📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Object Hallucination
GHOST automatically generates high-quality images that induce object hallucinations in Multimodal LLMs by optimizing CLIP embeddings to mislead the target model while visually preserving object absence.
Core Problem
Existing evaluations of object hallucination in MLLMs rely on static benchmarks and fixed scenarios, failing to uncover model-specific blind spots or unanticipated vulnerabilities.
Why it matters:
- Hallucinations in safety-sensitive applications (e.g., autonomous agents) pose significant reliability risks.
- Static benchmarks constrain analysis to known scenarios, missing deeper structural failure modes.
- Prior generative methods are either too slow/resource-intensive or lack direct feedback from the target model to find specific weaknesses.
Concrete Example:
In an image of a banana on a plate, MLLMs correctly state no knife is present. GHOST modifies the banana's stem to subtly resemble a knife edge; the MLLM then hallucinates a knife, even though humans confirm no knife exists.
Key Novelty
Generating Hallucinations via Optimizing Stealth Tokens (GHOST)
- Decouples optimization from generation by training a mapper between CLIP embeddings and the MLLM's vision encoder, allowing efficient feedback without full backpropagation through the diffusion model.
- Optimizes a CLIP embedding to maximize the MLLM's probability of answering 'Yes' to 'Do you see [object]?' while simultaneously penalizing semantic similarity to the object to prevent actual insertion.
- Uses the optimized embedding to guide a diffusion model (starting from a noisy version of the original image) to generate natural-looking adversarial examples.
Architecture
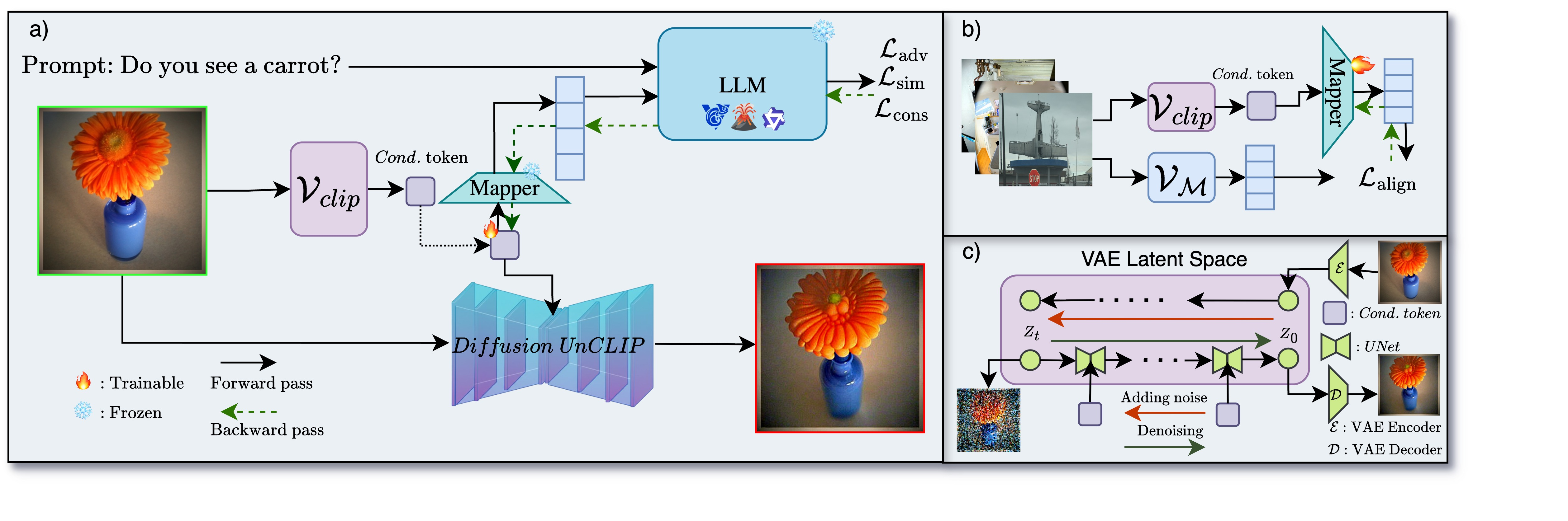
The GHOST pipeline showing the three main stages: Optimization, Mapper Training, and Guided Diffusion.
Evaluation Highlights
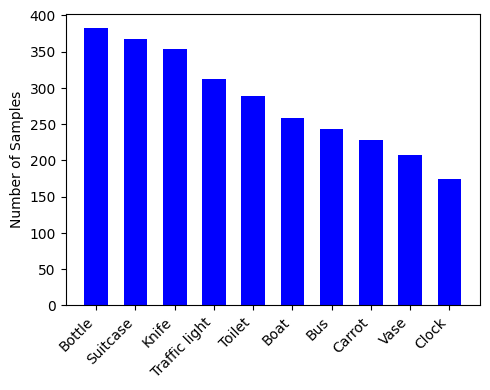
- Achieves a 28-29% hallucination success rate on Qwen2.5-VL and LLaVA-v1.6, discovering thousands of failure cases compared to <1% for prior data-driven methods.
- Demonstrates high transferability: images optimized for Qwen2.5-VL induce hallucinations in GPT-4o at a 66.5% rate.
- Maintains high image quality and semantic fidelity, outperforming standard diffusion baselines in FID scores relative to the original image (e.g., 29.58 vs 36.63 for Qwen).
Breakthrough Assessment
8/10
Significantly improves the efficiency and success rate of automated red-teaming for MLLMs. The decoupling of optimization and generation is a smart architectural choice that enables scalability.