📊 Experiments & Results
Evaluation Setup
Biography generation for 500 entities across 19 languages.
Benchmarks:
- Multilingual Biography Dataset (Open-ended text generation) [New]
Metrics:
- ROUGE-1 / ROUGE-L
- Named Entity Overlap (Precision, Recall, F1)
- NLI-based scores: ENT (Entailment), CON (Contradiction), DIFF (Entailment - Contradiction), UNV (Unverifiable)
- Pearson Correlation (between metrics and human judgments)
- Statistical methodology: Pearson Correlation Coefficients reported for metric agreement.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Correlation analysis shows NLI metrics align better with human judgment than lexical metrics, but effectiveness varies by resource level. | ||||
| Multilingual Biography Dataset | Pearson Correlation (Pairwise vs Ref NLI) | Not statistically significant | 0.35 to 0.56 | Significant positive correlation |
| Multilingual Biography Dataset | UNV Score Range | 0.15 - 0.25 | > 0.25 | Higher |
Experiment Figures
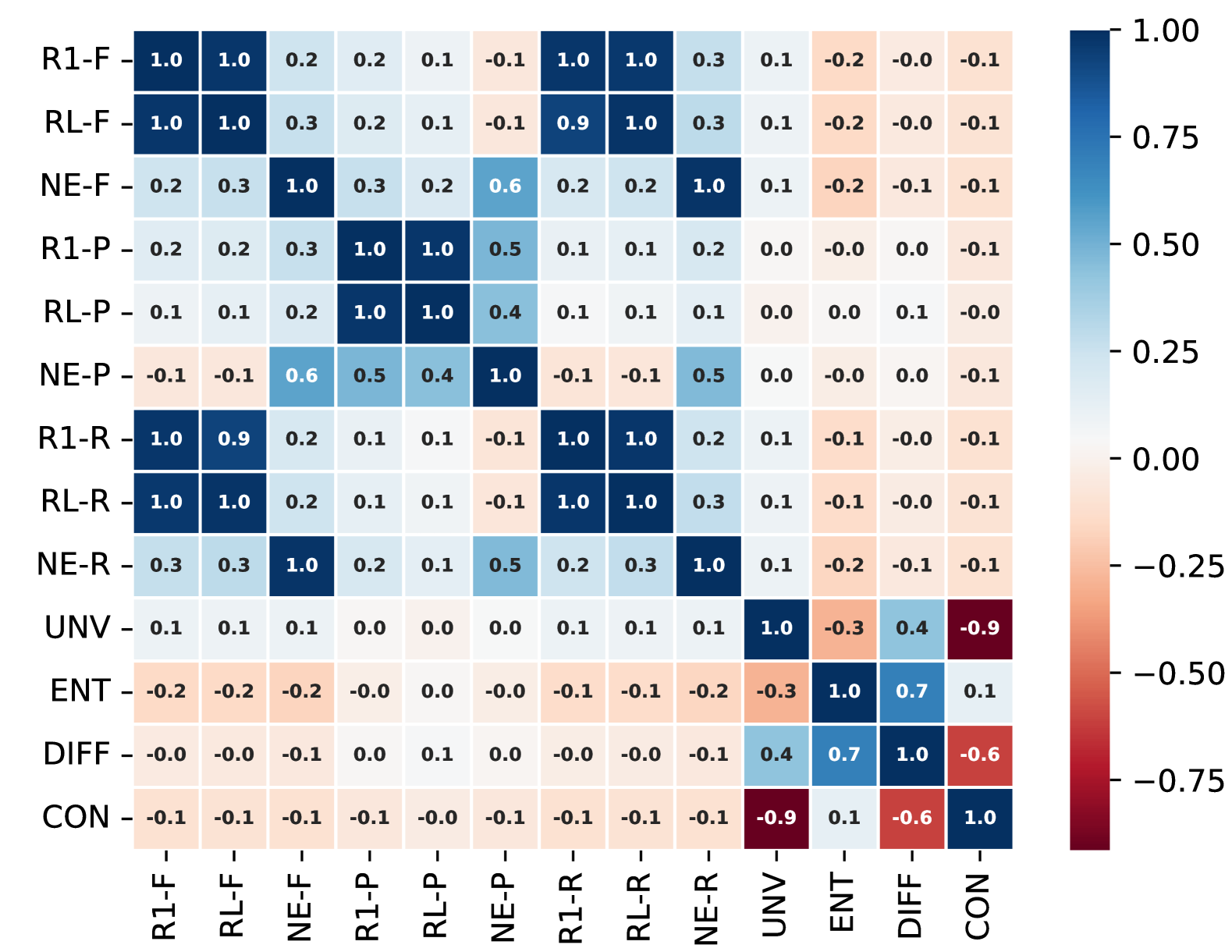
Heatmap of Pearson correlations between different automatic metrics (ROUGE, NEO, NLI) for English.
Main Takeaways
- Lexical metrics (ROUGE, Entity Overlap) do not correlate with NLI metrics or human judgments, making them poor proxies for factuality.
- NLI-based metrics (especially DIFF) remain relatively stable across languages but perform best on high-resource languages.
- Pairwise consistency (checking agreement between model generations) correlates well with reference-based scoring in high-resource languages but fails in low-resource settings.
- Generation quality varies drastically: High-resource languages produce long, accurate text; low-resource languages (e.g., Ukrainian) produce very short (avg 5.7 tokens) or wrong-language text.
- NLI metrics are good at detecting sentence-level hallucinations but struggle with 'atomic' single-fact errors.