📝 Paper Summary
Hallucination survey
Factuality evaluation
This survey provides a comprehensive taxonomy of hallucinations in Large Language Models (LLMs), distinguishing them from traditional NLG errors, and reviews current detection, explanation, and mitigation strategies.
Core Problem
Large Language Models frequently generate content that conflicts with user input, previous context, or established facts, undermining their reliability in real-world applications.
Why it matters:
- LLMs are trained on massive, uncurated web data containing fabricated or biased information, making hallucinations hard to eliminate at the source
- The versatility of LLMs across tasks and domains makes comprehensive evaluation and mitigation significantly harder than in task-specific models
- Hallucinations in critical fields like medicine or law can lead to tangible real-life risks due to the imperceptibility of highly plausible but false errors
Concrete Example:
When asked about the mother of Afonso II, an LLM might confidently answer 'Queen Urraca of Castile' instead of the correct 'Dulce Berenguer of Barcelona', presenting a fact-conflicting hallucination that misleads users.
Key Novelty
LLM-Specific Hallucination Taxonomy
- Redefines hallucination for the LLM era by categorizing it into three distinct types: input-conflicting, context-conflicting, and fact-conflicting
- Differentiates hallucination from other common LLM issues like ambiguity, incompleteness, bias, and under-informativeness
Architecture
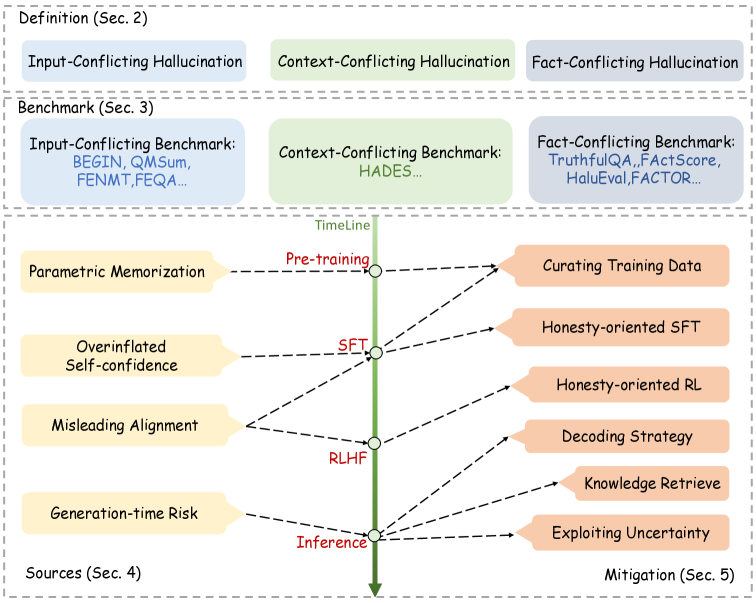
Organization of the survey paper, mapping out the lifecycle of LLMs and where hallucinations can be introduced and addressed
Evaluation Highlights
- The paper is a survey and does not propose a new model or report novel experimental results; it aggregates existing benchmarks.
- Provides a taxonomy of evaluation benchmarks and analyzes existing approaches for mitigation.
- Discusses unique challenges posed by massive training data, versatility, and error imperceptibility in LLMs.
Breakthrough Assessment
7/10
A timely and comprehensive survey that clarifies definitions and categorizations in a rapidly evolving field, though it aggregates existing knowledge rather than proposing a new technical method.