📝 Paper Summary
Medical Factuality
Hallucination Detection
Medical hallucinations in AI models are primarily caused by failures in reasoning rather than a lack of knowledge, and general-purpose models often outperform specialized medical models.
Core Problem
Foundation models in healthcare generate plausible but dangerous misinformation (hallucinations) due to autoregressive training that prioritizes likelihood over accuracy.
Why it matters:
- Undetected misinformation like fabricated medications or false imaging interpretations poses direct patient safety risks
- Knowledge asymmetry between AI and users makes detection difficult, as errors often use correct medical jargon
- Medical-specialized models are assumed to be safer but often underperform general models in preventing hallucinations
Concrete Example:
A model might hallucinate patient symptoms while summarizing a clinical note, similar to a physician's confirmation bias where contradictory symptoms are overlooked, leading to an inappropriate diagnosis.
Key Novelty
Reasoning-Driven Failure Hypothesis
- Establishes that medical hallucinations largely stem from causal or temporal reasoning failures (64–72%) rather than missing medical knowledge
- Demonstrates that general-purpose models with strong reasoning capabilities outperform domain-specific medical models on hallucination tasks
- Proposes a new taxonomy for medical hallucinations including factual errors, outdated references, and spurious correlations
Architecture
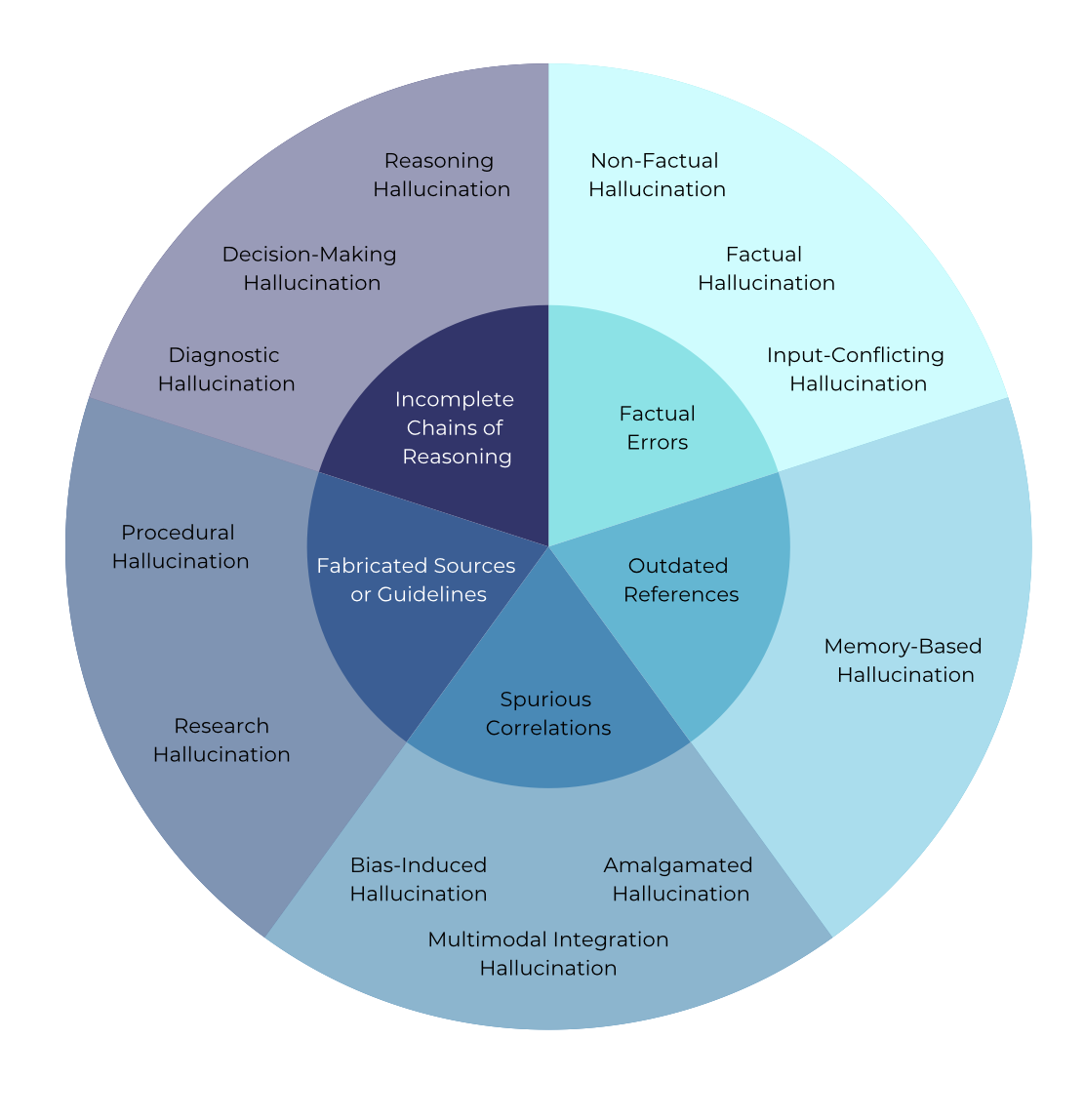
Taxonomy of medical hallucinations clustering errors into five main categories.
Evaluation Highlights
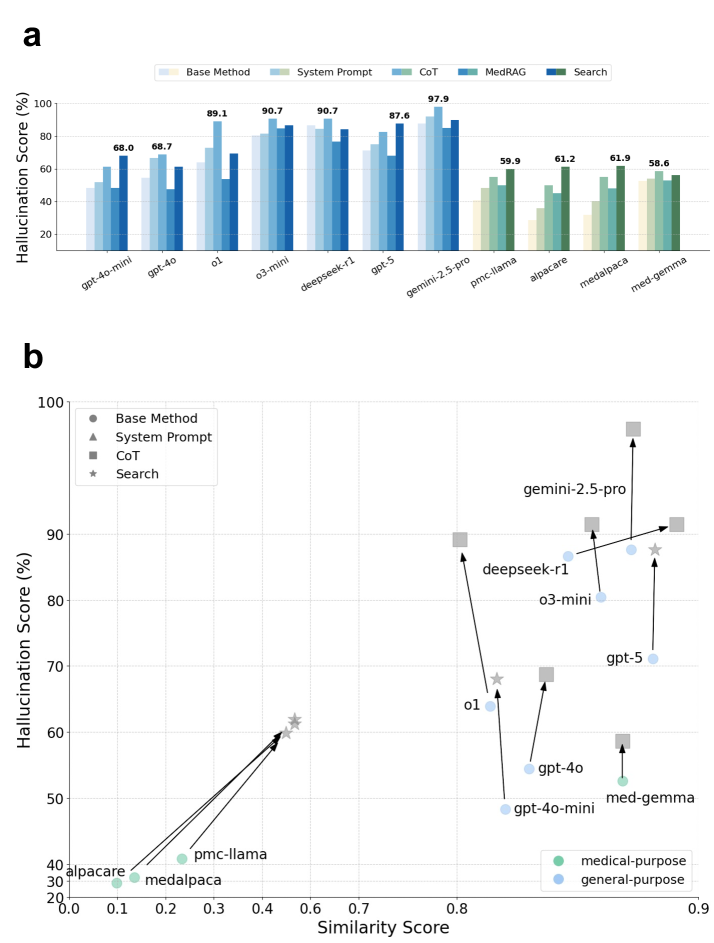
- General-purpose models achieved a median of 76.6% hallucination-free responses compared to 51.3% for medical-specialized models (difference = 25.2%)
- Chain-of-thought prompting improved top models like Gemini-2.5 Pro to >97% accuracy (from 87.6% base), significantly reducing hallucinations in 86.4% of comparisons
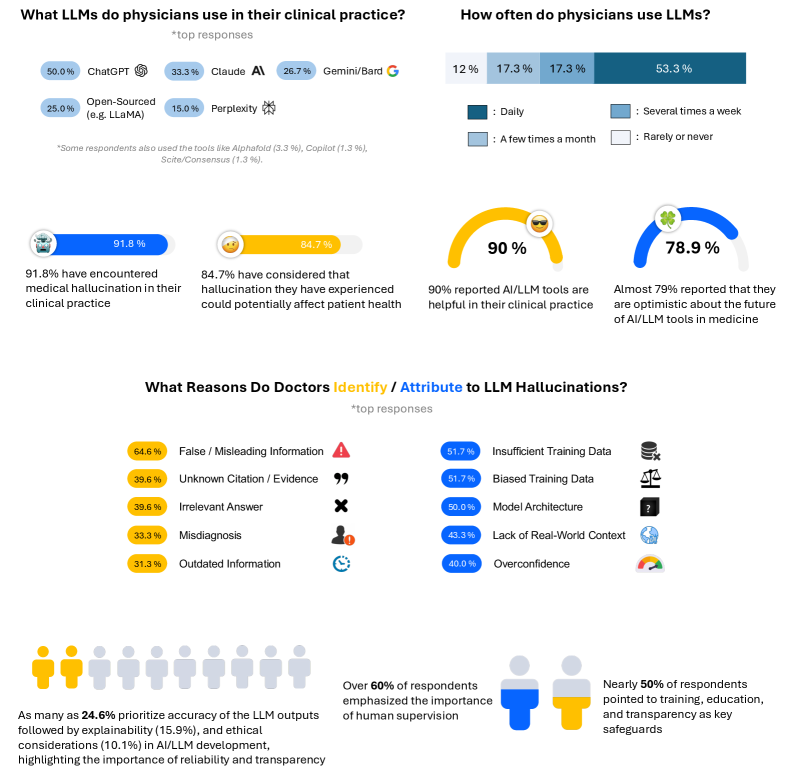
- 91.8% of surveyed clinicians (n=70) reported encountering medical hallucinations, with 84.7% believing they could cause patient harm
Breakthrough Assessment
9/10
Challenge conventional wisdom by showing general models outperform medical-specific ones due to reasoning capabilities. Provides comprehensive taxonomy, benchmark, and clinician survey validation.