📝 Paper Summary
Hallucination mitigation
Medical Generative QA
A medical QA system that mitigates hallucinations by iteratively generating, scoring, and refining background knowledge and answers using the LLM's own self-reflective capabilities.
Core Problem
Large Language Models often generate plausible-sounding but unfaithful or nonsensical information (hallucinations) in medical contexts, where accuracy is critical.
Why it matters:
- Inaccurate medical information can have severe consequences for patient care and safety
- Uncommon professional medical concepts make it difficult for general LLMs to maintain faithfulness without external aid
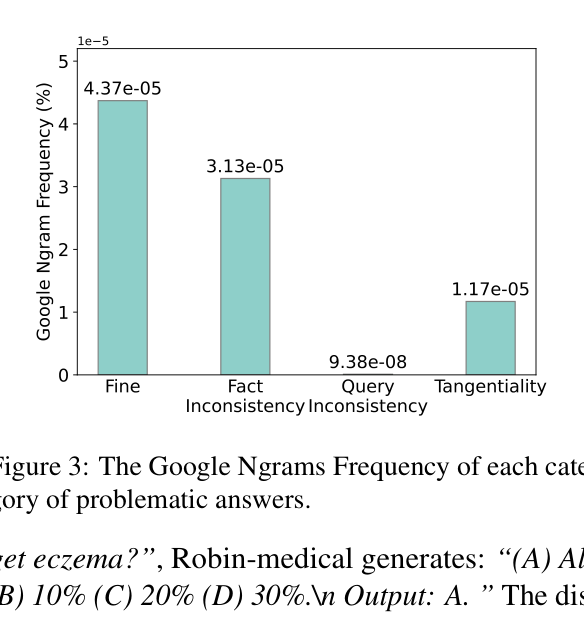
- Current n-gram metrics often fail to discriminate hallucinated answers from correct ones
Concrete Example:
When asked 'What causes Noonan syndrome?', an LLM might confidently claim it is caused by a PTEN gene mutation (hallucination). The proposed method catches this fact inconsistency, prompts the model to self-correct, and eventually produces the correct answer involving PTPN11/SOS1 mutations.
Key Novelty
Interactive Self-Reflection Loop
- Iterative process where the model generates background knowledge, scores its own factuality, and refines it until a threshold is met
- Applied to both knowledge generation and final answer generation to ensure consistency and entailment
- Uses the LLM itself as a scorer via in-context instruction learning rather than requiring external reward models or retrievers
Architecture
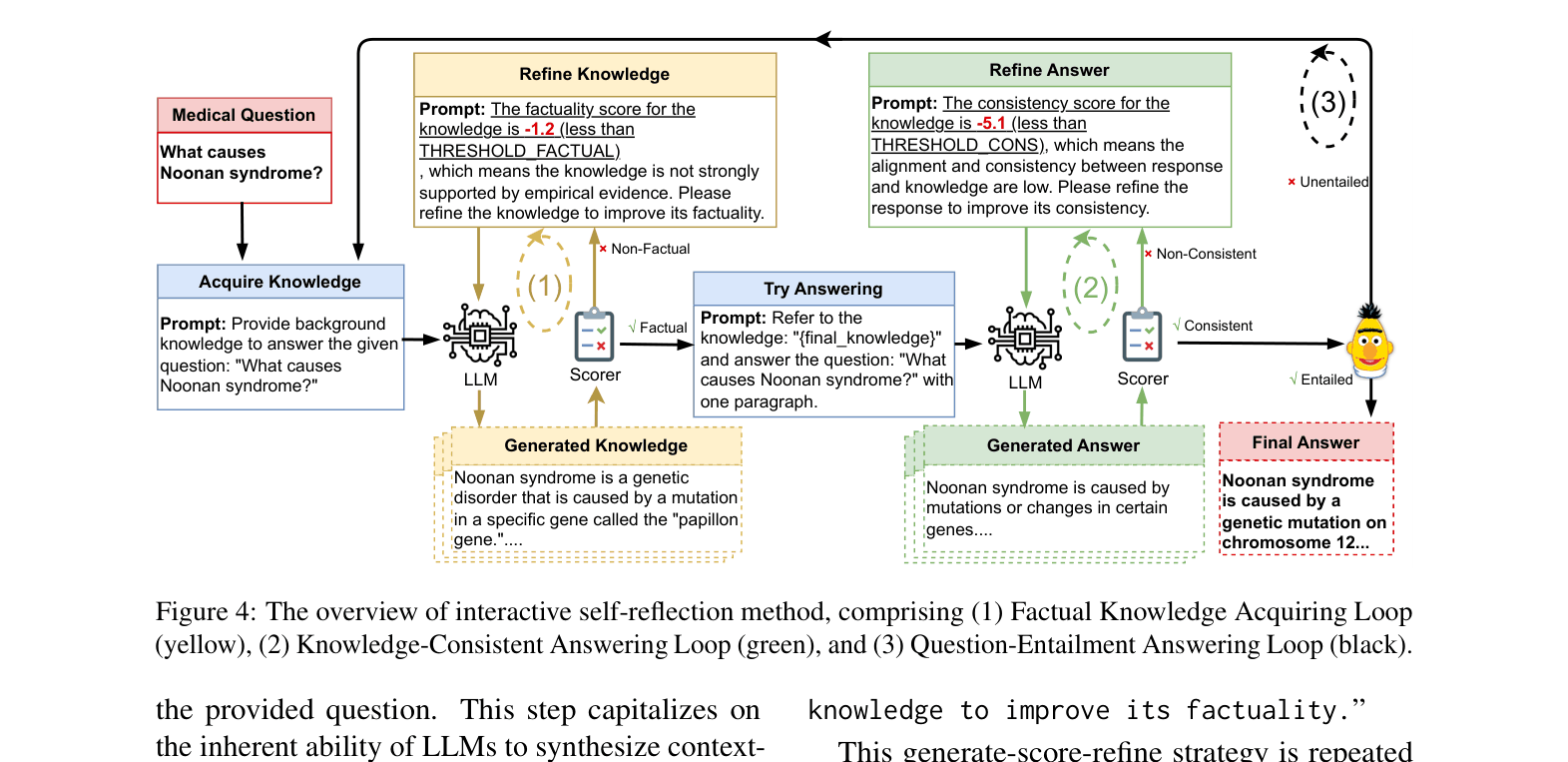
The interactive self-reflection workflow comprising three loops: Knowledge Acquiring, Knowledge-Consistent Answering, and Question-Entailment Answering.
Evaluation Highlights
- Achieves up to ~3x higher sample-level Med-NLI scores (entailment) compared to direct generation baselines on PubMedQA (e.g., Alpaca-Lora-7B improves from 0.0940 to 0.4640)
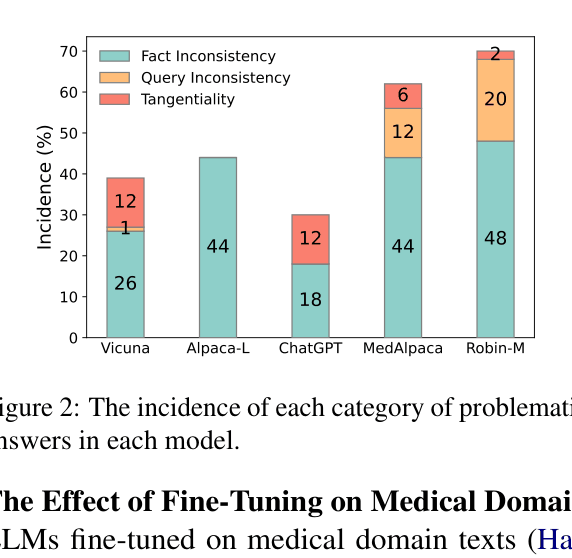
- Reduces Query Inconsistency to 0.00% on PubMedQA for Vicuna-7B (down from 0.67%) and ChatGPT (down from 0.00% to 0.00% while reducing tangentiality)
- Consistent improvements across 5 medical datasets (PubMedQA, MedQuAD, MEDIQA2019, LiveMedQA2017, MASH-QA) and multiple LLMs (Vicuna, Alpaca-LoRA, ChatGPT, MedAlpaca)
Breakthrough Assessment
7/10
Effective, reference-free mitigation strategy that significantly improves faithfulness in medical QA without external retrieval, though it relies heavily on the model's ability to self-evaluate.