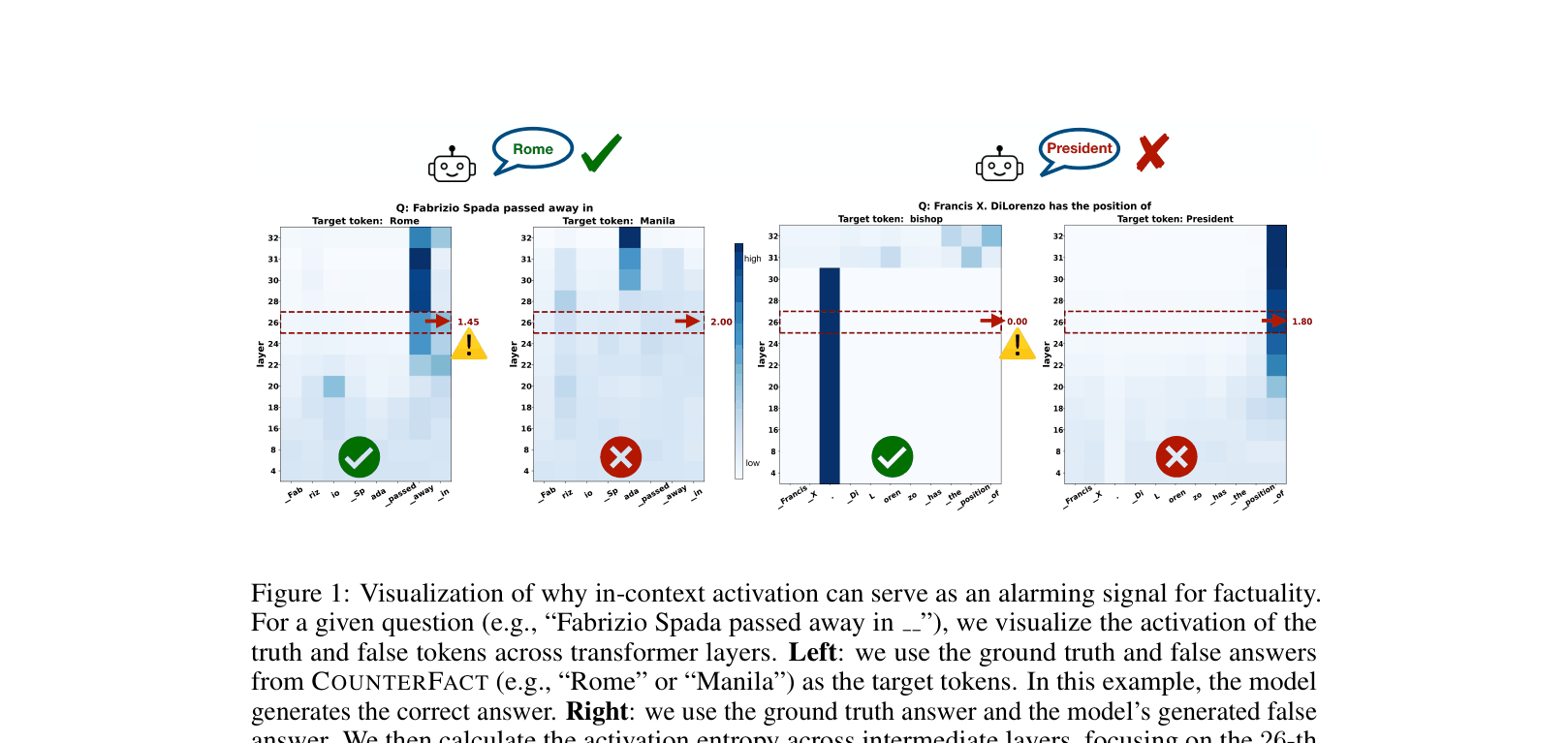
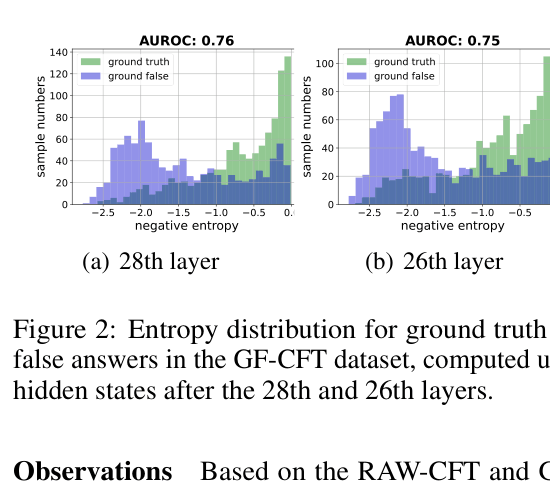
📝 Paper Summary
Hallucination suppression
Mechanistic Interpretability
Constrained Decoding
Activation Decoding mitigates hallucinations by favoring tokens that exhibit sharper activation patterns (lower entropy) relative to the prompt's context tokens in intermediate model layers.
Core Problem
Large Language Models (LLMs) frequently generate hallucinations and factual errors, and existing mitigation methods often require expensive external retrieval, fine-tuning, or high-quality knowledge bases.
Why it matters:
- Hallucinations undermine the trustworthiness and reliability of LLMs in critical applications.
- Resource-intensive methods (retrieval/fine-tuning) are often unavailable for domain-specific cases or constrained environments.
- Understanding the mechanistic cause of hallucinations within hidden states remains an open challenge.
Concrete Example:
When asking 'The twin city of Boston is', an LLM might answer 'Manila' (incorrect) instead of 'Athens' (correct). The paper shows that 'Athens' has sharp, distinct activations against context words like 'Boston' in intermediate layers, while 'Manila' has vague, high-entropy activations.
Key Novelty
In-Context Sharpness as a proxy for Factuality (Activation Decoding)
- Discovers that correct tokens tend to trigger 'sharp' activations (high connection to specific context words) in intermediate layers, while hallucinations have 'flat' or entropic activations.
- Proposes 'Contextual Entropy' to quantify this sharpness: low entropy implies the token is strongly grounded in the prompt's context.
- Modifies the decoding process (Activation Decoding) to penalize tokens with high contextual entropy, pushing the model toward factually grounded outputs without external data.
Architecture
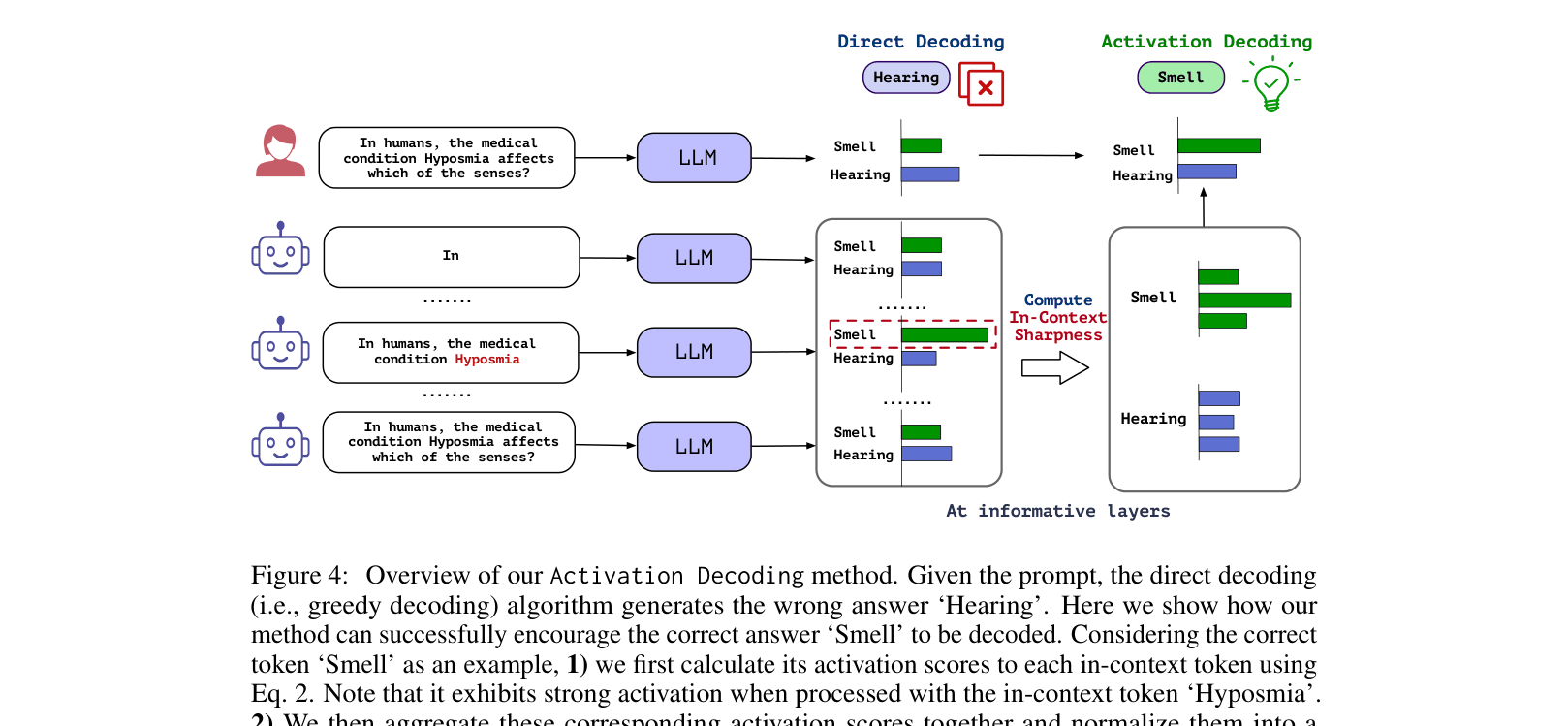
The Activation Decoding process. It illustrates how the model's original wrong prediction ('Hearing') is corrected to 'Smell' by analyzing activation sharpness.
Evaluation Highlights
- Achieves up to +8.6 point improvement on TruthfulQA (Truth*Info metric) with Llama-2-70B-chat compared to greedy decoding.
- Outperforms DoLa and ITI baselines on knowledge-seeking datasets (TriviaQA, HotpotQA, NQ), improving F1 by up to 4.8 points on TriviaQA.
- Increases inference latency by only 23.4% over greedy decoding, while being 7.3% faster than DoLa.
Breakthrough Assessment
7/10
Offers a strong, lightweight mechanistic solution to hallucination without external knowledge. Performance gains are consistent, though it relies on the assumption that the model internally 'knows' the fact.