📊 Experiments & Results
Evaluation Setup
Span-level hallucination detection on three CNLG tasks
Benchmarks:
- RAGTruth (Hallucination Span Detection (Summarization, QA, Data-to-Text))
Metrics:
- Span-F1
- Span-Precision
- Span-Recall
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| RL4HS consistently outperforms baselines across different model sizes and task types. | ||||
| RAGTruth (Avg) | F1 | 50.1 | 55.9 | +5.8 |
| RAGTruth (Avg) | F1 | 27.3 | 58.3 | +31.0 |
| RAGTruth (Avg) | F1 | 51.2 | 58.3 | +7.1 |
| Comparison against general-purpose reasoning models shows domain-specific training is superior. | ||||
| RAGTruth (Avg) | F1 | 15.3 | 55.9 | +40.6 |
| Ablation of the optimization strategy shows CAPO balances precision and recall better than GRPO. | ||||
| RAGTruth (Avg) | F1 | 54.2 | 55.9 | +1.7 |
Experiment Figures
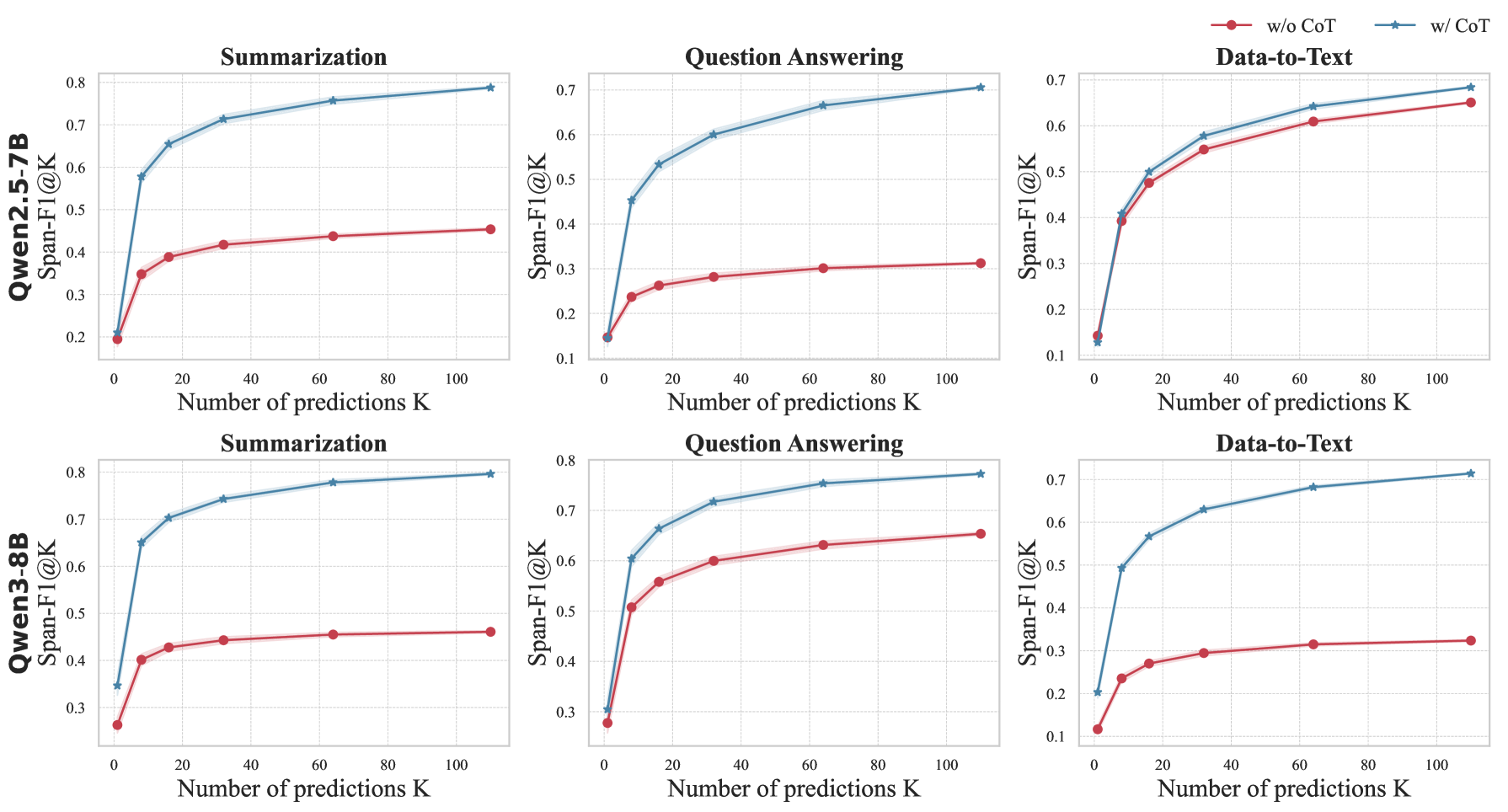
Span-F1@K performance of pretrained models with and without Chain-of-Thought (CoT) as K (number of samples) increases.
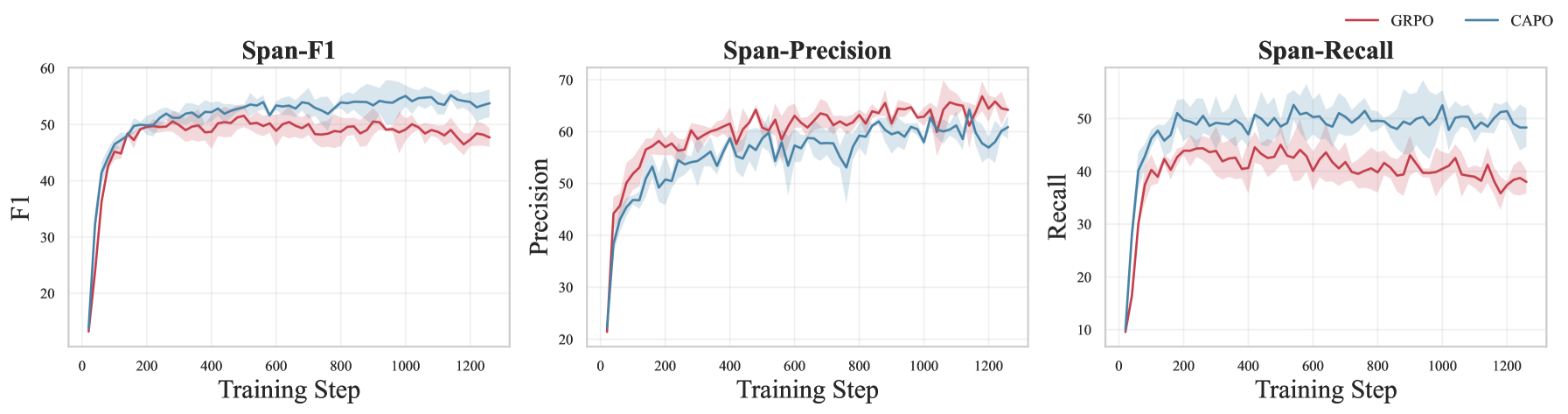
Training dynamics (Recall, Precision, F1) comparing GRPO vs CAPO.
Main Takeaways
- Explicit reasoning (CoT) alone via prompting provides limited gains for hallucination detection; RL training is necessary to fully unlock potential.
- Standard RL (GRPO) with F1 rewards leads to reward hacking where the model defaults to 'no hallucination' to maximize precision at the cost of recall.
- The proposed CAPO method effectively mitigates reward hacking by scaling advantages for the easier non-hallucination class.
- In-domain reasoning training is essential; even much larger general reasoning models (like QwQ-32B) perform poorly compared to smaller, task-specific RL4HS models.