📝 Paper Summary
Hallucination suppression
Representation editing
Iter-AHMCL reduces hallucinations by fine-tuning LLMs with contrastive learning guided by dedicated positive (truthful) and negative (hallucinating) proxy models that are iteratively updated.
Core Problem
LLMs suffer from hallucinations where they fabricate facts, and standard fine-tuning methods to fix this often cause catastrophic forgetting of general capabilities.
Why it matters:
- Factual inaccuracies in high-stakes fields like scientific research or medicine can degrade application quality and erode user trust
- Existing sample-level guidance methods (using static vectors) are prone to overfitting and depend heavily on hyperparameter tuning
- Alignment techniques often tradeoff between reducing hallucinations and maintaining the model's original language modeling strengths
Concrete Example:
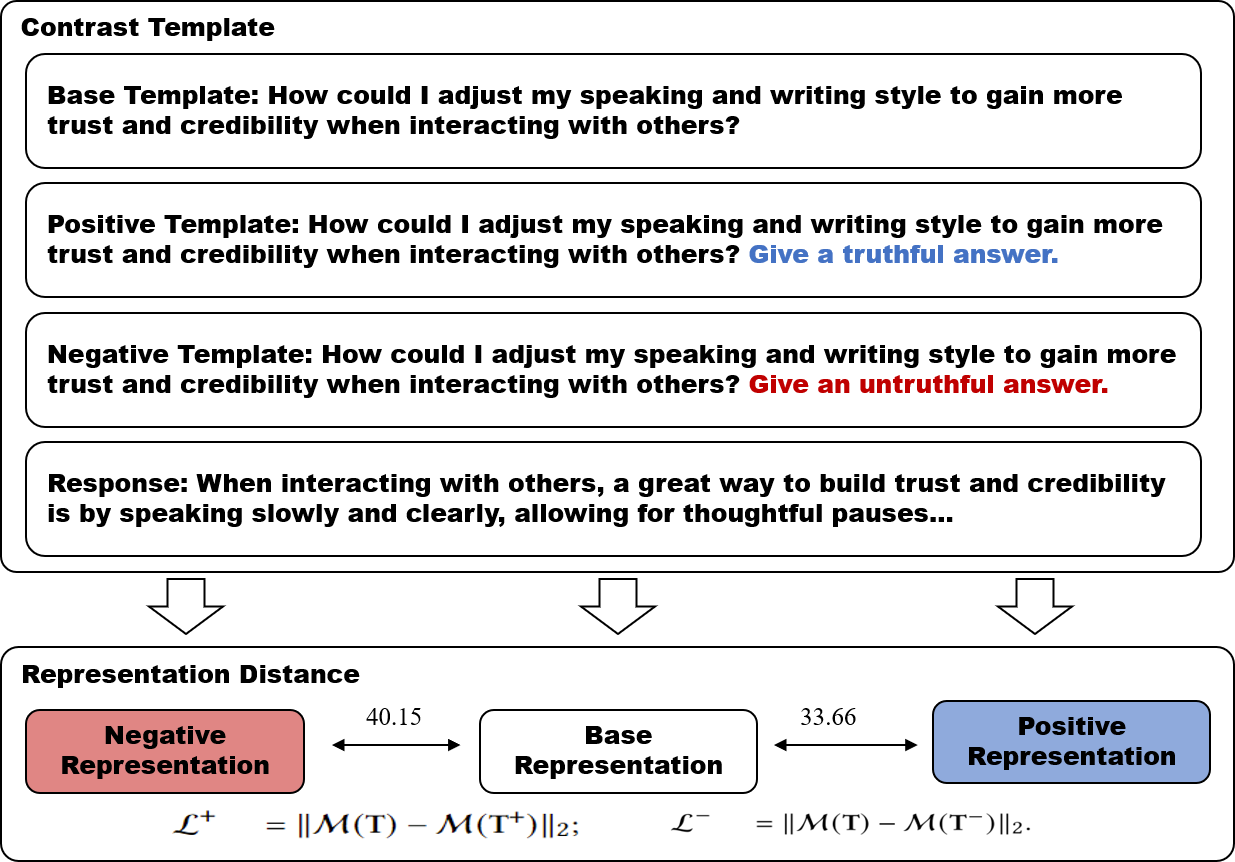
When asked a question that induces hallucination, a standard model might confidently fabricate an answer. Existing editing methods like LoRRA use a fixed vector direction calculated from data samples, which might be imprecise for unseen inputs. Iter-AHMCL instead uses a trained 'negative model' that specifically tries to hallucinate, providing a dynamic negative reference to push the main model away from.
Key Novelty
Iterative Model-level Contrastive Learning (Iter-AHMCL)
- Replaces static vector guidance with dynamic model-level guidance: trains separate 'positive' (truthful) and 'negative' (hallucinatory) LoRA adapters to generate reference representations
- Uses these reference models to define a contrastive loss that pulls the target model's representations toward the positive model and pushes them away from the negative model
- Updates the guidance models iteratively: as the main model improves, the positive guidance model is updated to be even more truthful, creating a moving target for continuous improvement
Architecture
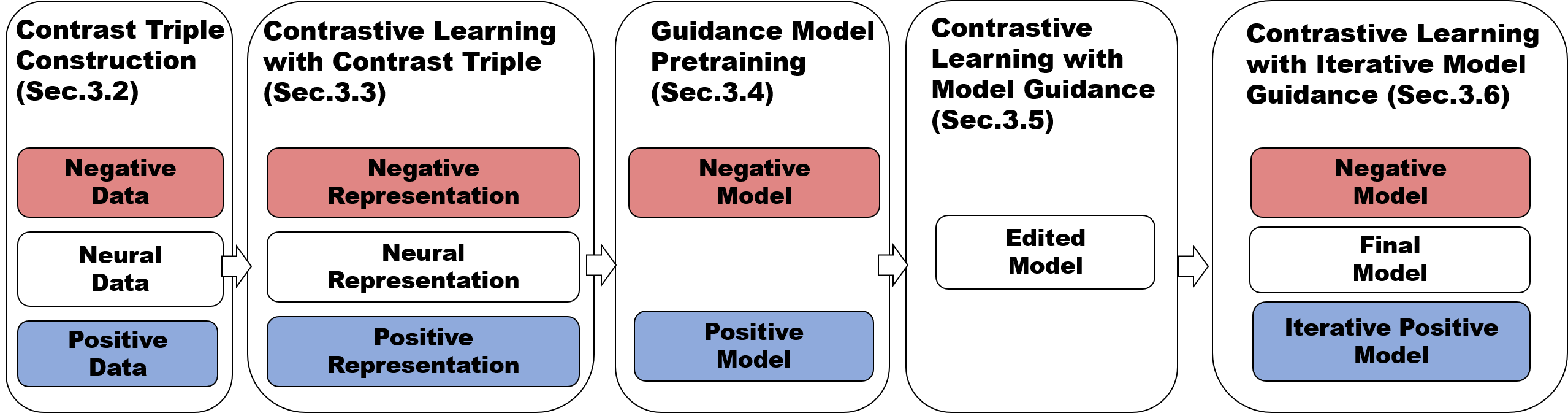
The overall procedure of Iter-AHMCL, illustrating the data construction, guidance model training, and the iterative fine-tuning loop.
Evaluation Highlights
- +10.1 point average improvement on TruthfulQA benchmark across four foundation models (LLaMA2, Alpaca, LLaMA3, Qwen)
- Effectively reduces hallucination while maintaining general capabilities, verified through comprehensive experiments on multiple LLMs
- Demonstrates that model-level guidance outperforms sample-level vector guidance (standard LoRRA) in separating truthful and untruthful directions
Breakthrough Assessment
7/10
Offers a strong methodological improvement over static representation editing (LoRRA) by using dynamic proxy models. The iterative update strategy is a logical and effective extension for alignment.