📝 Paper Summary
Vision-Language Model Evaluation
Object Hallucination
Large Vision-Language Models suffer significantly from object hallucination, which is exacerbated by instruction tuning and best evaluated using a polling-based binary classification approach (POPE) rather than caption generation.
Core Problem
Large Vision-Language Models (LVLMs) frequently generate descriptions containing objects not present in the image (hallucination), and existing evaluation metrics like CHAIR are unstable and reliant on complex parsing.
Why it matters:
- Hallucination degrades user trust and creates safety risks in real-world applications like autonomous driving (e.g., hallucinating a nonexistent obstacle).
- Current evaluation methods (CHAIR) are sensitive to instruction phrasing and caption length, making fair comparison between models difficult.
- It is counter-intuitive that larger, more capable models might hallucinate more than smaller predecessors, requiring investigation.
Concrete Example:
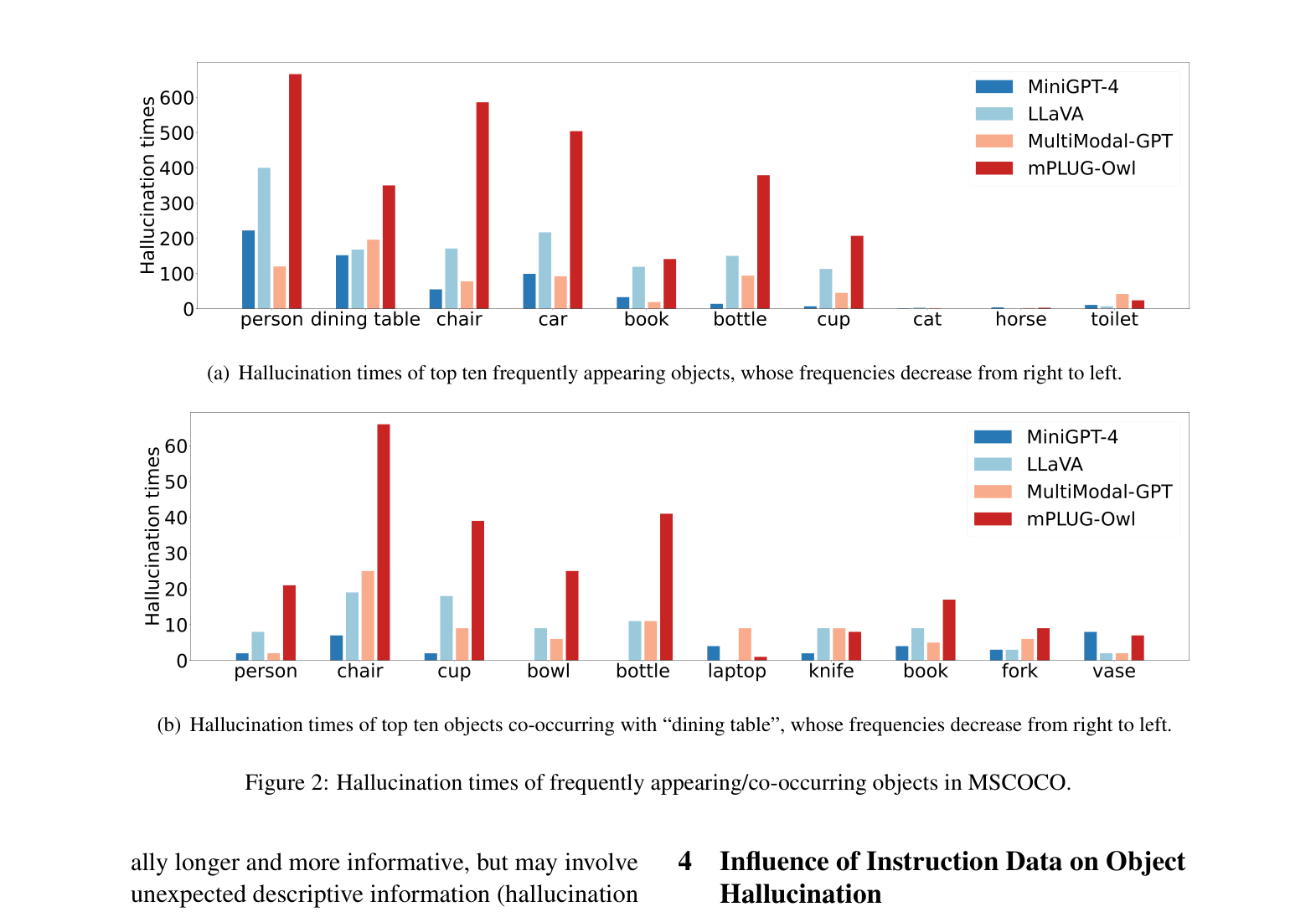
When asked to describe an image of a table with food, an LVLM might hallucinate a 'pear', 'knife', or 'bottle' because these objects frequently co-occur with dining tables in the training data, even if they are visually absent.
Key Novelty
Polling-based Object Probing Evaluation (POPE)
- Shifts evaluation from open-ended caption generation to a binary classification task by asking simple 'Is there a [object] in the image?' questions.
- Uses three negative sampling strategies (Random, Popular, Adversarial) to probe different types of hallucination tendencies.
- Decouples evaluation from caption length and instruction wording, providing a more stable metric.
Architecture
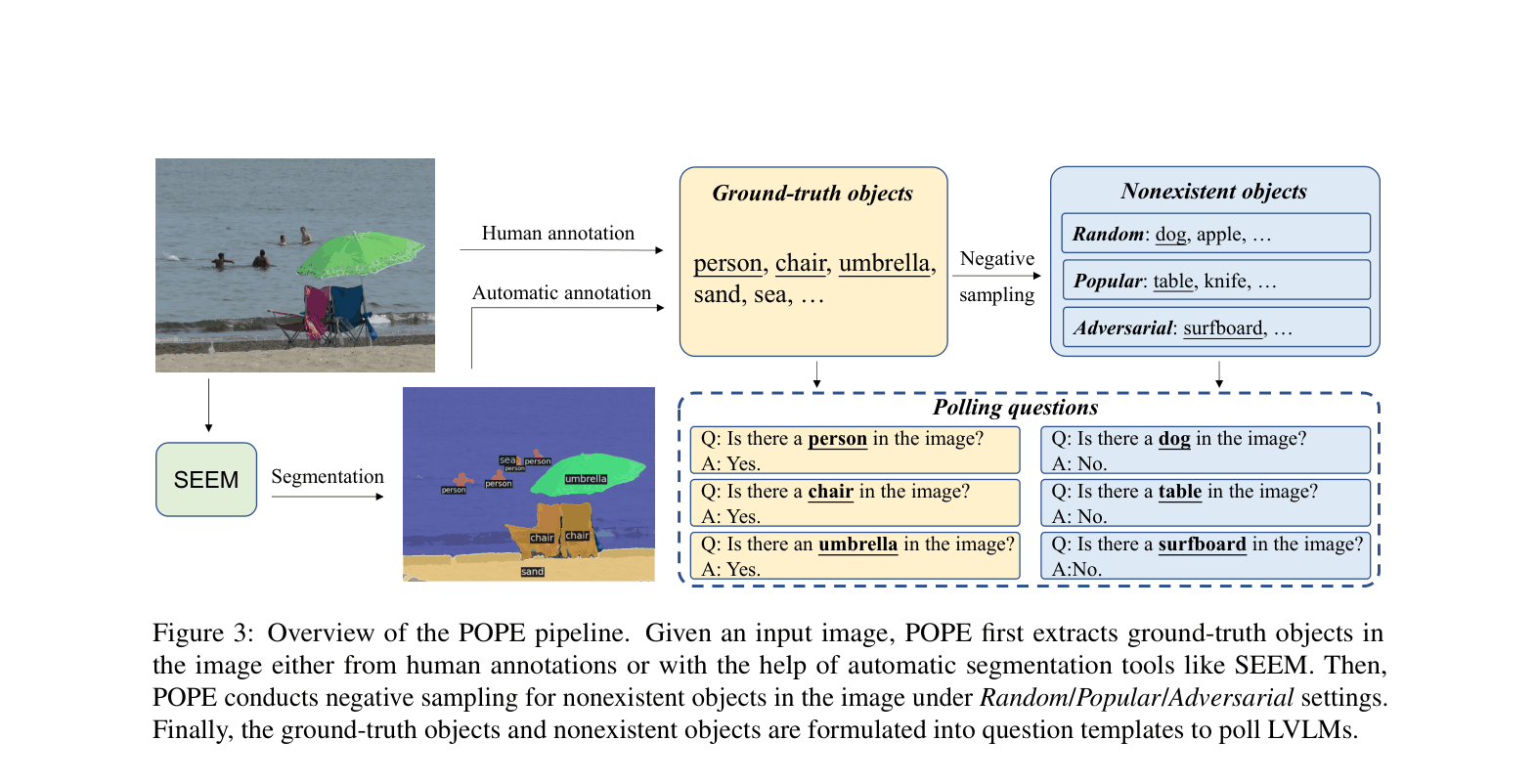
The pipeline of the POPE evaluation method.
Evaluation Highlights
- Current LVLMs show severe hallucination: LLaVA scores 50-54% accuracy on POPE Adversarial/Popular settings (near random guess), showing high overconfidence (99% 'Yes' rate).
- InstructBLIP significantly outperforms other LVLMs (88.73 F1 on Random POPE vs ~50-68 for others), likely due to diverse instruction data.
- Object hallucination is highly correlated with object frequency in instruction data: top-10 frequent objects account for ~50% of hallucinations.
Breakthrough Assessment
8/10
Systematically exposes the severity of hallucination in LVLMs and proposes a standard evaluation protocol (POPE) that has since become a key benchmark in the field.