📝 Paper Summary
LLM Alignment
Learning Dynamics
Preference Optimization
The paper analyzes how updating LLM parameters affects predictions on other examples, revealing a 'squeezing effect' in off-policy DPO where negative gradients on unlikely responses depress confidence across all outputs.
Core Problem
Understanding why specific finetuning algorithms (like DPO) cause phenomena like hallucinations, repetition, or decaying confidence in desired outputs, which are not explained by static loss analysis.
Why it matters:
- Off-policy DPO often causes model confidence to decay for both chosen and rejected responses, degrading performance over time
- Standard static analysis (viewing the final loss landscape) fails to explain dynamic behaviors like the 'zig-zag' learning path or why on-policy sampling is crucial
- Hallucinations often increase after finetuning, but the mechanism for why specific types of hallucinations (e.g., mixing up facts between questions) occur is poorly understood
Concrete Example:
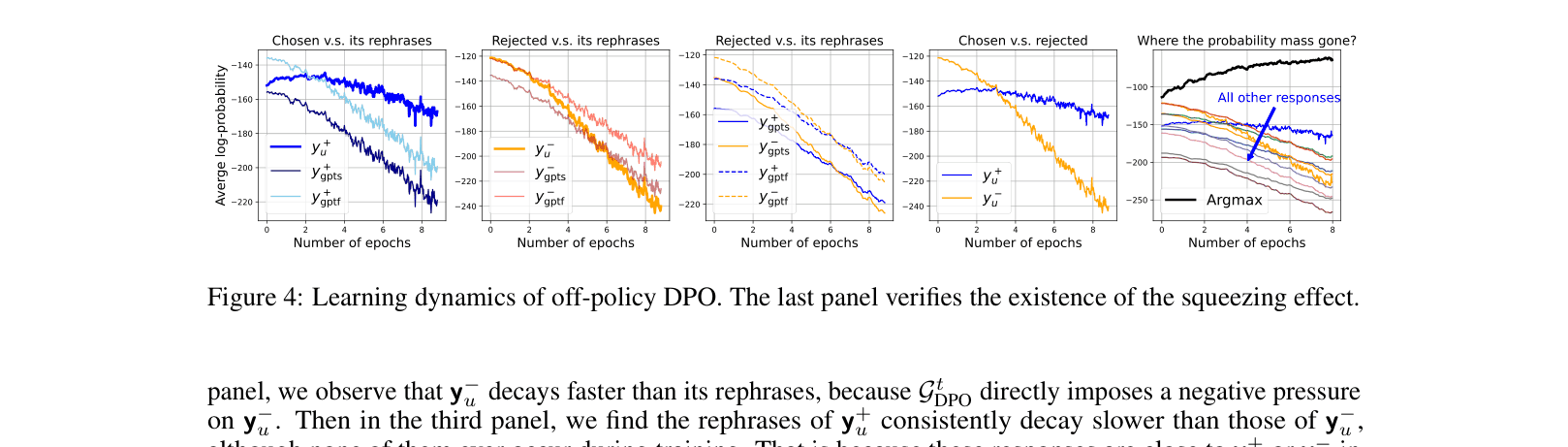
In off-policy DPO, applying a large negative gradient to a rejected response 'y-' that the model already considers unlikely causes the probability of *all* other responses (including the chosen one) to drop, squeezing mass into the single most-likely token (often leading to repetitive loops).
Key Novelty
Learning Dynamics Decomposition & Squeezing Effect
- Decomposes the change in prediction into three terms: current prediction matrix, empirical Neural Tangent Kernel (similarity between examples), and the residual vector (direction of update)
- Identifies the 'squeezing effect': when softmax models receive negative gradients on unlikely labels, probability mass is disproportionately shifted to the single most confident label, rather than distributed broadly
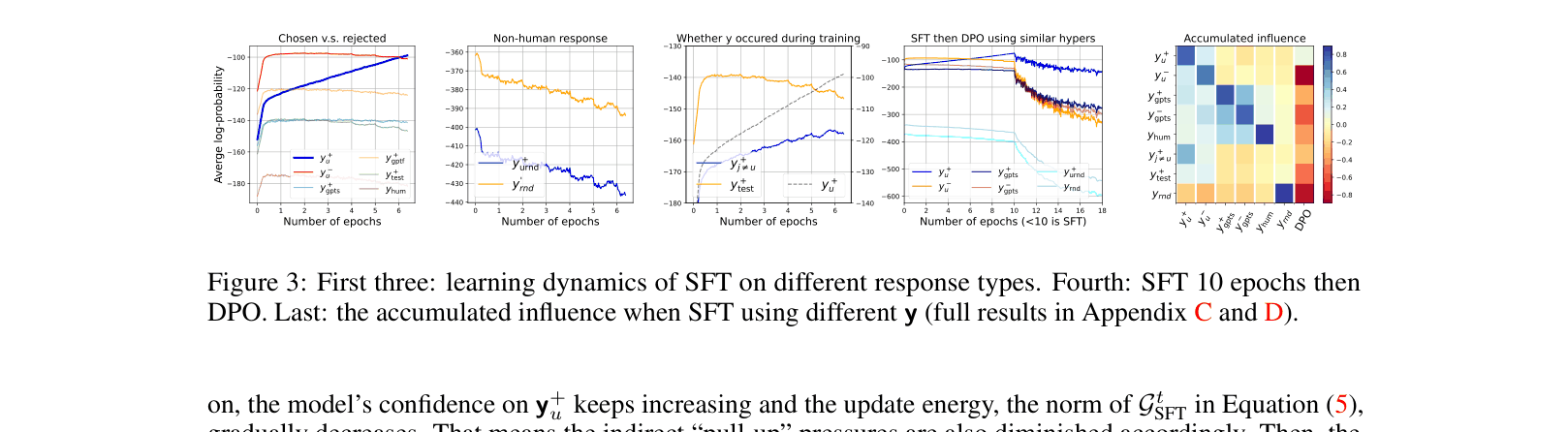
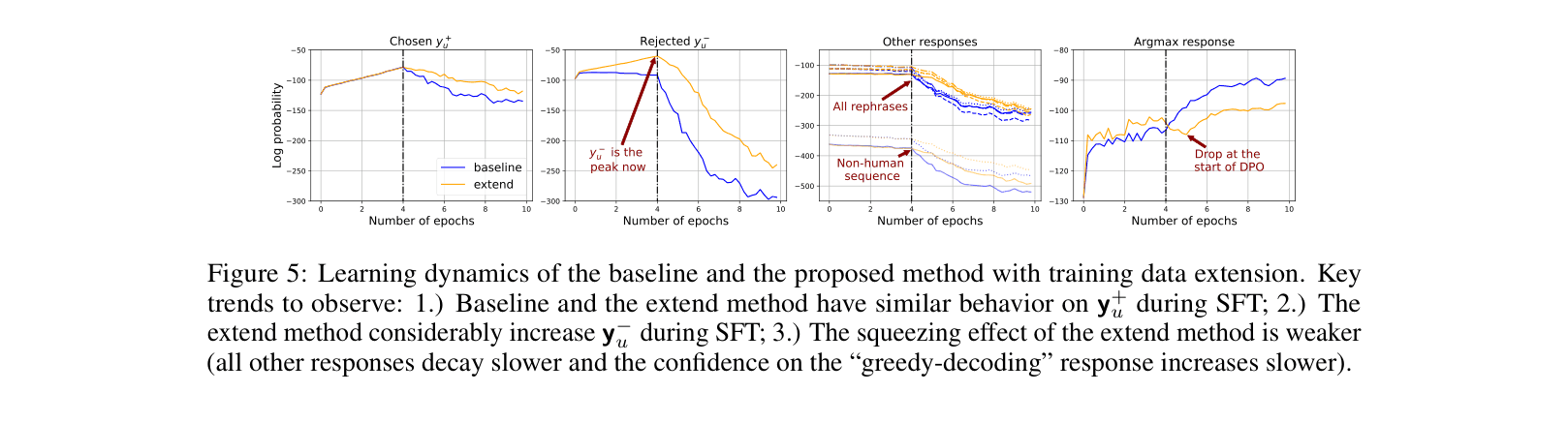
- Demonstrates that SFT on '[question, chosen]' increases confidence for 'chosen' AND 'rejected' responses (due to similarity), whereas DPO pushes down 'rejected' and indirectly its neighbors
Architecture
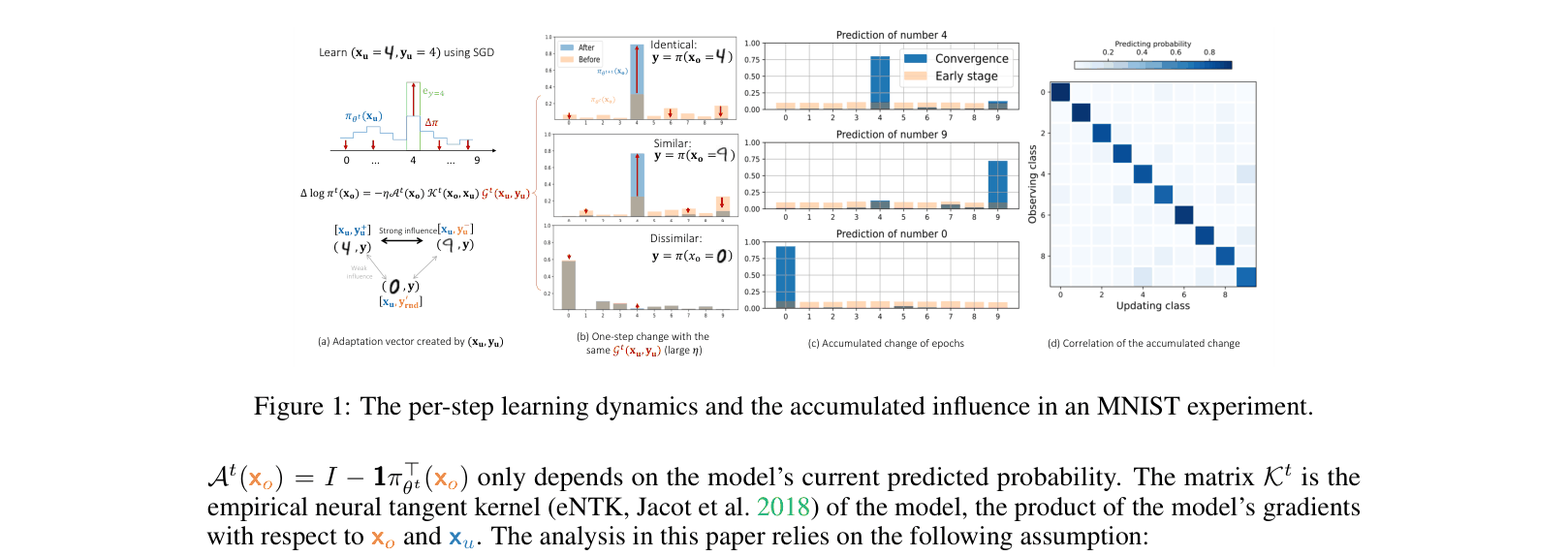
Conceptual visualization of learning dynamics on MNIST to illustrate the framework.
Evaluation Highlights
- The proposed 'extend' method (training on negative responses during SFT) achieves a ~69% win rate against baseline DPO (4 epochs) on Pythia-2.8B evaluated by ChatGPT
- In off-policy DPO, the log-probability of the chosen response 'y+' typically drops from -90 to -113, while greedy decoding probability spikes from -113 to -63 (indicating peaking/squeezing)
- Standard SFT increases confidence on hallucinated responses (answers from other training questions) steadily, verifying the cross-sample influence mechanism
Breakthrough Assessment
8/10
Provides a strong theoretical framework explaining mysterious empirical phenomena (DPO confidence decay, repeater problem). The 'squeezing effect' is a fundamental insight into softmax-based learning dynamics.