📝 Paper Summary
Hallucination detection
Long-context processing
A novel architecture enables standard encoder models (like BERT) to detect hallucinations in long contexts by decomposing inputs into chunks and aggregating their representations, outperforming LLM-based judges with significantly faster inference.
Core Problem
Existing methods for detecting contextual hallucinations struggle with long inputs: encoder models (BERT) are limited to 512 tokens, while LLM-based judges are computationally expensive and slow.
Why it matters:
- LLMs frequently generate plausible but unfaithful summaries when processing long documents, undermining trust in automated systems
- Current NLI-based detectors cannot process full book chapters due to token limits, missing context needed for verification
- Deploying LLMs as judges for every output is too slow and costly for real-time applications
Concrete Example:
When verifying a summary of a 5,000-token book chapter, a standard BERT model truncates the input, potentially missing the evidence needed to flag a contradiction. An LLM judge might catch it but takes seconds to process, whereas this method processes it in milliseconds.
Key Novelty
Decomposition-Aggregation Encoder Framework
- Decomposes long context and response pairs into smaller fixed-length chunks that fit within standard encoder limits (e.g., 512 tokens)
- Independently encodes each chunk using a frozen or fine-tuned backbone (like BERT) to get chunk-level representations
- Aggregates these representations using a learned attention and pooling layer to produce a single hallucination score, bypassing quadratic attention complexity
Architecture
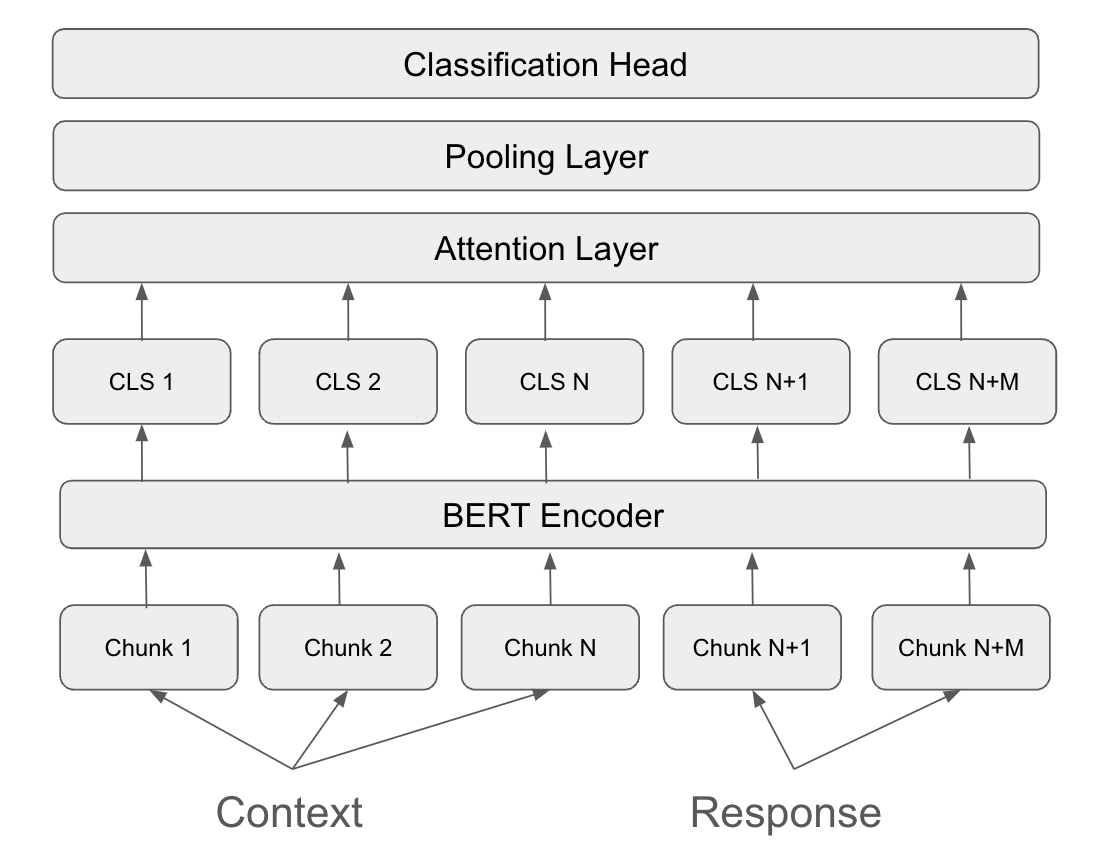
The model architecture showing the decomposition, encoding, and aggregation pipeline.
Evaluation Highlights
- Outperforms GPT-4o on the constructed BookSum-Hallucination dataset (AUC 0.77 vs 0.73) while being ~20x faster
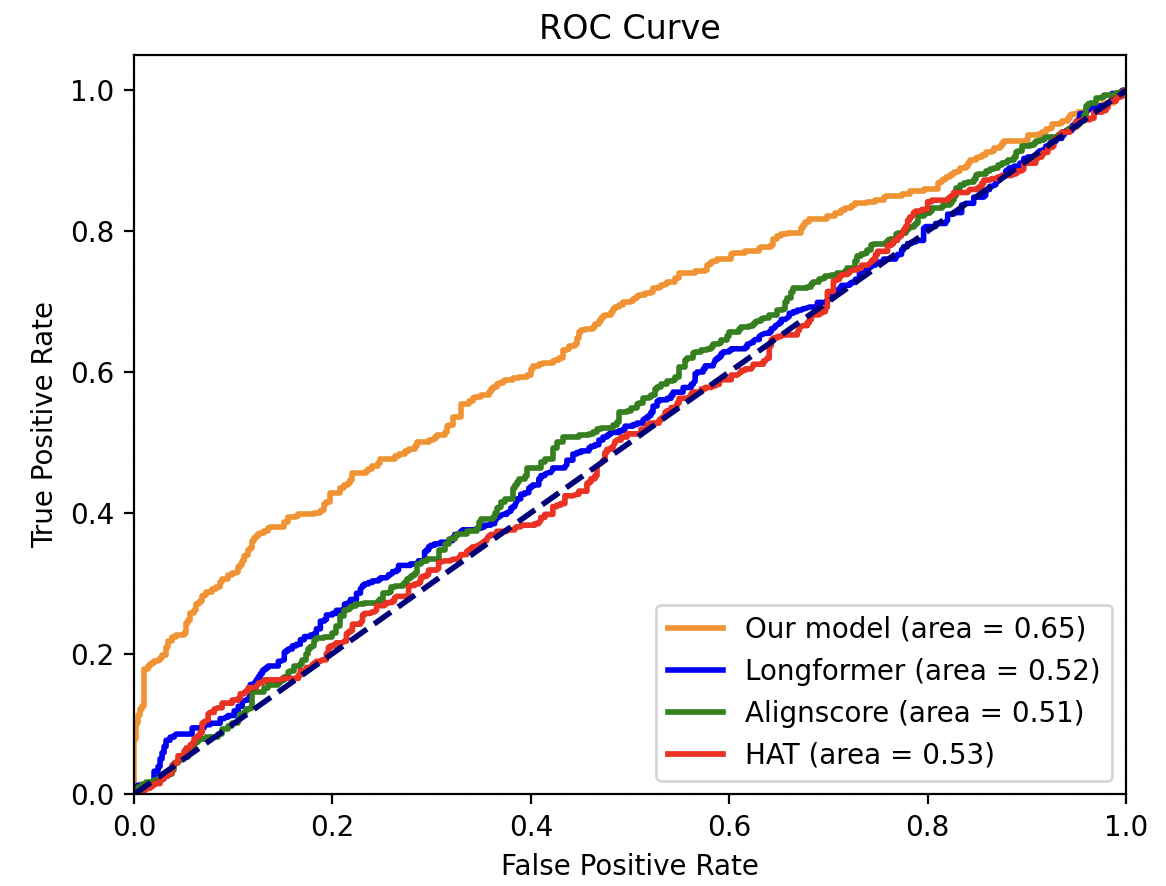
- Surpasses long-context baselines like Longformer (AUC 0.52) and HAT (AUC 0.53), which failed to learn discriminative features
- Achieves 80% recall with high precision, whereas baselines like Longformer suffer from extremely low precision (high false positives)
Breakthrough Assessment
7/10
Strong practical contribution addressing the high cost of LLM-based evaluation. The method is simple but effective, significantly outperforming larger models in efficiency and accuracy on the specific task.