📝 Paper Summary
Hallucination suppression
Hallucination detection
Halu-J is a 7-billion parameter hallucination judge trained to categorize evidence, filter irrelevant information, and generate detailed critiques to assess factual consistency in multiple-evidence scenarios.
Core Problem
Existing retrieval-based hallucination detectors often lack detailed explanations, treat all retrieved evidence uniformly regardless of relevance, and struggle when retrieval systems return irrelevant or partially relevant data.
Why it matters:
- Lack of detailed explanations erodes trust in high-stakes fields like medicine, where users need evidence-backed reasoning, not just a binary flag
- Flawed retrieval systems frequently return irrelevant data that misleads standard detectors which treat all inputs as equally valid
- Real-world claims often require synthesizing multiple pieces of evidence, but current frameworks fail to differentiate between helpful, irrelevant, and misleading sources
Concrete Example:
In medical settings, simply flagging a generated patient report as containing factual errors without explaining why or citing specific evidence reduces the utility for doctors. A standard detector might see a retrieved document about 'diabetes' and assume it supports a claim about 'Type 2 diabetes' without noticing the document only discusses 'Type 1', leading to a false verification.
Key Novelty
Critique-based Judge with Explicit Evidence Categorization (Halu-J)
- Systematically categorizes retrieved evidence into 'completely irrelevant', 'partially irrelevant', and 'highly related' before verification
- Generates a structured critique that explicitly filters out irrelevant data and analyzes only the pertinent sections of evidence step-by-step
- Trained on a novel dataset (ME-FEVER) designed to simulate complex multi-evidence scenarios with misleading and irrelevant information
Architecture
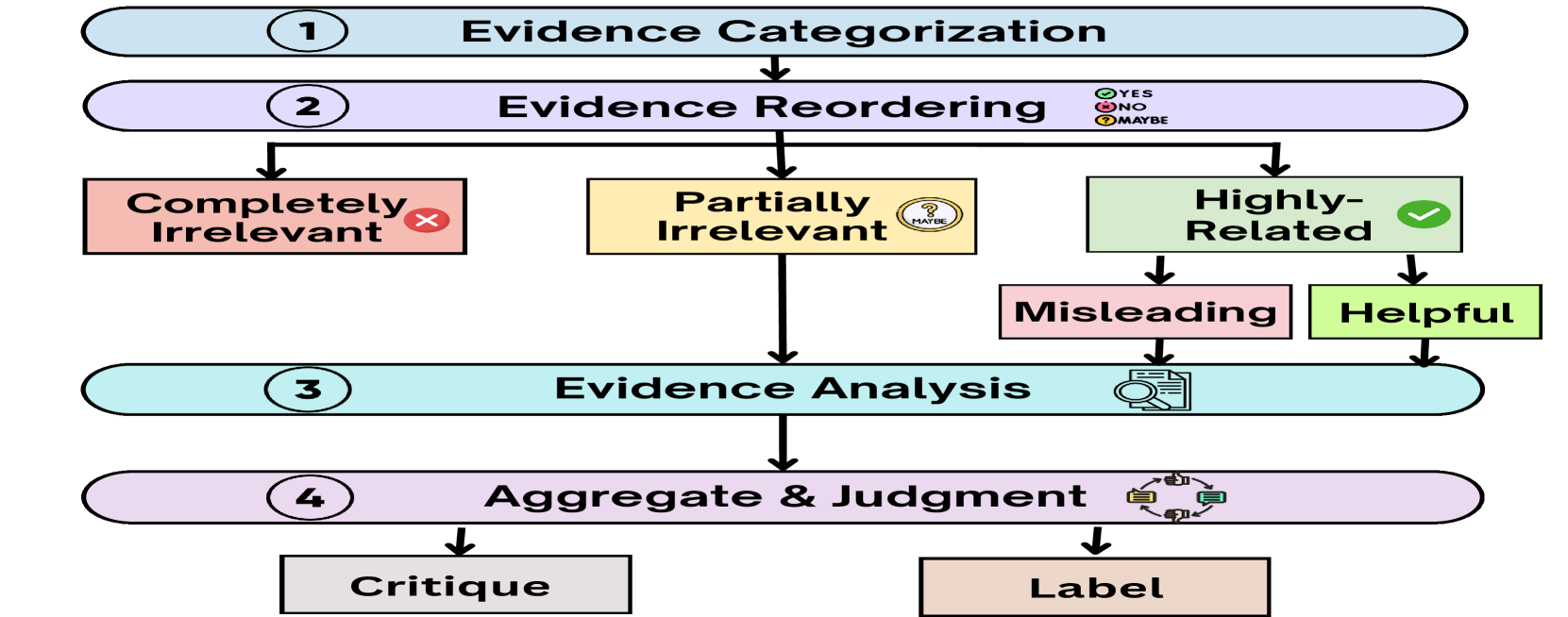
Overview of the Halu-J framework for multiple-evidence hallucination detection.
Evaluation Highlights
- Outperforms GPT-4o on the ME-FEVER test set for multiple-evidence hallucination detection (+2.6% accuracy)
- Achieves higher evidence-matching rate (96.5%) than GPT-4o (93.1%) in generating critiques that cite the correct supporting sentences
- Maintains competitive performance with GPT-4o on standard single-evidence tasks (FEVER dataset) despite being a much smaller 7B model
Breakthrough Assessment
7/10
Strong contribution in formalizing multi-evidence hallucination detection and releasing a specialized dataset/model. Outperforming GPT-4o with a 7B model on this specific task is significant, though the scope is limited to verification.
