📝 Paper Summary
Hallucination mitigation
Training data composition
Hallucination rates in language models are statistically lower-bounded by the prevalence of rare facts (monofacts) minus model miscalibration, and can be reduced by deliberately injecting miscalibration via repetitive training on small data subsets.
Core Problem
Language models hallucinate because they are statistically bound to do so when training data contains many rare facts (monofacts) and the model is perfectly calibrated.
Why it matters:
- Standard deduplication strategies may inadvertently increase hallucination by removing necessary redundancy that helps models learn rare facts
- Existing post-hoc interventions (like steering vectors) address symptoms rather than the fundamental statistical causes of hallucination
- High-stakes applications (legal, medical) require strict adherence to facts, but new knowledge acquisition often compromises generation fidelity
Concrete Example:
A model might confidently state 'John Smith was born in Seattle in 1982' (a fabrication) because it has seen 'John Smith' only once in training (a monofact) and is calibrated to spread probability mass, whereas a model forced to be overconfident on specific training examples would stick to the known fact.
Key Novelty
Hallucination Control via Data Frequency Manipulation
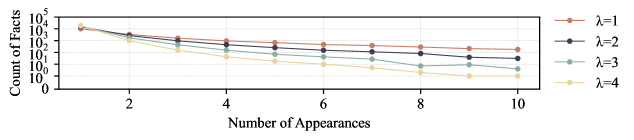
- Empirically validates the 'Kalai-Vempala bound', showing hallucination correlates with the rate of facts seen exactly once (monofacts) minus calibration error
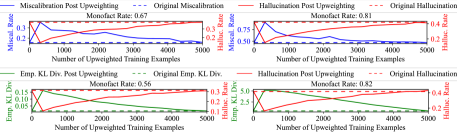
- Introduces 'selective upweighting': deliberately repeating a small subset (e.g., 5%) of training data to inject miscalibration, which forces the model to be overconfident on known facts and reduces hallucination
- Demonstrates that sampling training data from heavy-tailed Pareto distributions (rather than uniform or Gaussian) naturally reduces rare facts and improves reliability
Architecture
The Selective Upweighting algorithm flow
Evaluation Highlights
- Reduces hallucination rates by up to 40% using selective upweighting without sacrificing accuracy
- Selective upweighting works by repeating as little as 5% of training examples during fine-tuning
- Establish a near-linear positive relationship between monofact rate (0% to 100%) and hallucination rate (climbing from ~0% to ~50%) in controlled n-gram settings
Breakthrough Assessment
8/10
Provides the first empirical validation of the Kalai-Vempala theoretical bound and offers a counter-intuitive, practical solution (intentional miscalibration/repetition) that challenges standard deduplication norms.