📝 Paper Summary
Multimodal Foundation Models
Diffusion Models for Reasoning
MMaDA is a unified diffusion-based foundation model that handles both text and image generation via a shared masking objective, enhanced by mixed-modal chain-of-thought fine-tuning and a novel diffusion-centric reinforcement learning algorithm (UniGRPO).
Core Problem
Existing unified multimodal models often rely on complex hybrid architectures (mixing autoregressive and diffusion) or lack effective post-training strategies for non-autoregressive diffusion models, limiting their reasoning and generation capabilities.
Why it matters:
- Current approaches struggle to unify complex reasoning (text) and high-fidelity generation (image) without architecture-specific components
- Reinforcement learning (RL) methods designed for autoregressive models do not transfer directly to diffusion models due to differences in probability formulation (masking vs. next-token)
- Lack of unified post-training protocols hinders the development of generalist diffusion models capable of both logic and creativity
Concrete Example:
In text-to-image generation, standard models often fail to adhere to complex prompt logic or factual constraints. MMaDA addresses this by first generating a textual 'thought process' (CoT) to plan the image content before generating the visual tokens, ensuring semantic alignment.
Key Novelty
Unified Diffusion with Reasoning-Enhanced RL (UniGRPO)
- Adopts a completely modality-agnostic diffusion architecture where both text and images are treated as discrete tokens masked and reconstructed under a shared probabilistic formulation
- Introduces 'Mixed Long-CoT Finetuning' to teach the model to generate explicit reasoning steps (textual thoughts) before producing final answers or images, bridging modalities via logic
- Develops UniGRPO, a policy-gradient RL algorithm specifically for diffusion that approximates sequence likelihoods via structured masking, enabling direct optimization of complex rewards (e.g., correctness, CLIP scores)
Architecture
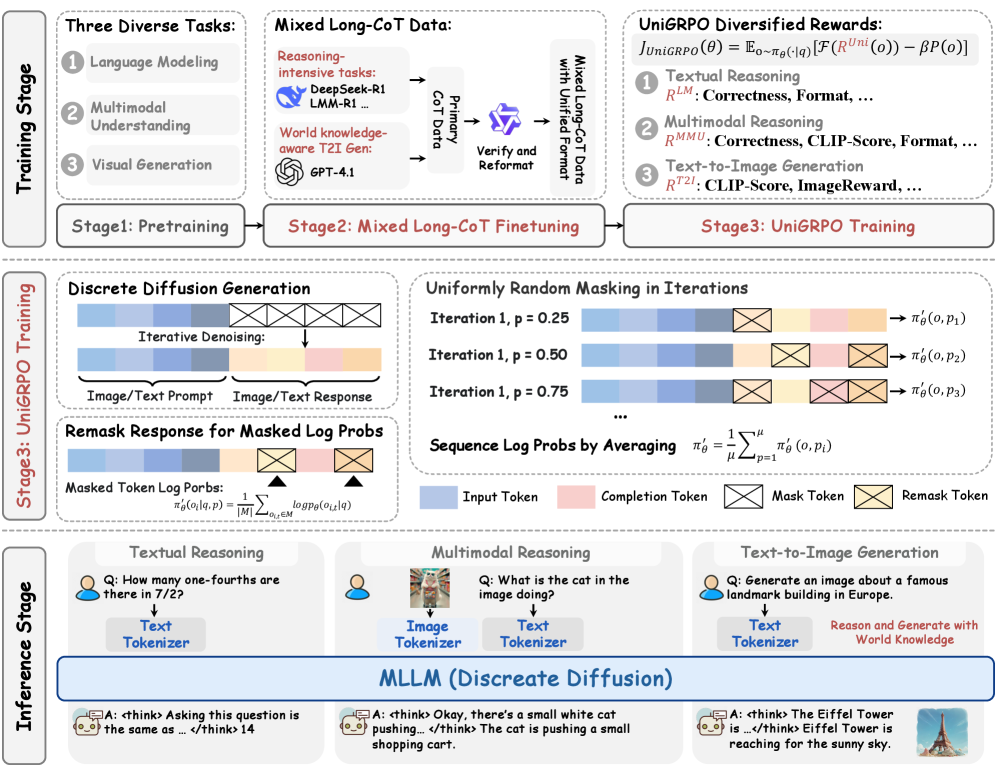
Conceptual flow of MMaDA: Unified Masked Predictor taking mixed inputs (Text + Image tokens), applying random masking, and predicting original tokens. Also shows the UniGRPO loop where diverse mask ratios are sampled to estimate policy gradients.
Evaluation Highlights
- Outperforms LLaMA-3-7B and Qwen2-7B on textual reasoning benchmarks (GSM8K, MATH) despite being a diffusion model
- Surpasses Show-o and SEED-X in multimodal understanding tasks
- Excels over specialized generators like SDXL and Janus in text-to-image generation quality
Breakthrough Assessment
8/10
Significant for unifying reasoning and generation in a pure diffusion framework and successfully adapting RL (GRPO) to non-autoregressive models, a historically difficult challenge.