📝 Paper Summary
Hallucination suppression
Modularized RAG pipeline
LettuceDetect is a lightweight, encoder-based hallucination detection framework built on ModernBERT that achieves state-of-the-art accuracy while being 30 times smaller than comparable LLM-based solutions.
Core Problem
RAG systems suffer from extrinsic hallucinations where answers are not supported by retrieved context, and existing detectors are either computationally expensive (LLM-based) or context-limited (traditional encoder-based).
Why it matters:
- LLMs in high-risk settings like medicine or law cannot be trusted if they prioritize intrinsic knowledge over retrieved evidence (extrinsic hallucination)
- Current LLM-based judges (like GPT-4) are too slow and costly for real-time applications
- Traditional BERT-based encoders have short context windows (512 tokens), insufficient for analyzing long RAG retrieval contexts
Concrete Example:
In a RAG scenario, an LLM might answer a question about a specific business using its pre-trained knowledge rather than the retrieved Yelp review, leading to factual contradictions. Existing tools might miss this due to context truncation or be too slow to catch it before the user sees the response.
Key Novelty
ModernBERT-based Token Classification for Hallucination
- Adapts the ModernBERT architecture (capable of 8k context) for the specific task of binary token classification (supported vs. hallucinated) within RAG triples (context, question, answer)
- Replaces the heavy reliance on NLI (Natural Language Inference) pre-training used by prior encoder methods (like Luna) with direct supervised training on RAG-specific hallucination data
Architecture
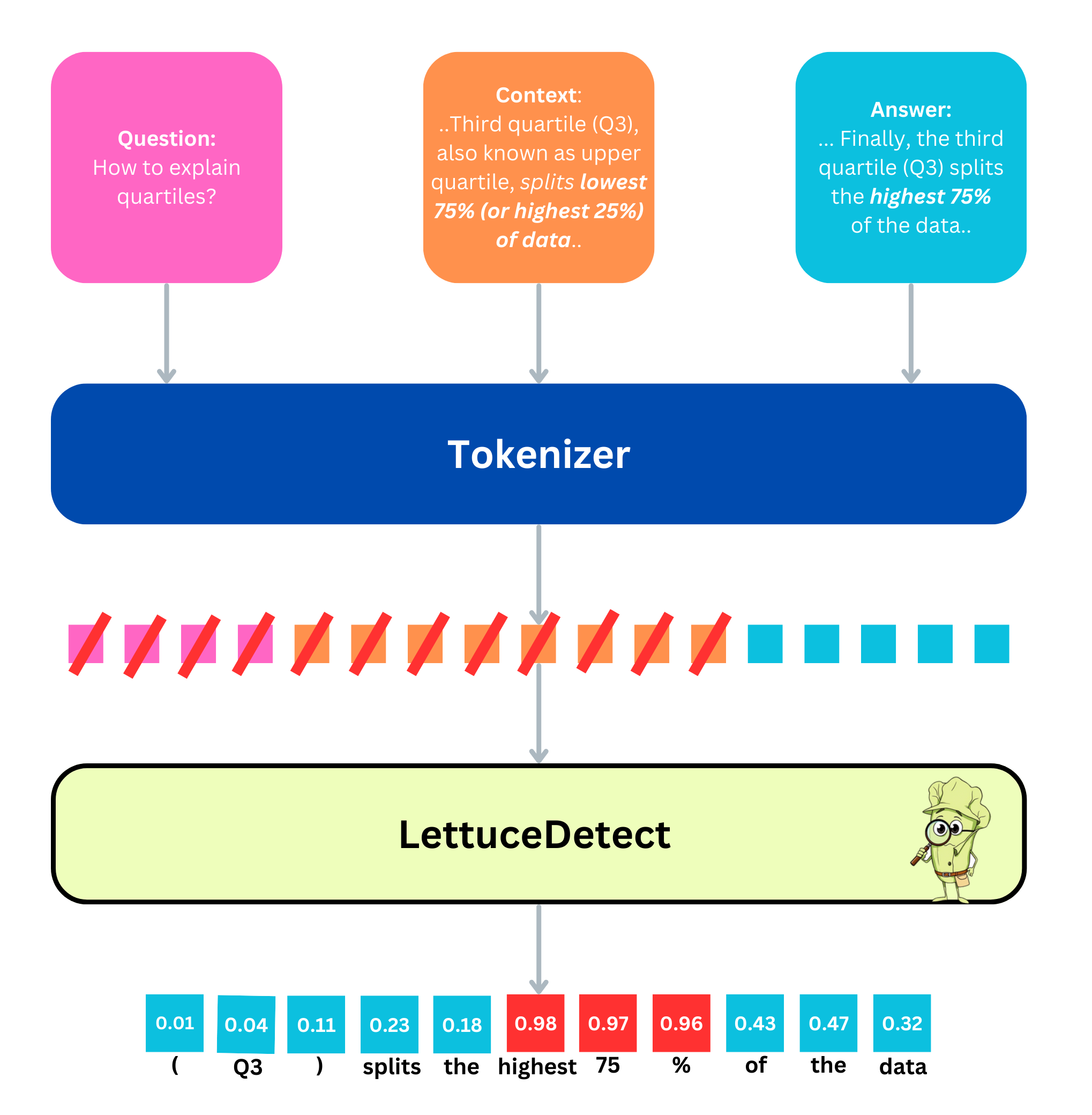
The token-classification architecture of LettuceDetect.
Evaluation Highlights
- Achieves 79.22% F1 score on RAGTruth example-level detection, outperforming GPT-4 Turbo (63.4%) and the previous best encoder model Luna (65.4%)
- Processes 30-60 examples per second on a single A100 GPU, making it viable for real-time deployment unlike LLM-based judges
- Surpasses fine-tuned Llama-2-13B (78.7%) despite being approximately 30 times smaller (396M parameters vs 13B)
Breakthrough Assessment
7/10
Significant practical breakthrough for production RAG systems. It proves that small, specialized encoders can beat GPT-4 at hallucination detection if they handle long contexts properly, solving a major efficiency bottleneck.