📝 Paper Summary
Hallucination detection
Hallucination mitigation
Process Reward Models (PRMs)
FG-PRM improves mathematical reasoning by categorizing hallucinations into six distinct types and training specialized reward models on automatically synthesized data to detect these errors at the step level.
Core Problem
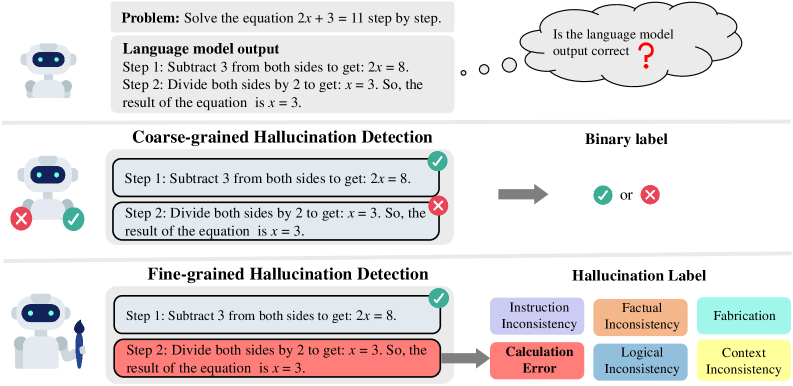
Existing methods for mitigating hallucinations in reasoning chains primarily detect their presence or absence in a coarse-grained manner, lacking nuanced understanding of specific error types (e.g., calculation vs. logic errors).
Why it matters:
- Complex multi-step reasoning requires pinpointing exactly where and why a model fails, not just rejecting the final answer.
- Manual annotation for fine-grained step-level rewards is prohibitively expensive and labor-intensive.
- Coarse-grained feedback (Outcome Reward Models) often fails to identify intermediate errors that lead to wrong solutions.
Concrete Example:
In a multi-step math problem, a model might perform correct logic but fail a simple calculation in Step 3. A standard Process Reward Model might just label Step 3 as 'wrong', but FG-PRM identifies it specifically as a 'Calculation Error', enabling more targeted mitigation and clearer interpretability compared to generic binary labels.
Key Novelty
Fine-Grained Process Reward Model (FG-PRM) via Automated Taxonomy Injection
- Defines a comprehensive taxonomy of six specific hallucination types (e.g., Context Inconsistency, Fabrication) tailored for mathematical reasoning.
- Generates training data automatically by prompting a strong LLM to inject specific hallucination types into correct reasoning steps based on strict preconditions.
- Trains separate reward heads/models for each hallucination type to provide detailed, multi-dimensional feedback on reasoning steps.
Architecture
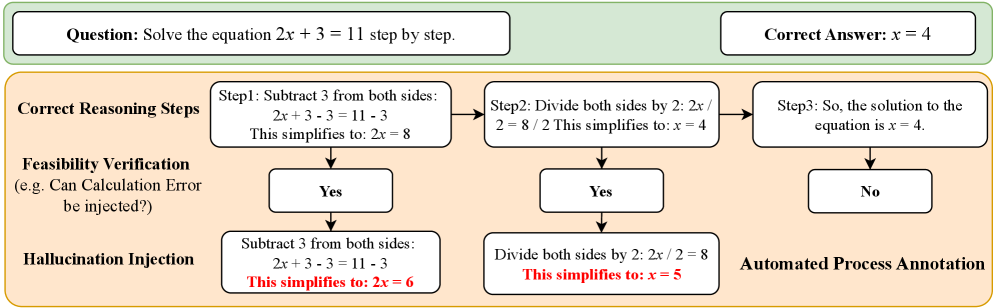
The Automated Hallucination Annotation Framework. It depicts the pipeline from Golden CoT -> Vulnerability Analysis -> Hallucination Injection -> Synthetic Dataset.
Evaluation Highlights
- +5% higher F1 scores on average compared to ChatGPT-3.5 and Claude-3 in fine-grained hallucination detection tasks.
- +3% improvement over standard Process Reward Models (PRMs) in verification tasks on GSM8K and MATH benchmarks.
- Outperforms numerous verifiers trained on human-labeled or coarse-grained data using purely synthetic fine-grained supervision.
Breakthrough Assessment
7/10
Strong contribution in automated data synthesis for fine-grained supervision, addressing the data bottleneck for PRMs. Significant performance gains on standard math benchmarks, though the approach is specific to reasoning tasks.