📝 Paper Summary
Hallucination suppression
Knowledge internalization
CHECK combines a database-driven fact-checking pipeline with a database-free statistical classifier to detect hallucinations (both confusions and confabulations) and data contamination in medical LLMs.
Core Problem
LLMs in healthcare frequently generate hallucinations (errors from confusion, confabulation, or contamination), which existing methods like simple RAG or entropy analysis fail to fully mitigate.
Why it matters:
- Clinical repercussions are severe; incorrect advice on discontinuing breast cancer therapy can reduce five-year survival by 20–30%
- Existing fine-tuning inherits risks from contaminated/poisoned data, and RAG is labor-intensive and prone to missing facts (coverage gaps)
- Database-free methods (entropy) often miss 'high-confidence' hallucinations (confabulations) where the model is confident but wrong
Concrete Example:
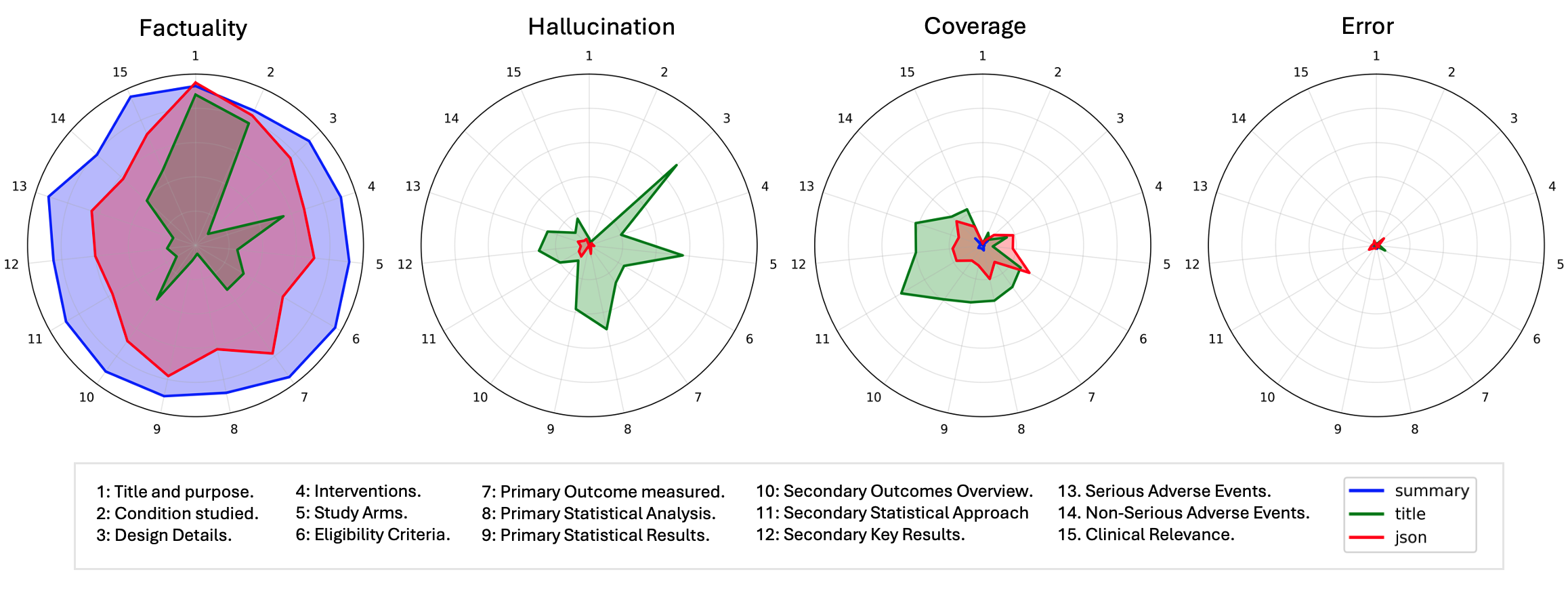
When LLama3.3-70B-Instruct is asked clinical trial questions based only on titles (minimal context), it hallucinates 31% of the time, fabricating study designs or outcomes that sound plausible but are false.
Key Novelty
Dual-Pipeline Arbitration (Database + Statistical Classifier)
- Pipeline 1 (Database-Guided): Uses an LLM judge to cross-reference answers against a curated clinical database, labeling claims as 'Supported', 'Contradicted', or 'Coverage Gap'
- Pipeline 2 (Database-Free): Uses a stacking classifier trained on token probability distributions to detect statistical signatures of hallucination (high entropy/variance) without external knowledge
- Arbitration: Discrepancies between the two pipelines reveal specific error types: database-supported but classifier-flagged suggests reasoning errors; database-refuted but classifier-passed suggests data contamination (poisoning)
Architecture
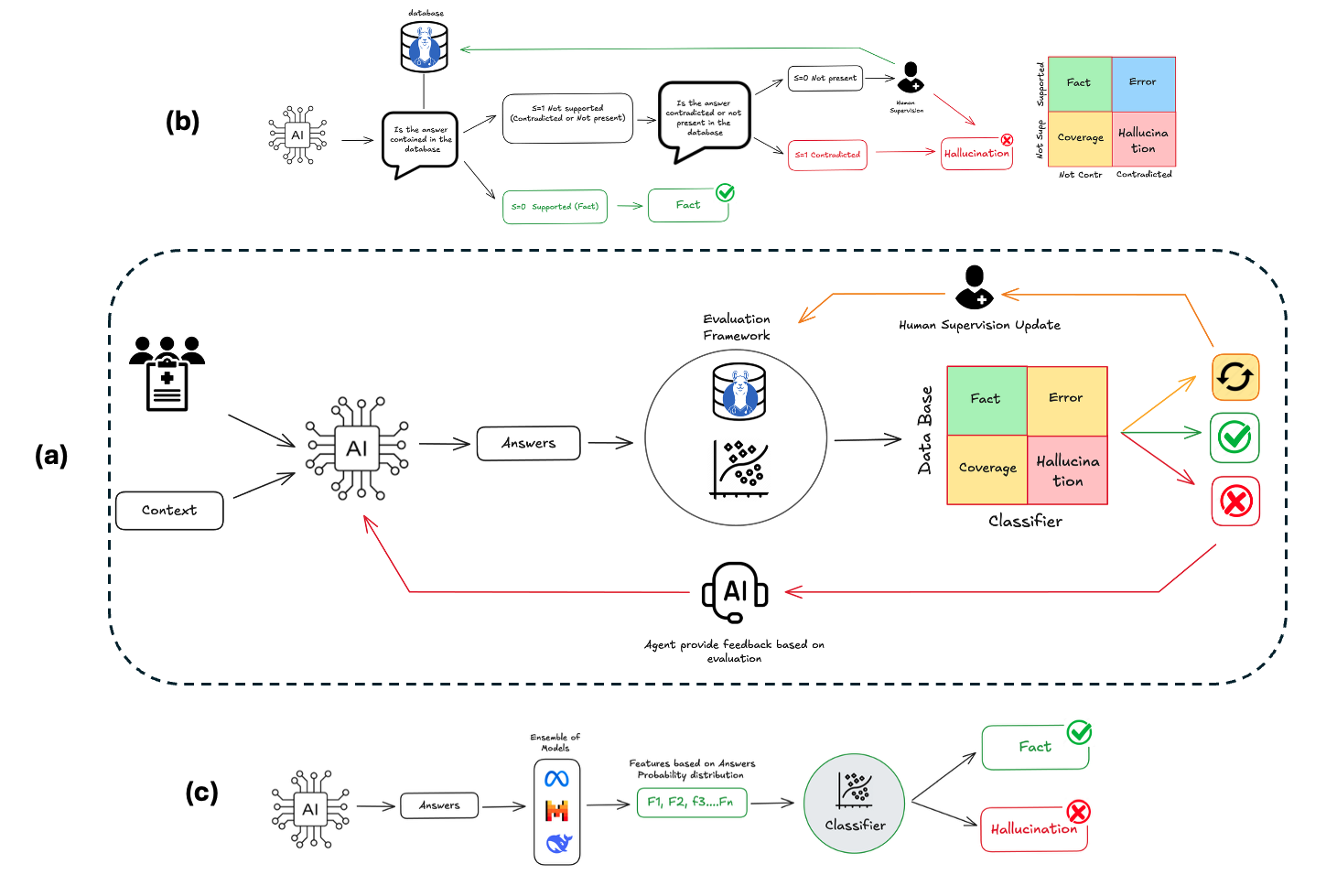
The dual-pipeline architecture of CHECK. (a) Overall workflow, (b) Database-guided pipeline, (c) Database-free classifier pipeline.
Evaluation Highlights
- Reduced LLama3.3-70B-Instruct hallucination rates from 31% to 0.3% on clinical trial questions using full curated summaries
- Achieved AUCs of 0.95–0.96 for hallucination detection across Clinical Trials and UMLS disorders benchmarks
- Boosted GPT-4o's USMLE passing rate by 5 percentage points to a state-of-the-art 92.1% by using hallucination probabilities to guide refinement
Breakthrough Assessment
9/10
Offers a highly robust, dual-verification system that effectively solves 'high-confidence' hallucinations in medicine. The ability to detect data poisoning via pipeline disagreement is a significant conceptual advance.