📝 Paper Summary
Hallucination Evaluation
Dialogue Systems
HalluDial is a large-scale benchmark for evaluating dialogue-level hallucinations, covering both spontaneous and induced scenarios, accompanied by a specialized judge model (HalluJudge) for automatic assessment.
Core Problem
Existing hallucination benchmarks primarily focus on sentence or passage levels, neglecting dialogue-level nuances, hallucination localization, and rationale provision.
Why it matters:
- LLMs are widely deployed in dialogue applications, yet their propensity for hallucination in multi-turn conversations remains under-explored
- Current benchmarks overlook faithfulness hallucinations (contradicting source) in favor of factuality (contradicting world knowledge)
- Reliance on non-specialized evaluators or expensive human annotation limits the scalability and interpretability of hallucination assessments
Concrete Example:
In an information-seeking dialogue about music, an LLM might spontaneously invent details not present in the provided knowledge snippet (spontaneous) or be tricked by a malicious user into agreeing with false information (induced). Existing sentence-level metrics miss the conversational context that triggers these errors.
Key Novelty
Dual-Scenario Dialogue Hallucination Benchmark
- Constructs data through two distinct scenarios: 'Spontaneous' (LLMs naturally hallucinating during generation) and 'Induced' (LLMs tricked into hallucinating via malicious instructions), covering both factuality and faithfulness
- Provides comprehensive annotations including detection, localization (specific spans), and rationales (explanations) for 146,856 samples
- Introduces HalluJudge, a specialized evaluator model fine-tuned on this data to replace human or generic LLM evaluators
Architecture
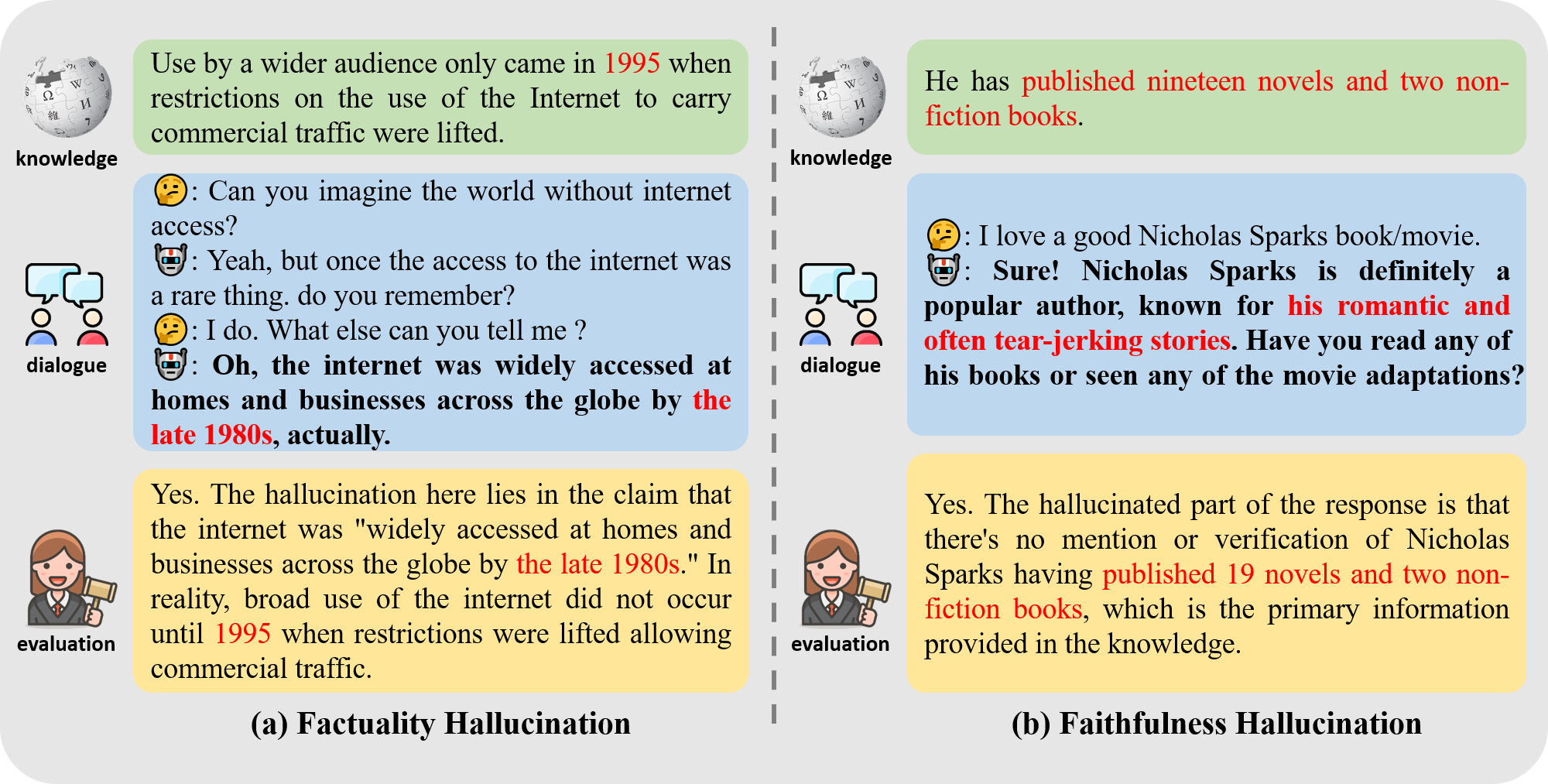
Overview of the HalluDial construction pipeline and the HalluJudge framework.
Evaluation Highlights
- HalluJudge achieves 71.34% accuracy on the HalluDial test set, outperforming GPT-4 (68.45%) and Llama-2-70B-chat (68.48%)
- On hallucination localization, HalluJudge achieves a ROUGE-L of 70.36, significantly surpassing GPT-4 (60.67) and GPT-3.5-turbo (56.09)
- Human evaluation confirms HalluJudge's explanations are high quality, matching human agreement levels with a Cohen's Kappa of 0.902
Breakthrough Assessment
8/10
Addresses a significant gap (dialogue-level hallucination) with a very large dataset and a strong specialized judge model. The distinction between spontaneous and induced hallucinations adds valuable depth.