📝 Paper Summary
Hallucination Detection
Factuality
AGSER detects hallucinations by comparing the consistency of answers generated from 'attentive' query tokens (high attention contribution) versus 'non-attentive' tokens (low attention contribution) without requiring annotated training data.
Core Problem
Existing hallucination detection methods often rely on expensive multiple answer resampling or annotated datasets for training classifiers, making them computationally heavy or hard to generalize.
Why it matters:
- Hallucinations make LLMs untrustworthy for critical applications like medical, financial, or legal advice
- Current consistency-based methods (like SelfCheckGPT) increase computational cost heavily by running the LLM many times (e.g., 5-20 samples)
- Supervised methods require specific labeled data which may not transfer across different LLMs or domains
Concrete Example:
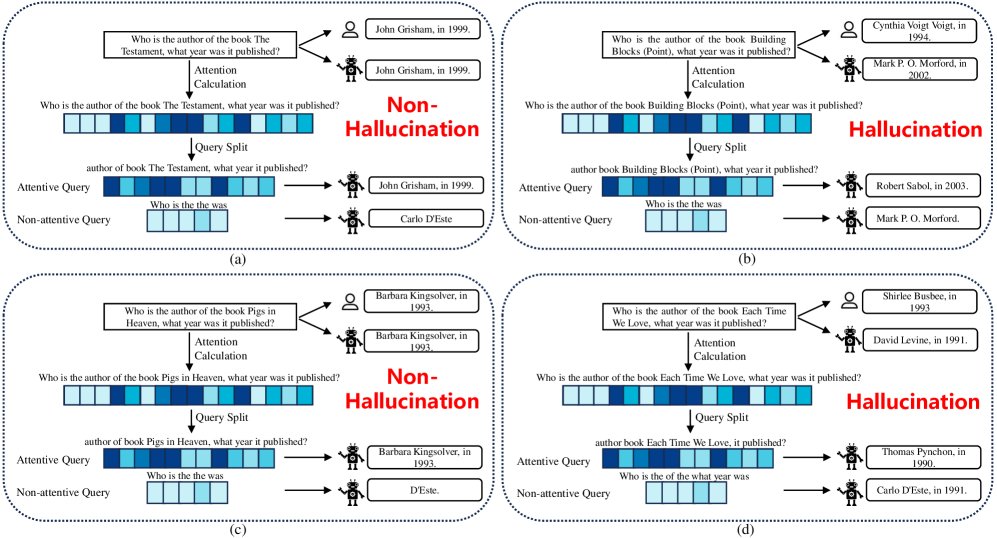
When an LLM answers a question about a book, it might confidently hallucinate the author. Standard methods would re-ask the full question 5 times to check consistency. AGSER instead extracts the key words the model attended to (attentive query) and the ignored words (non-attentive query) and checks if the model stays consistent on the important parts vs. the unimportant parts.
Key Novelty
Attention-Guided SElf-Reflection (AGSER)
- Splits the input query into two sub-queries based on internal attention weights: an 'attentive query' (tokens the model focused on) and a 'non-attentive query' (tokens the model ignored)
- Leverages the intuition that for factual answers, the 'attentive' part should yield the same answer as the original, while the 'non-attentive' part should produce random/different answers
- Uses the difference between the consistency of the attentive response and the non-attentive response as a scalar score to estimate hallucination
Architecture
Conceptual flow of AGSER: Input Query X -> Calculate Attention -> Split into X_att and X_non_att -> Generate Y_att and Y_non_att -> Compute Consistency scores -> Calculate final Hallucination Score
Evaluation Highlights
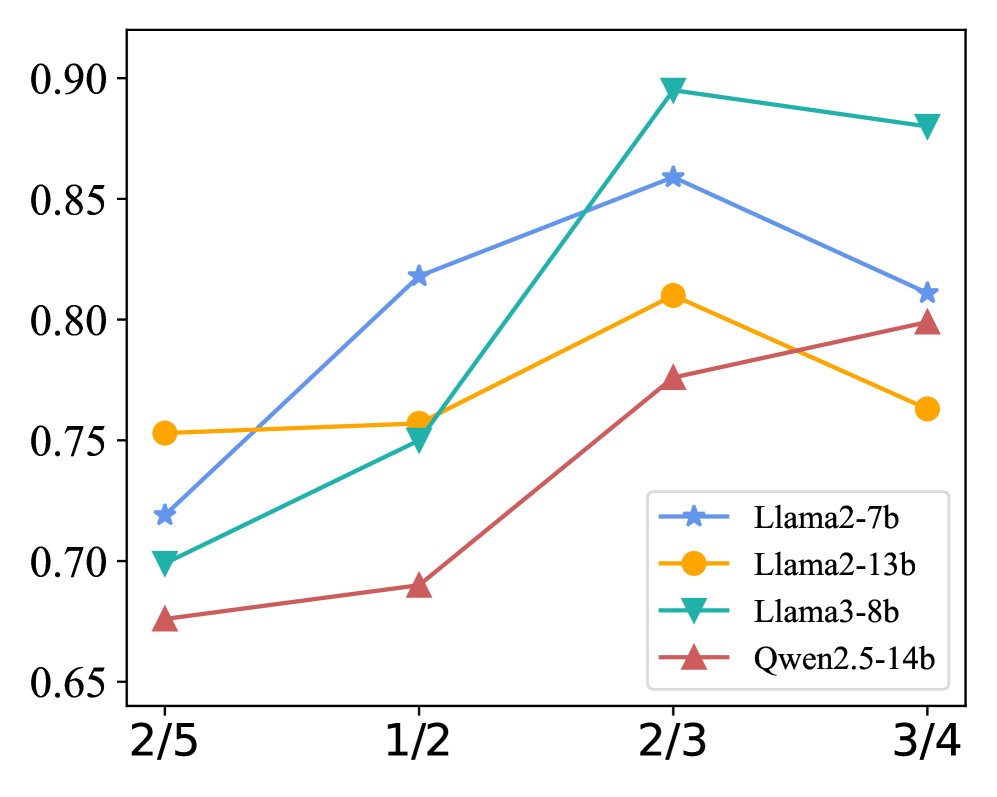
- Outperforms SelfCheckGPT by +16.1% AUC on average using Llama2-7b across three datasets
- Surpasses InterrogateLLM (previous SOTA) by +6.7% AUC on average using Qwen2.5-14b
- Reduces computational overhead significantly: requires only 3 LLM passes compared to 5 resampling passes used by baselines
Breakthrough Assessment
7/10
Strong improvements in zero-shot detection accuracy while reducing compute cost. The idea of using attention to split queries for self-consistency is a clever, intuitive heuristic that effectively probes internal model uncertainty.