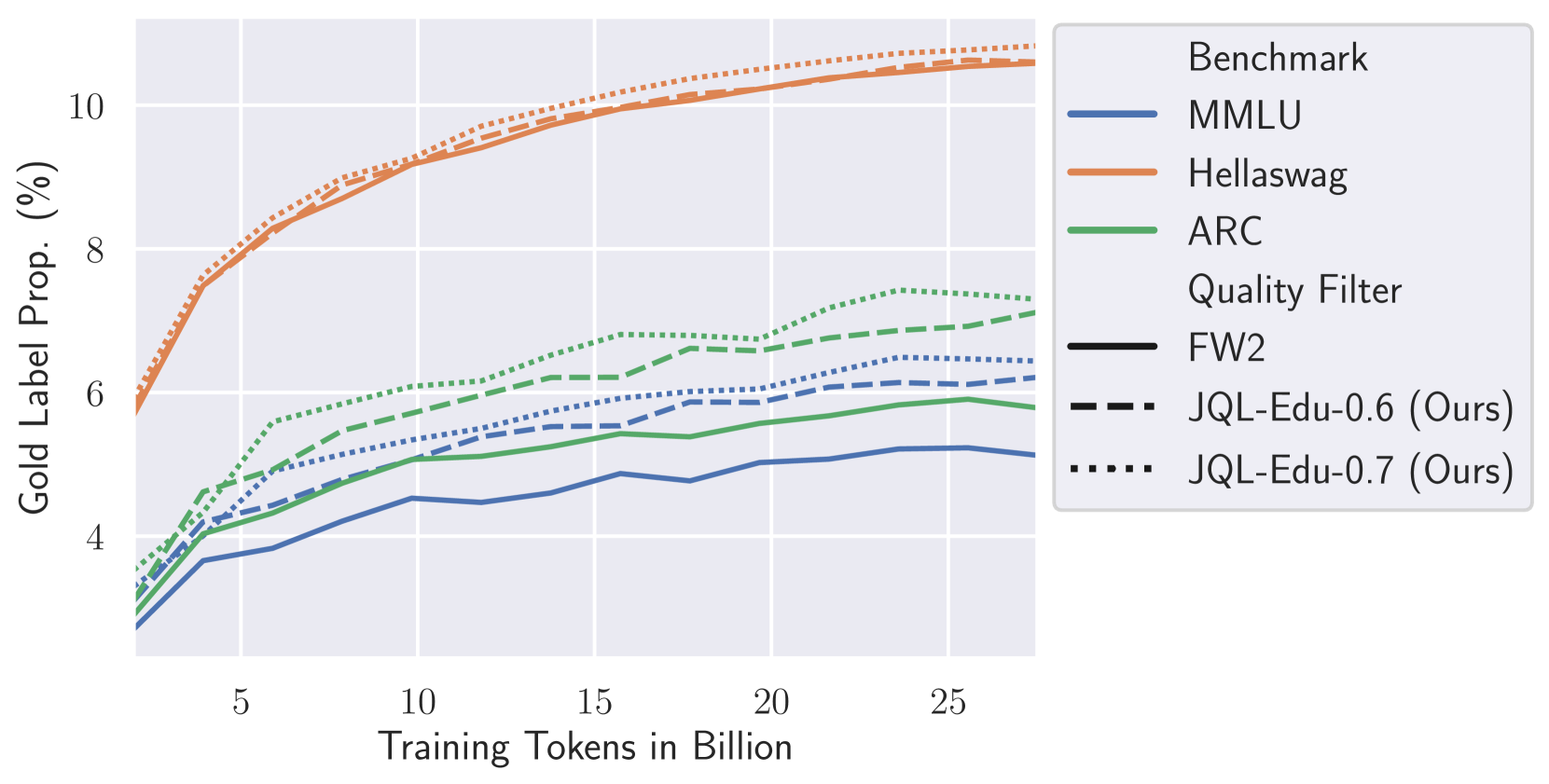
- Retains >9% more tokens than the Fineweb2 heuristic baseline for Spanish while achieving higher downstream model performance
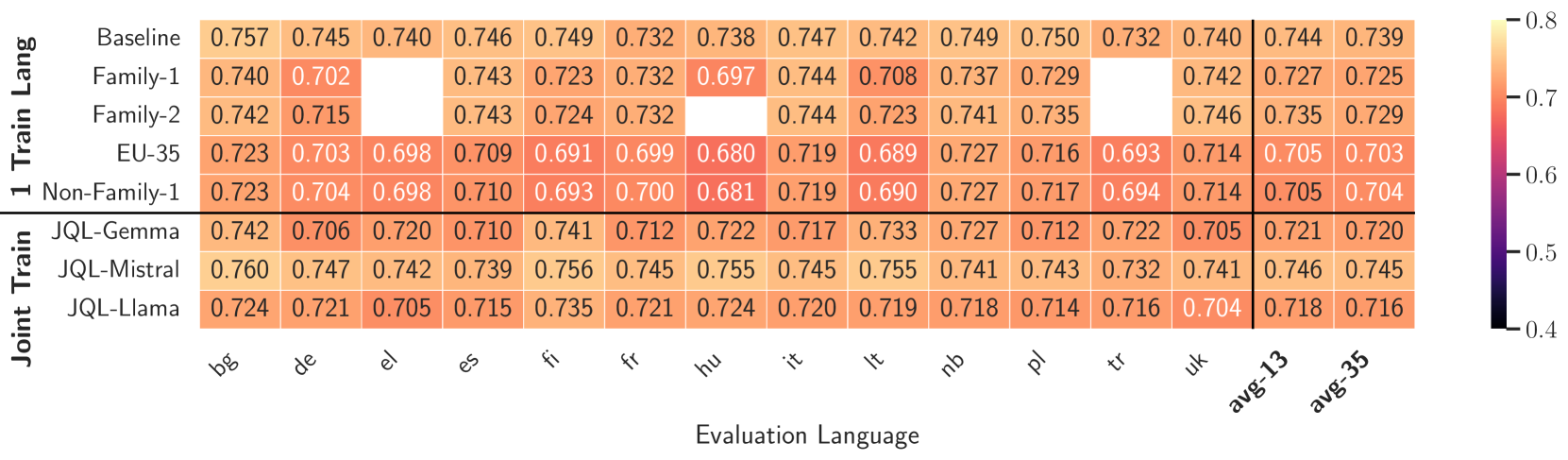
- JQL-filtered data consistently outperforms Fineweb2 heuristic baselines across 13 diverse European languages on MMLU, HellaSwag, and ARC benchmarks
- Lightweight annotators achieve Spearman correlation >0.87 with teacher LLMs, successfully preserving the relative ranking of document quality at a fraction of the compute cost
Breakthrough Assessment
8/10
Provides a reproducible, open-source recipe for high-quality multilingual data curation, significantly outperforming heuristics and addressing the critical data scarcity bottleneck for non-English languages.