📝 Paper Summary
Hallucination detection
Factuality assessment
SelfCheckGPT detects hallucinations in black-box LLMs by checking if stochastically sampled responses are consistent with the model's primary response, without requiring external databases or internal model states.
Core Problem
Existing hallucination detection methods often require access to internal token probabilities (unavailable for black-box APIs like ChatGPT) or rely on external databases, which are complex to maintain and interface.
Why it matters:
- LLMs frequently generate fluent but non-factual statements (hallucinations), undermining trust in critical applications like medical or legal drafting
- Users of commercial APIs (e.g., ChatGPT) often lack access to the log-probabilities required for traditional uncertainty metrics
- Retrieval-based verification is limited by the coverage of external databases and cannot easily assess general generative tasks beyond pure fact-checking
Concrete Example:
If an LLM hallucinates that 'John Smith is a carpenter', stochastic samples might say he is a 'baker' or 'driver', revealing inconsistency. If it knows he is 'Lionel Messi', samples will consistently say 'footballer'.
Key Novelty
Self-Consistency as a Proxy for Factuality
- Leverages the intuition that if an LLM truly knows a concept, sampled responses will be factually consistent; if it hallucinates, samples will diverge and contradict each other
- Operates in a zero-resource setting: requires only the LLM itself, avoiding the need for external reference documents or search engines
- Works for black-box models: relies entirely on generated text samples rather than requiring access to the model's logits or hidden states
Architecture
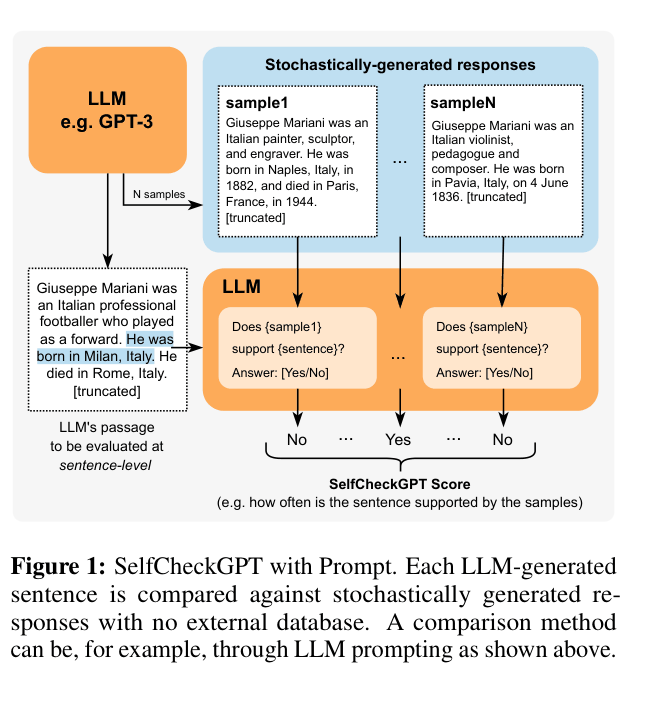
Overview of the SelfCheckGPT-Prompt pipeline. The LLM generates a main passage and N samples. Each sentence in the main passage is checked against each sample using a prompt to ask if the sample supports the sentence.
Evaluation Highlights
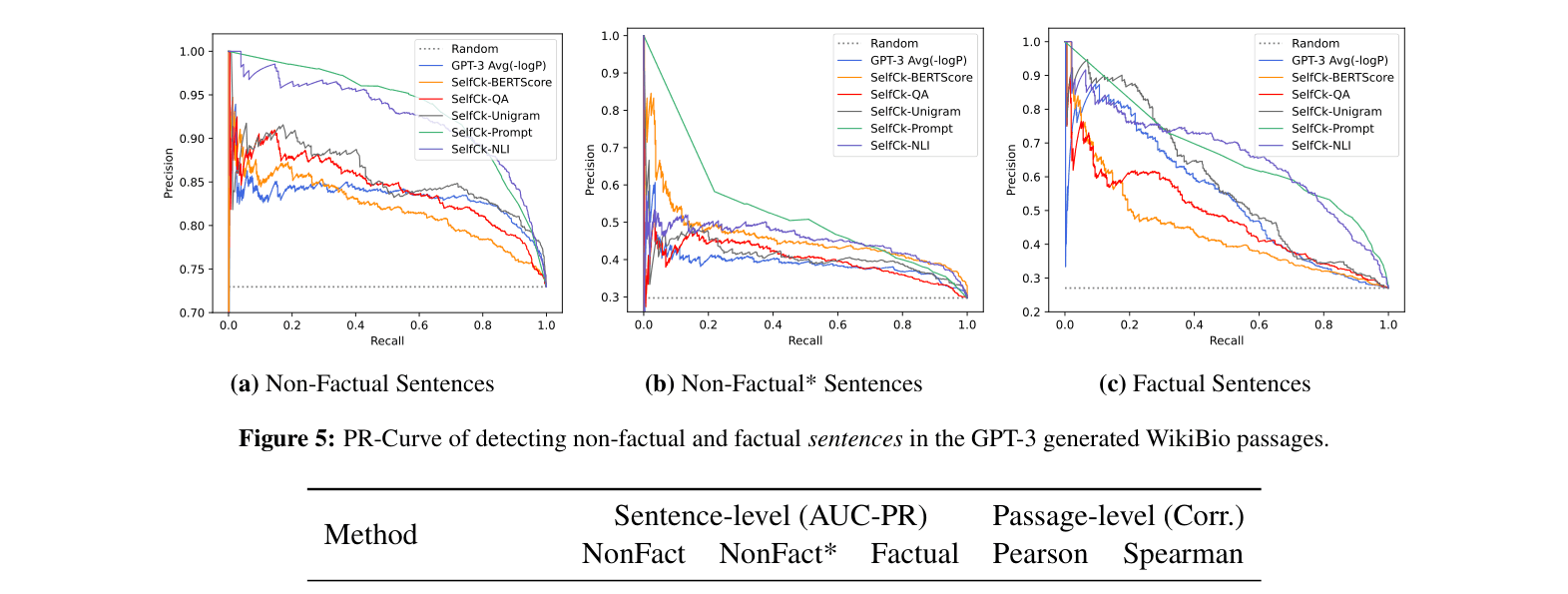
- SelfCheckGPT-Prompt achieves 93.42 AUC-PR in detecting non-factual sentences, outperforming grey-box probability baselines (83.21 AUC-PR)
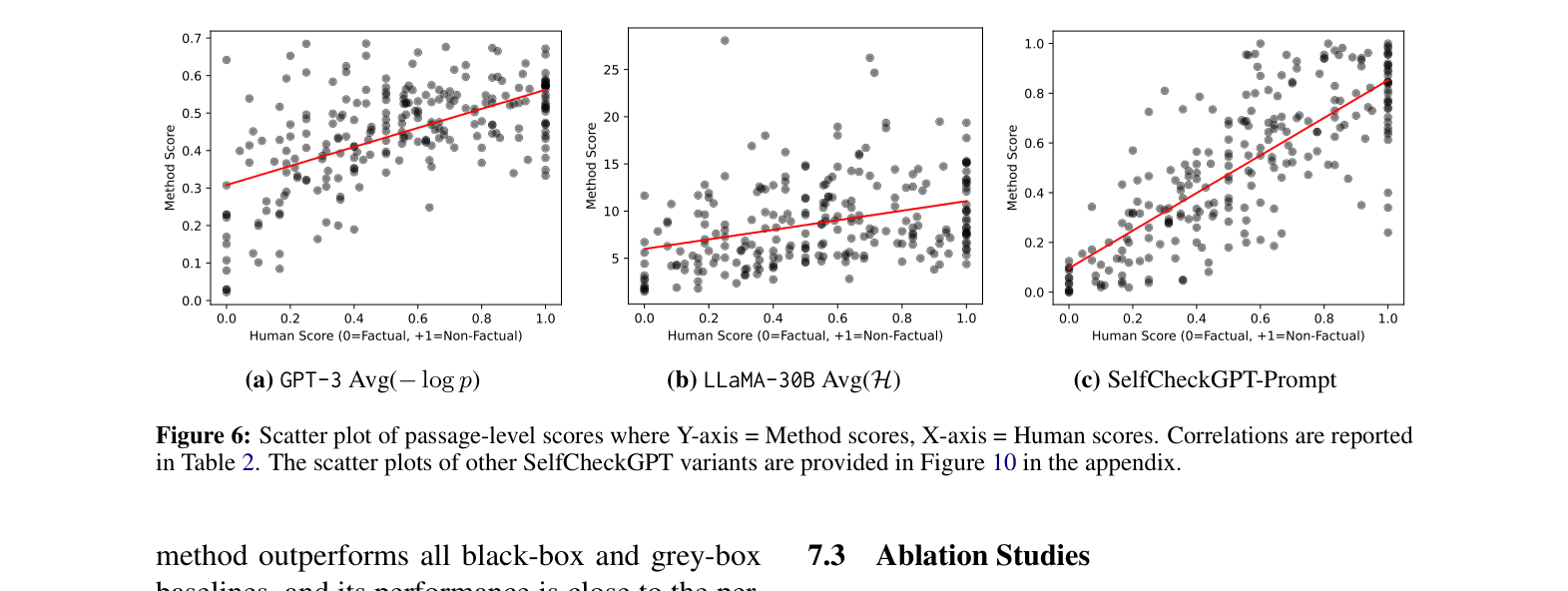
- SelfCheckGPT-NLI achieves 74.14 Pearson correlation with human factuality judgements at the passage level, significantly higher than probability-based methods (57.04)
- Prompt-based variant outperforms the proxy-LLM approach (using LLaMA-30B to estimate GPT-3 uncertainty) by over 17 points in AUC-PR
Breakthrough Assessment
8/10
Establishes a strong baseline for black-box hallucination detection. The idea is simple, effective, and addresses a critical need for API-based models, though the best variant is computationally expensive.